In the previous post, we have seen how Vagrant can be used to define, create and destroy KVM virtual machines. Today, we will dig a bit deeper into the objects managed by the libvirt library and learn how to create virtual machines using the libvirt toolkit directly
Creating a volume
When creating a virtual machine, you need to supply a volume which will be attached to the machine, either as a bootable root partition or as an additional device. In the libvirt object model, volumes are objects with a lifecycle independent of a virtual machine. Let us take a closer look at how volumes are defined and managed by libvirt.
At the end of the day, a volume which is attached to a virtual machine is linked to some physical storage – usually a file, i.e. a disk image – on the host on which KVM is running. These physical file locations are called target in the libvirt terminology. To organize the storage available for volume targets, libvirt uses the concept of a storage pool. Essentially, a storage pool is some physical disk space which is reserved for libvirt and used to create and store volumes.
Libvirt is able to manage different types of storage pools. The most straightforward type of storage pool is a directory pool. In this case, the storage available for the pool is simply a directory, and each volume in the pool is a disk image stored in this directory. Other, more advanced pool types include pools that utilize storage provided by an NFS server or an iSCSI server, LVM volume groups, entire physical disks or IP storage like Ceph and Gluster.
When libvirt is initially installed, a default storage pool is automatically created. To list all available storage pools and get some information on the default pool, use the commands
Here we see that the default pool is of type “directory” and its target (i.e. location on the host file system) is /var/lib/libvirt/images
Let us now create an image in this pool. There are several ways to do this. In our case, we will first download a disk image and then upload this image into the pool, which will essentially create a copy of the image inside the pool directory and thus under libvirts control. For our tests, we will use the Cirros image, as it has a password enabled by default and is very small. To obtain a copy, run the commands
It happened to me several times that the download was corrupted, so it is a good idea to check the integrity of the image using the MD5 checksums provided here. For our image, the MD5 checksum (which you can verify using md5sum cirros-0.4.0-x86_64-disk.qcow2) should be 443b7623e27ecf03dc9e01ee93f67afe.
Now let us import this image into the default pool. First, we use the qemu-img tool to figure out the size of the image, and then we use virsh vol-create-as to create a volume in the default pool which is large enough to hold our image.
When this command completes, we can verify that a new disk image has been created in /var/lib/libvirt/images.
ls -l /var/lib/libvirt/images
virsh vol-list --pool=default
sudo qemu-img info /var/lib/libvirt/images/cirros-image.qcow2
virsh vol-dumpxml cirros-image.qcow2 --pool=default
This image is now logically still empty, but we can now perform the actual upload which will copy the contents of our downloaded image into the libvirt volume
The next thing that we need to spin up a useful virtual machine is a network. To create a network, we use a slightly different approach. In libvirt, every object is defined and represented by an XML structure (placed in a subdirectory of /etc/libvirt). We have already seen some of these XML structures in this and the previous post. If you want full control over each attribute of a libvirt managed object, you can also create them directly from a corresponding XML structure. Let us see how this works for a network. First, we create an XML file with a network definition – use this link for a full description of the structure of the XML file.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Here we define a new virtual network called test-network. This network has NAT’ing enabled, which implies that libvirt will create iptables rules to masquerade outgoing traffic so that any VM that we attach to this network later will be able to reach the public network. We also instruct libvirt to bring up a virtual Linux bridge virbr-test to implement this network on the host. Finally, we specify a CIDR for our network and ask libvirt to start a DHCP server listening on this network that will hand out leases for a specific range of IP address.
Store this XML structure in a file /tmp/test-network.xml and then use it to create a network as follows.
You can now inspect the created bridge, iptables rule and DNS processes by running
sudo iptables -S -t nat
brctl show virbr-test
ip addr show dev virbr-test
ps ax | grep "dnsmasq"
sudo cat /var/lib/libvirt/dnsmasq/test-network.conf
Looking at all this, we find that libvirt will start a dnsmasq process which is listening on the virbr-test bridge and managing the IP range that we specify. When we start a virtual machine later on, this machine will also be attached to the bridge using a TUN device, so that we have the following picture.
Note that the IP range assigned to the network should not overlap with the IP range of any other libvirt virtual network (or any other virtual network on your host created by e.g. Docker or VirtualBox)
Bring up a machine
We are now ready to start a machine which is attached to our previously defined network and volume (and actually booting from this volume). To create a virtual machine – called a domain in libvirt – we again have several options. We could use the graphical virt-manager or, similar to a network, could prepare an XML file with a domain definition and use virsh create to create a domain from that. A slightly more convenient method is to use the virt-install tool which is part of the virt-manager project. Here is the command that we need to create a new domain called test-instance using our previously created image and network.
Let us quickly go through some of the parameters that we use. First, we give the instance a name, define the amount of RAM that we allocate and the number of vCPUs that the machine will have. With the import flag, we instruct virt-install to boot from the first provided disk (alternatively, virt-install has an option to boot from an image defined using the –location directive, which can point to a disk image or a remote location).
In the next line, we specify the first (and only) disk that we want to attach. Note that we refer to the logical name of the volume, in the form pool/volume name. We also tell libvirt which format our image has and that it should use the virtio driver to set up the virtual storage controller in our machine.
In the next line, we attach our machine to the test network. The CirrOS image that we use contains a startup script which will use DHCP to get a lease, so it will get a lease from the DHCP server that libvirt has attached to this network. Finally, in the last line, we ask libvirt to start a VNC server which will reflect the virtual graphics device, mouse and keyboard of the machine, using the same keymap as on the local machine, and to not start a VNC console automatically.
To verify the startup process, you have several options. First, you can use the virt-viewer tool which will display a list of all running machines and allow you to connect via VNC. Alternatively, you can use virt-manager as we have done it in the last post, or use
virt console test-instance
to connect to a text console and log in from there (the user is cirros, the password is gocubsgo). Once the machine is up, you can also SSH into it:
When playing with this, you will find that it takes a long time for the machine to boot. The reason is that the image we use is meant to be used as a lean test image in a cloud platform and therefore tries to query metadata from a metadata server which, in our case, is not present. There are ways to handle this, we get back to this in a later post.
Using backing stores
In the setup we have used so far, every machine has a disk image serving as its virtual hard disk, and all these disk images are maintained independently. Obviously, if you are running a larger number of guests on a physical host, this tends to consume a lot of disk space. To optimize this setup, libvirt allows us to use overlay images. An overlay image is an image which is backed by another images and uses a copy-on-write approach so that we only have to store the data which is actually changed compared to the underlying image.
To try this out, let us first delete our machine again.
Here we create a new image test-image.qcow2 (second parameter) of size 20 GB (third parameter in the default pool (first parameter) in qcow2 format (fourth parameter). The additional parameters instruct libvirt to set this image up as an overlay image, backed by our existing CirrOS image. When you now inspect the created image using
sudo ls -l /var/lib/libvirt/images/test-image.qcow2
sudo qemu-img info /var/lib/libvirt/images/test-image.qcow2
you will see a reference to the backing image in the output as well. Make sure that the format of the backing image is correct (apparently libvirt cannot autodetect this, and I had problem when not specifying the format explicitly). Also note that the physical file behind the image is still very small, as it only needs to capture some metadata and changed blocks, and we have not made any changes yet. We can now again bring up a virtual machine, this time using the newly created overlay image.
This completes our short tour through the libvirt toolset and related tools. There are a couple of features that libvirt offers that we have not yet looked at (including things like network filters or snapshots), but I hope that with the overview given in this and the previous post, you will find your way through the available documentation on libvirt.org.
We have seen that to create virtual machines, we have several options, including CLI tools like virsh and virt-install suitable for scripting. Thus libvirt is a good candidate if you want to automate the setup of virtual environments. Being a huge fan of Ansible, I did of course also play with Ansible to see how we can use it to manage virtual machines, which will be the content of my next post.
When you want to build a volume service for a cloud platform, you need to find a way to quickly create and remove block devices on your compute nodes. We could of course use loopback devices for this, but this is slow, as every operation goes through the file system. A logical volume manager might be a better alternative. Today, we will investigate the logical volume manager that Cinder actually uses – Linux LVM2.
The Linux logical volume manager – some basic terms
In this section, we will briefly explain some of the key concepts of the Linux logical volume manager (LVM2). First, there are of course physical devices. These are ordinary block devices that the LVM will completely manage, or partitions on block devices. Technically, even though these devices are called physical devices in this context, these devices can themselves be virtual devices, which happens for instance if you run LVM on top of a software RAID. Logically,
the physical devices are divided further into physical extents. An extent the smallest unit of storage that LVM manages.
On the second layer, LVM now bundles one or several physical devices into a volume group. On top of that volume group, you can now create logical devices. These logical devices can be thought of as being divided into logical extents. LVM maps these logical extents to physical extents of the underlying volume group. Thus, a logical device is essentially a collection of physical extents of the underlying volume group which are presented to a user as a logical block device. On top of these logical volumes, you can then create file systems as usual.
Why would you want to do this? One obvious advantage is again based on the idea of pooling. A logical volume essentially pools the storage capacity of the underlying physical devices and LVM can dynamically assign space to logical devices. If a logical device starts to fill up while other logical devices are still mostly empty, an administrator can simply reallocate capacity between the logical devices without having to change the physical configuration of the system.
Another use case is virtualization. Given that there is sufficiently storage in your logical volume group, you can dynamically create new logical devices with a simple command, which can for instance be used to automatically provision volumes for cloud instances – this is how Cinder leverages the LVM as we will see later on.
Looking at this, you might be reminded of a RAID controller which also manages physical devices and presents their capacity as virtual RAID volumes. It is important to understand that LVM is not (primarily) a RAID manager. In fact, newer versions of LVM also offer RAID functionality (more on this below), but this it not its primary purpose.
Another useful functionality that LVM offers is a snapshot. When you create a snapshot, LVM will not simply create a physical copy. Instead, it will start to mark blocks which are changed after the snapshot has been taken as changed and only copy those blocks to a different location. This makes using the snapshot functionality very efficient.
Lab12: installing and using LVM
Let us now try to see how LVM works in practice. First, we need a machine with a couple of unused block devices. As it is unlikely that you have some spare disks lying around under your desk, we will again use a virtual machine for that purpose. So bring up our test machine and log into it using the following commands (assuming that you have gone through the basic setup steps in the the first post in this series).
git clone https://github.com/christianb93/openstack-labs
cd openstack-labs/Lab12
vagrant up
vagrant ssh box
When you now run lsblk inside the machine, you should see two additional devices /dev/sdc and /dev/sdd which are both unmounted and have a capacity of 5 GB each.
As a first step, let us now prepare these physical volumes for use with LVM. This is done using the pvcreate utility. WARNING: if you accidentally run this outside of the VM, it will render the device unusable!
sudo pvcreate /dev/sdc
sudo pvcreate /dev/sdd
What is this command actually doing? To understand this, let us first use pvscan to print a list of all physical volumes on the system which LVM knows.
sudo pvscan -u
You will see a list of two volumes, and after each volume, LVM will print a UUID for this volume. Now let us see what LVM has actually written on the volume.
In the output, you will see that LVM has written some sort of signature onto the device, containing some binary information and the UUID of the device. In fact, this is how LVM stores state and is able to recognize a volume even if it has been moved to a different point in /dev.
Now we can build our first volume group. For that purpose, we use the command vgcreate and specify the name of the volume group and a list of physical devices that the volume group should contain.
sudo vgcreate test_vg /dev/sdc /dev/sdd
If you now repeat the dump above, you will see that LVM has again written some additional data on the device, we find the name of the newly created volume group and even a JSON representation of the physical volumes in the volume group.
Let us now print out a bit more information on the system using the lvm shell. So run
sudo lvm
to start the shell and then type fullreport to get a description of the current configuration. It is instructive to play a bit with the shell, use help to get a list of available commands and exit to exit the shell when you are done.
Finally, it is now time to create a few logical volumes. Our entire volume group has 10 GB available. We will create three logical volumes which in total consume 6 GB.
for i in {1..3}; do
sudo lvcreate \
--size 2G \
test_vg \
--type linear \
--name lv0$i
done
sudo lvscan
The last command will print a list of all logical volumes on the system and should display the three logical volumes that we have just created. If you now again create a full report using lvm, you will find these three devices and a table that indicates how the logical extends are distributed across the various physical devices.
Behind the scenes, LVM uses the Linux device mapper kernel module, and in fact, each device that we create is displayed in the /dev tree at three different points. First, LVM exposes the logical volumes at a location built according to the scheme
/dev/volume group name/logical volume name
In our example, the first volume, for instance, is located at /dev/test_vg/lv01. This, however, is only a link to the device /dev/dm-0, indicating that it is created by the device mapper. Finally, a second link is created in /dev/mapper.
The LVM metadata daemon
We have said above that LVM stores its state on the physical devices. This, however, is only a part of the story, as it would imply that whenever we use one of the tools introduced above, we have to scan all devices, which is slow and might interfere with other read or write access to the device.
For that reason, LVM comes with a metadata daemon, running as lvmetad in the background as a systemctl service. This daemon maintains a cache of the LVM metadata that a command like lvscan will typically use (you can see this if you try to run such a command as non-root, which will cause an error message while the tool is trying to connect to the daemon via a Unix domain socket).
The metadata daemon is also involved when devices are added (hotplug), removed, or changed. If, for example, a physical volume comes up, a Linux kernel mechanism known as udev informs LVM about this event, and when a volume group is complete, all logical volumes based on it are automatically activated (see the comment on use_lvmetad in the configuration file /etc/lvm/lvm.conf).
It is interesting to take a look at the udev ruleset that LVM creates for this purpose (you will find these rules in the LVM-related files in /lib/udev/rules.d, in my distribution, these are the files with the numbers 56 and 69). In the rules file 69-lvm-metad.rules, for instance, you will find a rule that invokes (via systemd dependencies) a pvscan every time a physical device is added which will update the cache maintained by the metadata daemon (see also this man-page for a bit more background on the various options that you have to activate logical LVM devices at boot-time).
However, there is one problem with this type of scan that should be mentioned. Suppose, in our scenario, someone exports our logical device /dev/test_vg/lv01 using a block device level tool like iSCSI. A client then consumes the device and it appears inside the file system of the client as, say, /dev/sdc. On the client, an administrator now decides to also use LVM and sets up this device as a physical volume.
LVM on the client will now write a signature into /dev/sdc. This write will go through the iSCSI connection and the signature will be written to /dev/test_vg/lv01 on the server. If now LVM on the server scans the devices for signatures the next time, this signature will also appear on the server, and LVM will be confused and believe that a new physical device has been added.
To avoid this sort of issues, the LVM configuration file /etc/lvm/lvm.conf contains an option which allow us to add a filter to the scan, so that only devices which are matching that filter are scanned for PV signatures. We will need this when we later install Cinder which uses LVM to create logical volumes for virtual machines on the fly.
LVM snapshots
Let us now explore a very useful feature of LVM – efficiently creating COW (copy-on-write) snapshots.
The idea behind a copy-on-write snapshot is easily explained. Suppose you have a logical volume that contains, say, 100 extends. You now want to create a snapshot, i.e. a copy of that volume at a given point in time. The naive approach would be to go through all extents and to create an exact copy for each of them. This, however, has two major disadvantages – it is very time consuming and it requires a lot of additional disk space.
When using copy-on-write, you would proceed differently. First, you would create a list of all extents. Then, you would start to monitor write activities on the original volume. As soon as an extent is about to be changed, you would mark it as changed and create a copy of that extent to preserve its content. For those extents, however, that have not yet changed since the snapshot has been created, you would not create a copy, but refer to the original content when someone tries to read from the snapshot, similar to a file system link.
Thus when a read is done on the snapshot, you would first check your list whether the extent has been changed. If yes, the copied extent is used. If no, the read is redirected to the original extent. This procedure is very fast, as we do not have to copy around all the data at the time when the snapshot is created, and uses space efficiently, as the capacity needed for the snapshot does not depend on the total size of the original volume, but on the volume of change.
Let us try this out. For this exercise, we will use the logical volume /dev/test_vg/lv01 that we have created earlier. First, use fdisk to create a partition on this volume, then create a file system and a mount point and mount this volume under /mnt/lv/ . Note that – which confused me quite a bit when trying this – the device belonging to the partition will NOT show in in /dev/test_vg, but in /dev/mapper/, i.e. the path to the partition that you have to use with mkfs is /dev/mapper/test_vg-lv01p1. Then create a file in in the mounted directory.
Note that we need one execution of partprobe to force the kernel to read the partition table on the logical device which will create the device node for the partition. We also sync the filesystem to make sure that the write goes through to the block device level.
Next, we will create a snapshot. This done using the lvcreate command as follows.
There are two things that should be noted here. First, we explicitly specify a size of the snapshot which is much smaller than the original volume. At a later point in time, when a lot of data has been written, we might have to extend the volume manually, or we can make use of LVMs auto-extension feature for snapshots (see the comments for the parameter snapshot_autoextend_threshold in /etc/lvm/lvm.conf and the man page of dmeventd which needs to be running to make this work for details). Second, we ask LVM to create a read-only snapshot – LVM can also create read-write snapshots, which in fact is the default, but we will not need this here.
If you now run lvs to get a list of all logical volumes, you will see that a new snapshot volume has been created which is linked (via the “origin” field) to the original volume. Let us now mount the snapshot as well, change the data in our test file and then verify that the file in the snapshot is unchanged.
sudo partprobe /dev/mapper/test_vg-snap01
sudo mkdir -p /mnt/snap
sudo mount /dev/mapper/test_vg-snap01p1 /mnt/snap
echo "2" | sudo tee /mnt/lv/test
sudo cat /mnt/snap/test
In a real world scenario, we could now use the mounted snapshot as a backup, copy the files that we want to restore then eventually remove the snapshot volume again. Alternatively, we can restore the entire snapshot by merging it back into the original volume, which will reset the original volume to the state in which it was when the snapshot was taken. This is done using the command lvconvert.
sudo lvconvert \
--mergesnapshot \
test_vg/snap01
When you run this, the merge will be scheduled, but it will only be executed once the devices are re-activated. At this point, I got a bit into trouble. To understand the problem, let us first umount all mount points and then try to deactivate the original volume.
But wait, there is a problem – when you simply run this command, you will get an error message informing you that the logical volume “is in use by another device”. It took me some time and this blog post describing a similar problem to figure out what goes wrong. To diagnose the problem, we can find the links to our device in the /sys filesystem. First, find the major and minor device number of the logical volume using dmsetup info – in my example, this gave me 253:0. Then, navigate to /sys/dev/block. Here, you will find a subdirectory for each major-minor device number representing the existing devices. Navigate into the one for the combination you just noted and check the holders subdirectory to see who is holding a reference to the device. You will find that the entry in /dev/mapper representing the partition that showed up after running partprobe causes the problem! So we can use
After a few seconds, the snapshot should disappear from /dev/mapper, and sudo lvs -a should now longer show the snapshot, indicating that the merge is complete. When you now mount the original volume again and check the test file
sudo partprobe /dev/mapper/test_vg-lv01
sudo mount /dev/mapper/test_vg-lv01p1 /mnt/lv
sudo cat /mnt/lv/test
you should see the original content (1) again.
Note that it is not possible to detach a snapshot from its origin (there is a switch –splitsnapshot for lvconvert, but this does only split of the changed extents, i.e. the COW part, and is primarily intended to be able to zero out those extents before returning them into the volume group pool by removing the snapshot). A snapshot will always require a reference to the original volume.
To understand Cinder, the block device component of OpenStack, you will need to be familiar with some terms that originate from the world of data center networks like SCSI, SAN, LUN and so forth. In this post, we will take a short look at these topics to be prepared for our upcoming installation and configuration of Cinder.
Storage networks
In the early days of computing, when persistent mass storage was introduced, storage devices where typically directly attached to a server, similar to the hard disk in your PC or laptop computer which is sitting in same enclosure as your motherboard and directly connected to it. In order to communicate with such a storage device, there would usually be some sort of controller on the motherboard which would use some low-level protocol to talk to a controller on the storage device.
A protocol to achieve this which is (still) very popular in the world of Intel PCs is the SATA protocol, but this is by far not the only one. In most enterprise storage solutions, another protocol called SCSI (small computer system interface) is still dominating, which was originally also used in the consumer market by companies like Apple. Let us quickly summarize some terms that are relevant when dealing with SCSI based devices.
First, every device on a SCSI bus has a SCSI ID. As a typical SCSI storage device may expose more than one disk, these disks are represented by logical unit numbers (LUNs). Generally speaking, every object that can receive a SCSI command is a logical unit (there are also logical units that do not represent actuals disks, but controllers). Each SCSI device can encompass more than one LUN. A SCSI device could, for instance, be a RAID array that exposes two logical disks, and each of these disks would then be addressable as a separate LUN.
When devices communicate over the SCSI bus, one of them acts as initiator and one of them acts as target. If, for instance, a host controller wants to read data from a SCSI hard disk, the host controller is the initiator, and the controller of the hard disk is the target. The initiator can send commands like “read a block” to the target, and the target will reply with data and / or a status code.
Now imagine a data center in which there is a large number of servers, each of which being equipped with a direct attached storage device.
The servers might be connected by a network, but each disk (or other storage device like tape or a removable media drive) is only connected to one server. This setup is simple, but has a couple of drawbacks. First, if there is some space available on a disk, it cannot easily be made available for other servers, so that the overall utilization is low. Second, topics like availability, redundancy, backups, proper cooling and so forth have to be done individually for each server. And, last but not least, physical maintenance can be difficult if the servers are distributed over several locations.
For those reasons, an alternative architecture has evolved over time, in which storage capacity is centralized. Instead of having one disk attached to each server, most of the storage capacity is moved into a central storage appliance. This appliance is then connected to each server via a (typically dedicated) network, hence the term SAN – storage attached network that describes this sort of architecture (often, each server would still have a small disk as a primary partition for the operating system and booting, but not even this is actually required).
Of course, the storage in such a scenario is typically not just an ordinary disk, but an entire array of disks, combined into a RAID array for better performance and redundancy, and often equipped with some additional capabilities like de-duplication, instant copy, a management interface and so forth.
Very often, storage networks are not based on Ethernet and IP, but on the FibreChannel network protocol stack. However, there is also a protocol called iSCSI which can be used to run SCSI on top of TCP/IP, so that a SAN can be leveraging existing IP-based networks and technologies – more on this in the next section.
Finally, there is a third possible architecture (which we do not discuss in detail in this post), which is becoming increasingly popular in the context of cloud and container platforms – distributed storage systems. With this approach, storage is still separated from the compute capacity and connected using a network, but instead of having a small number of large storage appliances that pool the available storage capacity, these solutions take a comparatively large number of smaller nodes, often commodity hardware, which distribute and replicate data to form a large, highly available virtual storage system. Examples for this type of solutions are the HDFS file system used by Hadoop, Ceph or GlusterFS.
The iSCSI protocol
Let us now take a closer look at the iSCSI protocol. This protocol, standardized in RFC 7143 (which is replacing earlier RFCs), is a transport protocol for SCSI which can be used to build storage networks utilizing SCSI capable devices based on an underlying IP network.
In an iSCSI setup, an iSCSI initiator talks to an iSCSI target using one or more TCP/IP connections. The combination of all active sessions between an initiator and a target is called a session, and is roughly equivalent to what is known as I_T nexus (initiator – target nexus) in the SCSI protocol. Each session is identified by a session ID, and each connection within a session has a connection ID. Logically, a session describes an ongoing communication between an initiator and a target, but the traffic can be spread across several TCP/IP connections to support redundancy and failover.
Both, the initiator and the target, are identified by a unique name. The RFC defines several ways to build iSCSI names. One approach is to use a combination of
The qualifier iqn to mark the name as an iSCSI qualified name
a (reversed) domain name which is supposed to be owned by whoever assigns the name so that the resulting name will be unique
a date (yyyy-mm) between the leading iqn and the domain name which is a date at which the domain ownership was valid (to be able to deal with changing domain name ownerships)
A colon followed by a postfix to make the name unique within the domain
As I own the domain leftasexercise.com since 2018, an example for a iSCSI name that I could use would be
iqn.2018-12.com.leftasexercise:foo
To establish a session, an initiator has to perform a login operation on the iSCSI target. During login, features are negotiated and authentication is performed. The standard allows for the use of Kerberos, CHAP and Secure remote password (SRP), but the only protocol that all implementations must support is CHAP (more on this below when we actually try this out). Once a login has completed, the session enters the full feature phase. A session can also be a discovery session in which only the functionality to discover valid target names is available to the initiator.
Note that the iSCSI protocol decouples the iSCSI node name from the network name. The node names that we have discussed above do typically not resolve to an IP address under which a target would be reachable. Instead, the network connection layer is modeled by the concept of a network portal. For a server, the network portal is the combination of an IP address and a port number (which defaults to 3260). On the client side, a network portal is simply the IP address. Thus there is an n-m relation between portals and nodes (targets and initiators).
Suppose, for example, that we are running a software (some sort of daemon) that can emulate one or more iSCSI targets (as we will do it below). Suppose further that this daemon is listening on two different IP addresses on the server on which it is running. Then, each IP address would be one portal. Our daemon could manage an unlimited number of targets, each of which in turn offers one or more LUNs to initiators. Depending on the configuration, each target could be reachable via each IP address, i.e. portal. So our setup would be as follows.
Portals can also be combined into portal groups, so that different connections within one session can be run across different portals in the same group.
Lab11: implementing iSCSI nodes on Linux
Of course, Linux is able to act as an iSCSI initiator or target, and there are several implementations for the required functionality available.
One tool which we will use in this lab is Open-iSCSI, which is an iSCSI initiator consisting of several kernel drivers and a user-space part. To run an iSCSI target, Linux also offers several options like the LIO iSCSI target or the Linux SCSI target framework TGT. As it is also used by Cinder, we will play with TGT today.
As usual, we will run our lab on virtual machines managed by Vagrant. To start the environment, enter the following commands from a terminal on your lab PC.
git clone https://github.com/christianb93/openstack-labs
cd openstack-labs/Lab11
vagrant up
This will bring up two virtual machines called client and server. Both machines will be connected to a virtual network, with the client IP address being 192.168.1.12 and the server IP address being 192.168.1.11. On the server, our Vagrantfile attaches an additional disk to the virtual SCSI controller of the VirtualBox instance, which is visible from the OS level as /dev/sdc. You can use lsscsi, lsblk -O or blockdev --report to get a list of the SCSI devices attached to both client and server.
Now let us start the configuration of TGT on the server. There are two ways to do this. We will use the tool tgtadm to submit our commands one by one. Alternatively, there is also tgt-admin which is a Perl script that translates a configuration (typically stored in /etc/tgt/target.conf) into calls to tgtadm which makes it easier to re-create a configuration at boot time.
The target daemon itself is started by systemctl at boot time and is both listening on port 3260 on all interfaces and on a Unix domain socket in /var/run/tgt/. This socket is called the control port and used by the tgtadm tool to talk to the daemon.
TGT is able to use different drivers to send and receive SCSI commands. In addition to iSCSI, the second protocol currently supported is iSER which is a transport protocol for SCSI using remote direct memory access (RDMA). So most tgtadm commands start with the switch –lld iscsi to select the iSCSI driver. Next, there is typically a switch that indicates the type of object that the command operates on, plus some operation like new, delete and so forth. To see this in action, let us first create a new target and then list all existing targets on the server.
Here the target name is the iSCSI node name that our target will receive, and the target ID (tid) is the TGT internal ID under which the target will be managed. From the output of the last command, we see that the target is existing and ready, but there is no active session (I_T nexus) yet and there is only one LUN, which is a default LUN added by TGT automatically (in fact, the SCSI-3 standard mandates that there is always a LUN 0 and that (SCSI Architecture model, section 4.9.2), All SCSI devices shall accept LUN 0 as a valid address. For SCSI devices that support the hierarchical addressing model the LUN 0 shall be the logical unit that an application client addresses to determine information about the SCSI target device and the logical units contained within the SCSI target device.
Now let us create an actual logical unit and add it to our target. The tgt daemon is able to expose either an entire device as a SCSI LUN or a flat file. We will create two LUNs, to try out both alternatives. We start by adding our raw block device /dev/sdc to the newly created target.
Note that the backing store needs to be an absolute path name, otherwise the request will fail (which makes sense, as it needs to be evaluated by the target daemon).
When we now display our target once more, we see that two LUNs have been added, LUN 1 corresponding to /dev/sdc and LUN 2 corresponding to our flat file. To make this target usable for a client, however, one last step is missing – we need to populate the access control list (ACL) of the target, which determines which initiators are permitted to access the target. We can specify either an IP address range (CIDR range), an individual IP address or the keyword ALL. Alternatively, we could also allow access for a specific initiator, identified by its iSCSI name. Here we allow access from our private subnet.
Here we SSH into the client and use the Open-iSCSI command line client to run a discovery session against the portal 192.168.1.11:3260, asking the server to provide a list of all targets available on that portal. The output will be a list of all targets (only one in our case), i.e. in our case we expect
We see the portal (IP address and portal), the portal group, and the fully qualified name of the target. We can now login to this target, which will actually start a session and make our LUNs available on the client.
Note that Open-iSCSI uses the term node differently from the iSCSI RFC to refer to the actual server, not to an initiator or target. Let us now print some details on the active sessions and our block devices.
sudo iscsiadm \
-m session \
-P 3
lsblk
We find that the login has created two new block devices on our client machine, /dev/sdc and /dev/sdd. These two devices correspond to the two LUNs that we export. We can now handle these devices as any other block device. To try this out, let us partition /dev/sdc, add a file system (BE CAREFUL – if you accidentally run this on your PC instead of in the virtual machine, you know what the consequences will be – loss of all data on one of your hard drives!), mount it, add some test file and unmount again.
sudo fdisk /dev/sdc
# Enter n, p and confirm the defaults, then type w to write partition table
sudo mkfs -t ext4 /dev/sdc1
sudo mkdir -p /mnt/scsi
sudo mount /dev/sdc1 /mnt/scsi
echo "test" | sudo tee -a /mnt/scsi/test
sudo umount /mnt/scsi
Once this has been done, let us verify that the write operation did really go all the way to the server. We first close our session on the client again
and then mount our block device on the server and see what is contains. To make the OS on the server aware of the changed partition table, you will have to run fdisk on /dev/sd once and exit immediately again.
vagrant ssh server
sudo fdisk /dev/sdc
# hit p to print table and exit
sudo mkdir -p /mnt/scsi
sudo mount /dev/sdc1 /mnt/scsi
You should now see the newly written file, demonstrating that we did really write to the disk attached to our server.
CHAP authentication with iSCSI
As mentioned above, the iSCSI standard mandates CHAP as the only authentication protocol that all implementations should understand. Let us now modify our setup and add authentication to our target. First, we need to create a user on the server. This is again done using tgtadm
If you now switch back to the client and try to login again, this will fail, as we did not yet provide any credentials. How do we tell Open-iSCSI to use credentials for this node?
It turns out that Open-iSCSI maintains a database of known nodes, which is stored as a hierarchy of flat files in /etc/iscsi/nodes. There is one file for each combination of portal and target, which also stores information on the authentication method required for a specific target. We could update these files manually, but we can also use the “update” functionality of iscsiadm to do this. For our target, we have to set three fields – the authentication method, the username and the password. Here are the commands to do this.
If you repeat the login attempt now, the login should work again and the virtual block devices should again be visible.
There is much more that we could add – for instance, pass-through devices, removable media, virtual tapes, creating new portals and adding them to targets or using the iSNS naming protocol. However, this is not a series on storage technology, but a series on OpenStack. In the next post, we will therefore investigate another core technology used by OpenStack Cinder – the Linux logical volume manager LVM.
Over time, I have worked with a couple of different commercial cloud platforms like AWS, DigitalOcean, GCP, Paperspace or Packet.net. Even though these platforms are rather well documented, there comes a point where you would like to have more insights into the inner workings of a cloud platform. Unfortunately, not too many of use have permission to walk into a Google data center and dive into their setup, but we can install and study one of the most relevant open source cloud platforms – OpenStack.
What is OpenStack?
OpenStack is an open source project (or, more precisely, a collection of projects) aiming at providing a state-of-the-art cloud platform. Essentially, OpenStack contains everything that you need to convert a set of physical servers into a cloud. There are components that interact with a hypervisor like KVM to build and run virtual machines, components to define and operate virtual networks and virtual storage, components to maintain images, a set of APIs to operate your cloud and a web-based graphical user interface.
OpenStack has been launched by Rackspace and NASA in 2010, but is currently supported by a large number of organisations. Some commercially supported OpenStack distributions are available, like RedHat OpenStack, Lenovo Thinkcloud or VMWare Integrated OpenStack. The software is written in Python, which for me was one of the reasons why I have decided to dive into OpenStack instead of one of the other open source cloud platforms like OpenNebula or Apache Cloudstack.
New releases of OpenStack are published every six months. This and the following posts use the Stein release from April 2019 and Ubuntu 18.04 Bionic as the underlying operating system.
OpenStack architecture basics
OpenStack is composed of a large number of components and services which initially can be a bit confusing. However, a minimal OpenStack installation only requires a hand-full of services which are displayed in the diagram below.
At the lowest layer, there are a couple of components that are used by OpenStack but provided by other open source projects. First, as OpenStack is written in Python, it uses the WSGI specification to expose its APIs. Some services come with their own WSGI container, others use Apache2 for that purpose.
Then, of course, OpenStack needs to persist the state of instances, networks and so forth somewhere and therefore relies on a relational database which by default is MariaDB (but could also be PostgreSQL, and in fact, every database that works with SQLAlchemy should do). Next, the different components of an OpenStack service communicate with each other via message queues provided by RabbitMQ and store data temporarily in Memcached. And finally, there is of course the hypervisor which by default is KVM.
On top of these infrastructure components, there are OpenStack services that lay the foundations for the compute, storage and network components. The first of these services is Keystone which provides identity management and a service catalog. All end user and all other services are registered as user with Keystone, and Keystone is handing out tokens so that these users can access the APIs of the various OpenStack services.
Then, there is the Glance image service. Glance allows an administrator to import OS images for use with virtual machines in the cloud, similar to a Docker registry for Docker images. The third of these intermediate services is the placement service which used to be a part of Nova and is providing information on available and used resources so that OpenStack can decide where a virtual machine should be scheduled.
On the upper layer, we have the services that make up the heart of OpenStack. Nova is the compute service, responsible for interacting with the hypervisor to bring up and maintain virtual machines. Neutron is creating virtual networks so that these virtual machines can talk to each other and the outside world. And finally, Cinder (which is not absolutely needed in a minimum installation) is providing block storage.
There are a couple of services that we have not represented in this picture, like the GUI Horizon or the bare-metal service Ironic. We will not discuss Ironic in this series and we will set up Horizon, but mostly use the API.
OpenStack offers quite a bit of flexibility as to how these services are distributed among physical nodes. We can not only distribute these services, but can even split individual services and distribute them across several physical nodes. Neutron, for instance, consists of a server and several agents, and typically these agents are installed on each compute node. Over time, we will look into more complex setups, but for our first steps, we will use a setup where there is a single controller node holding most of the Nova services and one or more compute nodes on which parts of the Nova service and the Neutron service are running.
In a later lab, we will build up an additional network host that runs a part of the Neutron network services, to demonstrate how this works.
Organisation of the upcoming series
In the remainder of this series, I will walk you through the installation of OpenStack in a virtual environment. But the main purpose of this exercise is not to simply have a working installation of OpenStack – if you want this, you could as well use one of the available installation methods like DevStack. Instead, the idea is to understand a bit what is going on behind the scenes – the architecture, the main configuration options, and here and then a little deep-dive into the source code.
To achieve this, we will discuss each service, its overall architecture, some use cases and the configuration steps, starting with the basic setup and ending with the Neutron networking service (on which I will put a certain focus out of interest). To turn this into a hands-on experience, I will guide you through a sequence of labs. In each lab, we will do some exercises and see OpenStack in action. Here is my current plan how the series will be organized.
Octavia: load balancer as-a-service with OpenStack
Moving the entire setup into the cloud – running OpenStack on Packet, GCE or DigitalOcean
As always, the code for this series is available on GitHub. Most of the actual setup will be fully automated using Vagrant and Ansible. We will simulate the individual nodes as virtual machines using VirtualBox, but it should not be difficult to adapt this to the hypervisor of your choice. And finally, the setup is flexible enough to work on a sufficiently well equipped desktop PC as well as in the cloud.
After this general overview, let us now get started. In the next post, we will dive right into our first lab and install the base services that OpenStack needs.
When you are trying to understand virtual networking, container networks, micro segmentation and all this, sooner or later the day will come where you will have to deal with iptables, the built-in Linux firewall mechanism. After evading the confrontation with the full complexity of this remarkable beast for many years, I have recently decided to dive a little deeper into the internals of the Linux networking stack. Today, I will give you an overview of the inner workings of the machinery behind iptables and show you how to use this to build a virtual firewall in a Linux networking namespace.
Netfilter hooks in the Linux kernel
In order to understand how iptables work, we will have to take a short look at a mechanism called netfilter hooks in the Linux networking stack.
Netfilter hooks are points in the Linux networking code at which modules can add their own custom processing. When a packet is travelling up or down through the networking stack and reaches one of these points, it is handed over to the registered modules which can manipulate the packet and, by their return value, can either instruct the core networking code to continue with the processing of the packet or to drop it.
Let us take a closer look at where these netfilter hooks are placed in the kernel. The following diagram is a (simplified) summary of the way that packets take through the Linux IPv4 stack (for those readers who actually want to see this in the Linux kernel code, I have added some of the most relevant Linux kernel functions, referring to v4.2 of the kernel).
A packet coming in from a network device will first reach the pre-routing hook. As the name indicates, this happens before a routing decision is taken. After passing this hook, the kernel will consult its routing tables. If the target IP address is the IP address of a local device, it will flag the packet for local delivery. These packets will now be processed by the input hook before they are handed over to the higher layers, e.g. a socket listening on a port.
If the routing algorithm determines that the packet is not targeted towards a local interface but needs to be forwarded, the path through the kernel is different. These packets will be handled by the forwarding code and pass the forward netfilter hook, followed by the post-routing hook. Then, the packet is sent to the outgoing network interface and leaves the kernel.
Finally, for packets that are locally generated by an application, the kernel first determines the route to the destination. Then, the modules registered for the output hook are invoked, before we also reach the post-routing hook as in the case of forwarding.
Having discussed netfilter hooks in general, let us now turn to iptables. Essentially, iptables is a framework sitting on top of the netfilter hooks which allows you to define rules that are evaluated at each of the hooks and determine the fate of the packet. For each netfilter hook, a set of rules called a chain is processed. Consequently, there is an input chain, an output chain, a pre-routing chain, a post-routing chain and a forward chain. If it also possible to define custom chains to which you can jump from one of the pre-built chains.
Iptables rules are further organized into tables and wired up with the kernel code using netfilter hooks, but not every table registers for every hook, i.e. not every table is represented in every chain. The following diagram shows which chain is present in which table.
It is sometimes stated that iptables chains are contained in tables, but given the discussion of netfilter hooks above, I prefer to think of this a matrix – there are chains and tables, and rules are sitting at the intersections of chains and tables, so that every rule belongs to a table and a chain. To illustrate this, let us look at the processing steps taken by iptables for a packet for a local destination.
Process the rules in the raw table in the pre-routing chain
Process the rules in the mangle table in the pre-routing chain
Process the rules in the nat table in the pre-routing chain
Process the rules in the mangle table in the input chain
Process the rules in the nat table in the input chain
Process the rules in the filter table in the input chain
Thus, rules are evaluated at every point in the above diagram where a white box indicates a non-empty intersection of tables and chains.
Iptables rules
Let us now see how the actual iptables rules are defined. Each rule consists of a match which determines to which packets the rule applies, and a target which determines the action taken on the packet. Some targets are terminating, meaning that the processing of the packet stops at this point, other targets are non-terminating, meaning that a certain action will be taken and processing continues. Here are a few examples of available targets, see the documentation listed in the last section for the full specification.
Action
Description
ACCEPT
Accept the packet, i.e do not apply any further rules within this combination of chain and table and instruct the kernel to let the packet pass
DROP
Drop the packet, i.e. tell the kernel to stop processing of the packet without any further action
REJECT
Tell the kernel to stop processing of the packet and send an ICMP reject message back to the origin of the packet
SNAT
Perform source NATing on the packet, i.e. change the source IP address of the packet, more on this below
DNAT
Destination NATing, i.e. change the destination IP address of the packet, again we will discuss this in a bit more detail below
LOG
Log the packet and continue processing
MARK
Mark the packet, i.e. attach a number which can again be used for matching in a subsequent rule
Note, however, that not every action can be used in every chain, but certain actions are restricted to specific tables or chains
Of course, it might happen that no rule matches. In this case, the default target is chosen, which is also known as the policy for a given table and chain.
As already mentioned above, it is also possible to define custom chains. These chains can be used as a target, which implies that processing will continue with the rules in this chain. From this chain, one can either return explicitly to the original table using the RETURN target, or, otherwise, the processing continues in the original table once all rules in the custom chain have been processed, so this is very similar to a function or subroutine in a high-level language.
Setting up our test lab
After all this theory, let us now see iptables in action and add some simple rules. First, we need to set up our lab. We will simulate a situation where two hosts, called boxA and boxB are connected via a router, as indicated in the following diagram.
We could of course do this using virtual machines, but as a lightweight alternative, we can also use IP namespaces (it is worth mentioning that similar to routing tables, iptables rules are per namespace). Here is a script that will set up this lab on your local machine.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Let us now start playing with this setup a bit. First, let us see what default policies our setup defines. To do this, we need to run the iptables command within one of the namespaces representing the different virtual hosts. Fortunately, ip netns exec offers a very convenient way to do this – you simply pass a network namespace and an arbitrary command, and this command will be executed within the respective namespace. To list the current content of the mangle table in namespace boxA, for instance, you would run
sudo ip netns exec boxA \
iptables -t mangle -L
Here, the switch -t selects the table we want to inspect, and -L is the command to list all rules in this table. The output will probably depend on the Linux distribution that you use. Hopefully, the tables are empty, and the default target (i.e. the policy) for all chains is ACCEPT (no worries if this is not the case, we will fix this further below). Also note that the output of this command will not contain every possible combination of tables and chains, but only those which actually are allowed by the diagram above.
To be able to monitor the incoming and outgoing traffic, we now create our first iptables rule. This rule uses a special target LOG which simply logs the packet so that we can trace the flow through the involved hosts. To add such a rule to the filter table in the OUTPUT chain of boxA, enter
sudo ip netns exec boxA \
iptables -t filter -A OUTPUT \
-j LOG \
--log-prefix "boxA:OUTPUT:filter:" \
--log-level info
Let us briefly through this command to see how it works. First, we use the ip netns exec command to run a command (iptables in our case) inside a network namespace. Within the iptables command, we use the switch -A to add a new rule in the output chain, and the switch -t to indicate that this rule belongs to the filter table (which, actually, is the default if -t is omitted).
The switch -j indicates the target (“jump”). Here, we specify the LOG target. The remaining switches are specific parameters for the LOG target – we define a log prefix which will be added to every log message and the log level with which the messages will appear in the kernel log and the output of dmesg.
Again, I have created a script that you can run (using sudo) to add logging rules to all relevant combinations of chains and tables. In addition, this script will also add logging rules to detect established connections, more on this below, and will make sure that all default policies are ACCEPT and that no other rules are present.
Let us now run try our first ping. We will try to reach boxB from boxA.
sudo ip netns exec boxA \
ping -c 1 172.16.200.5
This will fail with the error message “Network unreachable”, as expected – we do have a route to the network 172.16.100.0/24 on boxA (which the Linux kernel creates automatically when we bring up the interface) but not for the network 172.16.200.0/24 that we try to reach. To fix this, let us now add a route pointing to our router.
sudo ip netns exec boxA \
ip route add default via 172.16.100.1
When we now try a ping, we do not get an error message any more, but the ping still does not succeed. Let us use our logs to see why. When you run dmesg, you should see an output similar to the sample output below.
We see nicely how the various tables are traversed, starting with the four tables in the output chain of boxA. We also see the packet in the POSTROUTING chain of the router, leaving it towards boxB, and are being picked up by boxB. However, no reply is reaching boxA.
To understand why this happens, let us look at the last logging entry that we have from boxB. Here, we see that the request (ICMP type 8) is entering with the source IP address of boxA, i.e. 172.168.100.5. However, there is no route to this host on boxB, as boxB only has one network interface which is connected to 172.16.200.0/24. So boxB cannot generate a reply message, as it does not know how to route this message to boxA.
By the way, you might ask yourself why there are no log entries for the INPUT chain on boxB. The answer is that the Linux kernel has a feature called reverse path filtering. When this filter is enabled (which it seems to be on most Linux distributions by default), then the kernel will silently drop messages coming in from an IP address to which is has no outgoing route as defined in RFC 3704. For documentation on how to turn this off, see this link.
So how can we fix this problem and enable boxB to send an ICMP reply back to boxA? The first idea you might have is to simply add a route on boxB to the network 172.16.100.0/24 with the router as the next hop. This would work in our lab, but there is a problem with this approach in real life.
In a realistic scenario, boxA would typically be a machine in the private network of an organization, using a private IP address from a private address range which is far from being unique, whereas boxB would be a public IP address somewhere on the Internet. Therefore we cannot simply add a route for the IP address of boxA, which is private and should never appear in a public network like the Internet.
What we can do, however, is to add a route to the public interface of our router, as the IP address of this interface typically is a public IP address. But why would this help to make boxA reachable from the Internet?
Somehow we would have to divert reply traffic direct towards boxA to the public interface of our router. In fact, this is possible, and this is where SNAT comes into play.
SNAT (source network address translation) simply means that the router will replace the source IP address of boxA by the IP address of its own outgoing interface (i.e. 172.16.200.1 in our case) before putting the packet on the network. When the packet (for instance an ICMP echo request) reaches boxB, boxB will try to send the answer back to this address which is reachable. So boxB will be able to create a reply, which will be directed towards the router. The router, being smart enough to remember that it has manipulated the IP address, will then apply the reverse mapping and forward the packet to boxA.
To establish this mechanism, we will have to add a corresponding rule with the target SNAT to an appropriate chain of the router. We use the postrouting chain, which is traversed immediately before the packet leaves the router, and put the rule into the NAT table which exists for exactly this purpose.
sudo ip netns exec router \
iptables -t nat \
-A POSTROUTING \
-o veth2 \
-j SNAT --to 172.16.200.1
Here, we also use our first match – in this case, we apply this rule to all packets leaving the router via veth2, i.e. the public interface of our router.
When we now repeat the ping, this should work, i.e. we should receive a reply on boxA. It is also instructive to again inspect the logging output created by iptables using dmesg where we can observe nicely that the IP destination address of the reply changes to the IP address of boxA after traversing the mangle table of the PREROUTING chain of the router (this change is done before the routing decision is taken, to make sure that the route which is determined is correct). We also see that there are no logging messages from our NAT tables anymore on the router for the reply, because the NAT table is only traversed for the first packet in each stream and the same action is applied to all subsequent packets of this stream.
Adding firewall functionality
All this is nice, but there is still an important feature that we need in a real world scenario. So far, our router acts as a router in both directions – the default policies are ACCEPT, and traffic coming in from the “public” interface veth2 will happily be forwarded to boxA. In real life, of course, this is exactly what you do not want – you want to protect boxB against unwanted incoming traffic to decrease the attack surface.
So let us now try to block unwanted incoming traffic on the public device veth2 of our router. Our first idea could be to simply change the default policy for the filter table on each of the chains INPUT and FORWARD to DROP. As one of these chains is traversed by incoming packets, this should do the trick. So let us try this.
sudo ip netns exec router \
iptables -t filter \
-P INPUT DROP
sudo ip netns exec router \
iptables -t filter \
-P FORWARD DROP
Of course this was not a really good idea, as we immediately learn when we execute our next ping on boxA. As we have changed the default for the FORWARD chain to drop, our ICMP echo request is dropped before being able to leave the router. To fix this, let us now add an additional rule to the FORWARD table which ACCEPTs all traffic coming from the private network, i.e. veth1.
sudo ip netns exec router \
iptables -t filter \
-A FORWARD \
-i veth1 -j ACCEPT
When we now repeat the ping, we will see that the ICMP request again reaches boxB and a reply is generated. However, there is still a problem – the reply will reach the router via the public interface, and whence will be dropped.
To solve this problem, we would need a mechanism which would allow the router to identify incoming packets as replies to a previously sent outgoing packet and to let them pass. Again, iptables has a good answer to this – connection tracking.
Connection tracking
Iptables is a stateful firewall, meaning that it is able to maintain the state of a connection. During its life, a connection undergoes state transitions between several states, and an iptables rule can refer to this state and match a packet only if the underlying connection is in a certain state.
When a connection is not yet established, i.e. when a packet is observed that does not seem to relate to an existing connection, the connection is created in the state NEW
Once the kernel has seen packets in both directions, the connection is moved into the state ESTABLISHED
There are connections which could be RELATED to an existing connection, for instance for FTP data connections
Finally, a connection can be INVALID which means that the iptables connection tracking algorithm is not able to handle the connection
To use connection tracking, we have to add the -m conntrack switch to our iptables rule, which instructs iptables to load the connection tracking module, and then the –ctstate switch to refer to one or more states. The following rule will accept incoming traffic which belongs to an established connection, i.e. reply traffic.
sudo ip netns exec router \
iptables -t filter \
-A FORWARD \
-m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT
After adding this rule, a ping from boxA to boxB should work again, and the log messages should show that the request travels from boxA to boxB across the router and that the reply travels the same way back without being blocked.
Destination NATing
Let us summarize what we have done so far. At this point, our router and firewall is able to
Allow traffic from the internal network, i.e. boxA, to pass through the router and reach the public network, i.e. boxB
Conceal the private IP address of boxB by applying source NATing
Allow reply traffic to pass through the router from the public network back into the private network
Block all other traffic from the public network from reaching the private network
However, in some cases, there might actually be a good reason to allow incoming traffic to reach boxA on our internal network. Suppose, for instance, we had a web server (which, as far as this lab is concerned, will be a simple Python script) running on boxA which we want to make available from the public network. We would then want to allow incoming traffic to a dedicated port, say 8800.
Of course, we could add a rule that ACCEPTs incoming traffic (even if it is not a reply) when the target port is 8800. But we need a bit more than this. Recall that the IP address of boxA is not visible on the public network, but the IP address of the router (the IP address of the veth2 interface) is. To make our web server port reachable from the public network, we would need to divert traffic targeting port 8800 of the router to port 8800 of boxA, as indicated in the diagram below.
Again, there is a form of NATing that can help – destination NATing. Here, we leave the source IP address of the incoming packet as it is, but instead change the destination IP address. Thus, when a request comes in for port 8800 of the router, we change the target IP address to the IP address of boxA. When we do this in the PREROUTING chain, before a routing decision has been taken, the kernel will recognize that the new IP destination address is not a local address and will forward the packet to boxA.
To try this out, we first need a web server. I have put together a simple WSGI based web server, which will be present in the directory lab13 if you have cloned the corresponding repository. In a separate window, start the web server, making it run in the namespace of boxA.
cd lab13
sudo ip netns exec boxA python3 server.py
Now let us add a destination NATing rule to our router. As mentioned before, the change of the destination address needs to take place before the routing decision is taken, i.e. in the PREROUTING chain.
sudo ip netns exec boxB \
curl -w "\n" 172.16.200.1:8800
You should now see a short output (a HTML document with “Hello!” in it) from our web server, indicating that the connection worked. Effectively, we have “peeked a hole” into our firewall, connecting port 8080 of the public network front of our router to port 8800 of boxA. Of course, we could also use any other combination of ports, i.e. instead of mapping 8800 to itself, we could as well map port 80 to 8800 so that we could reach our web server on the public IP address of the router on the standard port.
Of course there is much more that we could say about iptables, but this discussion of the core features should put you in a position to read and interpret most iptable rule sets that you are likely to encounter when working with virtual networks, cloud technology and containers. I highly recommend to browse the references below to learn more, and to look at those chains on your local machine that Docker and libvirt install to get an idea how this is used in practice.
In the last post, we have discussed the architecture of Open vSwitch and how it with a control plane to realize an SDN. Today, we will make this a bit more tangible by running two hands-on labs with OVS.
The labs in this post are modelled after some of the How-to documents that are part of the Open vSwitch documentation, but use a combination of virtual machines and Docker to avoid the need for more than one physical machine. In both labs, we bring up two virtual machines which are connected via a VirtualBox virtual network, and inside each machine, we bring up two Docker containers that will eventually interact via OVS bridges.
Lab 11: setting up an overlay network with Open vSwitch
In the first lab, we will establish interaction between the OVS bridges on the two involved virtual machines using an overlay network. Specifically, the Docker containers on each VM will be connected to an OVS bridge, and the OVS bridges will use VXLAN to talk to each other, so that effectively, all Docker containers appear to be connected to an Ethernet network spanning the two virtual machines.
Instead of going through all steps required to set this up, we will again bring up the machines automatically using a combination of Vagrant and Ansible, and then discuss the major steps and the resulting setups. To run the lab, you will again have to download the code from my repository and start Vagrant.
git clone https://github.com/christianb93/networking-samples
cd lab11
vagrant up
While this is running, let us quickly discuss what the scripts are doing. First, of course, we create two virtual machines, each running Ubuntu Bionic. In each machine, we install Open vSwitch and Docker. We then install the docker Python3 module to make Ansible happy.
Next, we bring up two Docker containers, each running an image which is based on NGINX but has some networking tools installed on top. For each container, we set up a pair of two VETH devices. One of the devices is then moved into the networking namespace of the container, and one of the two devices will later be added to our bridge, so that these VETH device pairs effectively operate like an Ethernet cable connecting the containers to the bridge.
We then create the OVS bridge. In the Ansible script, we use the Ansible OVS module to do this, but if you wanted to create the bridge manually, you would use a command like
This is actually a combination of three commands (i.e updates on the OVSDB database) which will be run in one single transaction (the OVS CLI uses the double dashes to combine commands into one transaction). With the first part of the command, we create a virtual OVS bridge called myBridge. With the second and third line, we then add two ports, connected to the two VETH pairs that we have created earlier.
Once the bridge exists and is connected to the containers, we add a third port, which is a VLXAN port, which, using a manual setup, would be the result of the following commands.
Again, we atomically add the port to the bridge and pass the VXLAN options. We set up the VTEP as a point-to-point connection to the second virtual machine, using the standard UDP port and a TTL of five to avoid that UDP packets get lost.
Finally, we configure the various devices and assign IP addresses. To configure the devices in the container namespaces, we could attach to the containers, but it is easier to use netns to run the required commands within the container namespaces.
Once the setup is complete, we are ready to explore the newly created machines. First, use vagrant ssh boxA to log into boxA. From there, use Docker exec to attach to the first container.
sudo docker exec -it web1 "/bin/bash"
You should now be able to ping all other containers, using the IP addresses 172.16.0.2 – 172.16.0.4. If you run arp -n inside the container, you will also find that all three IP addresses are directly resolved into MAC addresses and are actually present on the same Ethernet segment.
To inspect the bridges that OVS has created, exit the container again so that we are now back in the SSH session on boxA and use the command line utility ovs-vsctl to list all bridges.
sudo ovs-vsctl list-br
This will show us one bridge called myBridge, as expected. To get more information, run
sudo ovs-vsctl show
This will print out the full configuration of the current OVS node. The output should look similar to the following snippet.
af3a2230-3d2a-4364-a0b9-1da4e32211e4
Bridge myBridge
Port "web2_veth1"
Interface "web2_veth1"
Port "vxlan0"
Interface "vxlan0"
type: vxlan
options: {dst_port="4789", remote_ip="192.168.50.5", ttl="5"}
Port "web1_veth1"
Interface "web1_veth1"
Port myBridge
Interface myBridge
type: internal
ovs_version: "2.9.2"
We can see that the output nicely reflects the structure of our network. There is one bridge, with three ports – the two VETH ports and the VXLAN port. We also see the parameters of the VXLAN ports that we have specified during creation. It is also possible to obtain the content of the OVSDB tables that correspond to the various objects in JSON format.
sudo ovs-vsctl list bridge
sudo ovs-vsctl list port
sudo ovs-vsctl list interface
Lab 12: VLAN separation with Open vSwitch
In this lab, we will use a setup which is very similar to the previous one, but with the difference that we use layer 2 technology to span our network across the two virtual machines. Specifically, we establish two VLANs with ids 100 (containing web1 and web3) and 200 (containing the other two containers). On those two logical Ethernet networks, we establish two different layer 3 networks – 192.168.50.0/24 and 192.168.60.0/24.
The first part of the setup – bringing up the containers and creating the VETH pairs – is very similar to the previous labs. Once this is done, we again set up the two bridges. On boxA, this would be done with the following sequence of commands.
This will create a new bridge and first add the VM interface enp0s8 to it. Note that by default, every port added to OVS is a trunk port, i.e. the traffic will carry VLAN tags. We then add the two VETH ports with the additional parameter tag which will mark the port as an access port and define the corresponding VLAN ID.
Next we need to fix our IP setup. We need to remove the IP address from the enp0s8 as this is now part of our bridge, and set the IP address for the two VETH devices inside the containers.
sudo ip addr del 192.168.50.4 dev enp0s8
web1PID=$(sudo docker inspect --format='{{.State.Pid}}' web1)
sudo nsenter -t $web1PID -n ip addr add 192.168.50.1/24 dev web1_veth0
web2PID=$(sudo docker inspect --format='{{.State.Pid}}' web2)
sudo nsenter -t $web2PID -n ip addr add 192.168.60.2/24 dev web2_veth0
Finally, we need to bring up the devices.
sudo nsenter -t $web1PID -n ip link set web1_veth0 up
sudo nsenter -t $web2PID -n ip link set web2_veth0 up
sudo ip link set web1_veth1 up
sudo ip link set web2_veth1 up
The setup of boxB proceeds along the following lines. In the lab, we again use Ansible scripts to do all this, but if you wanted to do it manually, you would have to run the following on boxB.
sudo ovs-vsctl add-br myBridge
sudo ovs-vsctl add-port myBridge enp0s8
sudo ovs-vsctl add-port myBridge web3_veth1 tag=100
sudo ovs-vsctl add-port myBridge web4_veth1 tag=200
sudo ip addr del 192.168.50.5 dev enp0s8
web3PID=$(sudo docker inspect --format='{{.State.Pid}}' web3)
sudo nsenter -t $web3PID -n ip addr add 192.168.50.3/24 dev web3_veth0
web4PID=$(sudo docker inspect --format='{{.State.Pid}}' web4)
sudo nsenter -t $web4PID -n ip addr add 192.168.60.4/24 dev web4_veth0
sudo nsenter -t $web3PID -n ip link set web3_veth0 up
sudo nsenter -t $web4PID -n ip link set web4_veth0 up
sudo ip link set web3_veth1 up
sudo ip link set web4_veth1 up
Instead of manually setting up the machines, I have of course again composed a couple of Ansible scripts to do all this. To try this out, run
git clone https://github.com/christianb93/networking-samples
cd lab12
vagrant up
Now log into one of the boxes, say boxA, attach to the web1 container and try to ping web3 and web4.
You should see that you can get a connection to web3, but not to web4. This is of course what we expect, as the VLAN tagging is supposed to separate the two networks. To see the VLAN tags, open a second session on boxA and enter
sudo tcpdump -e -i enp0s8
When you now repeat the ping, you should see that the traffic generated from within the container web1 carries the VLAN tag 100. This is because the port to which enp0s8 is attached has been set up as a trunk port. If you stop the dump and start it again, but this time listening on the device web1_veth1 which we have added to the bridge as an access port, you should see that no VLAN tag is present. Thus the bridge operates as expected by adding the VLAN tag according to the tag of the access port on which the traffic comes in.
In the next post, we will start to explore another important feagure of OVS – controlling traffic using flows.
In the previous posts, we have used standard Linux tools to establish and configure our network interfaces. This is nice, but becomes very difficult to manage if you need to run environments with hundreds or even thousands of machines. Open vSwitch (OVS) is an Open source software switch which can be integrated with SDN control planes and cloud management software. In this post, we will look a bit at the theoretical background of OVS, leaving the practical implementation of some examples to the next post.
Some terms from the world of software defined networks
It is likely that you have heard the magical word SDN before, and it is also quite likely that you have already found that giving a precise meaning to this term is hard. Still, there is a certain agreement that one of the core ideas of SDN is to separate data flow through your networking devices from the and networking configuration.
In a traditional data center, your network would be implemented by a large number of devices like switches and routers. Each of these devices holds some configuration and typically has a way to change that configuration remotely. Thus, the configuration is tightly integrated with the networking infrastructure, and making sure that the entire configuration is consistent and matches the desired state of your network is hard.
With sofware defined networking, you separate the configuration from the networking equipment and manage it centrally. Thus, the networking equipment handles the flow of data – and is referred to as the data plane or flow plane – while a central component called the control plane is responsible for controlling the flow of data.
This is still a bit vague, but becomes a bit more tangible when we look at an example. Enter Open vSwitch (OVS). OVS is a software switch that turns a Linux server (which we will call a node) into a switch. Technically, OVS is a set of server processes that are installed on each node and that handle the network flow between the interfaces of the node. These nodes together make up the data plane. On top of that, there is a control plane or controller. This controller talks to the individual nodes to make sure the rules that they use to manage traffic (called the flows) are set up accordingly.
To allow controllers and switch nodes to interact, an open standard called OpenFlow has been created which defines a common way to describe flows and to exchange data between the controller and the switches. OVS supports OpenFlow (currently only version 1.1 is supported) and thus can be combined with OpenFlow based controllers like Faucet or Open Daylight, creating a layered architecture as follows. Additionally, a switch can be configured to ask the controller how to handle a packet for which no matching flow can be found.
Here, OVS uses OpenFlow to exchange flows with the controller. To exchange information on the underlying configuration of the virtual bridge (which ports are connected, how are these ports set up, …) OVS provides a second protocol called OVSDB (see below) which can also be used by the control plane to change the configuration of the virtual switch (some people would probably prefer to call the part of the control logic which handles this the management plane in contrast to the control plane, which really handles the data flow only).
Components of Open vSwitch
Let us now dig a little bit into the architecture of OVS itself. Essentially, OVS consists of three components plus a set of command-line interfaces to operate the OVS infrastructure.
First, there is the OVS virtual switch daemon ovs-vswitchd. This is a server process running on the virtual switch and is connected to a socket (usually a Unix socket, unless it needs to communicate with controllers not on the same machine). This component is responsible for actually operating the software defined switch.
Then, there is a state store, in the form of the ovsdb-server process. This process is maintaining the state that is managed by OVS, i.e. the objects like bridges, ports and interfaces that make up the virtual switch, and tables like the flow tables used by OVS. This state is usually kept in a file in JSON format in /etc/openvswitch. The OVSDB connects to the same Unix domain socket as the Switch daemon and uses it to exchange information with the Switch daemon (in the database world, the switch daemon is a client to the OVSDB database server). Other clients can connect to the OVSDB using a JSON based protocol called the OVSDB protocol (which is described in RFC 7047) to retrieve and update information.
The third main component of OVS is a Linux kernel module openvswitch. This module is now part of the official Linux kernel tree and therefore is typically pre-installed. This kernel module handles one part of the OVS data path, sometimes called the fast path. Known flows are handled entirely in kernel space. New flows are handled once in the user space part of the datapath (slow path) and then, once the flow is known, subsequently in the kernel data path.
Finally, there are various command-line interfaces, the most important one being ovs-vsctl. This utility can be used to add, modify and delete the switch components managed by OVS like bridges, port and so forth – more on this below. In fact, this utility operates by making updates to the OVSDB, which are then detected and realized by the OVS switch daemon. So the OVSDB is the leading provider of the target state of the system.
The OVS data model
To understand how OVS operates, it is instructive to look at the data model that describes the virtual switches deployed by OVS. This model is verbally described in the man pages. If you have access to a server on which OVS is installed, you can also get a JSON representation of the data model by running
ovsdb-client get-schema Open_vSwitch
At the top level of the hierarchy, there is a table called Open_vSwitch. This table contains a set of configuration items, like the supported interface types or the version of the database being used.
Next, there are bridges. A bridge has one or more ports and is associated with a set of tables, each table representing a protocol that OVS supports to obtain flow information (for instance NetFlow or OpenFlow). Note that the Flow_Table does not contain the actual OpenFlow flow table entries, but just additional configuration items for a flow table. In addition, there are mirror ports which are used to trace and monitor the network traffic (which we ignore in the diagram below).
Each port refers to one or more interfaces. In most situations, each port has one interface, but in case of bonding, for instance, one port is supported by two interfaces. In addition, a port can be associated with QoS settings and queue for traffic control.
Finally, there are controllers and managers. A controller, in OVS terminology, is some external system which talks to OVS via OpenFlow to control the flow of packets through a bridge (and thus is associated with a bridge). A manager, on the other hand, is an external system that uses the OVSDB protocol to read and update the OVSDB. As the OVS switch daemon constantly polls this database for changes, a manager can therefore change the setup, i.e. add or remove bridges, add or remove ports and so on – like a remote version of the ovs-vsctl utility. Therefore, managers are associated with the overall OVS instance.
Installation and first steps with OVS
Before we get into the actual labs in the next post, let us see how OVS can be installed, and let us use OVS to create a simple bridge in order to get used to the command line utilities.
On an Ubuntu distribution, OVS is available as a collection of APT packages. Usually, it should be sufficient to install openvswitch-switch, which will pull in a few additional dependencies. There are similar packages for other Linux distributions.
Once the installation is complete, you should see that two new server processes are running, called (as you might expect from the previous sections) ovsdb-server and ovs-vswitchd. To try out that everything worked, you can now run the ovs-vsctl utility to display the current configuration.
$ ovs-vsctl show
518a2ed6-56d0-433f-98f2-a575daf20f72
ovs_version: "2.9.2"
The output is still very short, as we have not yet defined any objects. What it shows you is, in fact, an abbreviated version of the one and only entry in the Open_vSwitch table, which shows the unique row identifier (UUID) and the OVS version installed.
Now let us populate the database by creating a bridge, currently without any ports attached to it. Run
sudo ovs-vsctl add-br myBridge
When we now inspect the current state again using ovs-vsctl show, the output should look like this.
Note how the output reflects the hierarchical structure of the database. There is one bridge, and attached to this bridge one port (this is the default port which is added to every bridge, similarly to a Linux bridge where creating a bridge also creates a device that has the same name as the bridge). This port has only one interface of type “internal”. If you run ifconfig -a, you will see that OVS has in fact created a Linux networking device myBridge as well. If, however, you run ethtool -i myBridge, you will find that this is not an ordinary bridge, but simply a virtual device managed by the openvswitch driver.
It is interesting to directly inspect the content of the OVSDB. You could either do this by browsing the file /etc/openvswitch/conf.db, or, a bit more conveniently, using the ovsdb-client tool.
sudo ovsdb-client dump Open_vSwitch
This will provide a nicely formatted dump of the current database content. You will see one entry in the Bridge table, representing the new bridge, and corresponding entries in the Port and Interface table.
This closes our post for today. In the next post, we will setup an example (again using Vagrant and Ansible to do all the heavy lifting) in which we connect containers on different virtual machines using OVS bridges and a VXLAN tunnel. In the meantime, you might want to take a look at the following references which I found helpful.
In the last post, we have looked at virtual networking on the Ethernet level. In modern cloud environments, a second class of virtual networks has gained importance, which uses higher level protocols to tunnel Ethernet frames. These networks are called overlay networks, and we will start to look at them in this post.
VXLAN – the basics
The VLAN technology that we have looked at in the last post is useful, but has some limitations. First, there is the maximum number of possible VLANs (4096). In practice, certain VLAN ranges need to be reserved for internal purposes, further limiting the number of available VLANs. In cloud environments with a large number of tenants, this limit can easily be reached if we try to implement all virtual networks via VLAN. In addition, VLAN tags inserted by the tenants could conflict with the VLAN tags inserted by the host operating systems.
To solve these problems, a new standard called VXLAN was developed a couple of years back, which is described (though not defined, as this is an informational RFC) in RFC 7348. The basic idea of VXLAN is actually quite simple. On each host involved, we create a virtual network device. When an Ethernet frame needs to be transmitted via this device, the host creates a UDP packet, puts the Ethernet frame as payload into this packet and sends it to the target host. The target host receives the packet, strips off the headers, and re-injects the payload (i.e. the original Ethernet frame) into the networking stack of the target system. Thus Ethernet frames travels on top of UDP, and the virtual Ethernet networks logically sits on top of the layer 3 IP network used to exchange the UDP packets, leading to the name overlay network.
To be able to isolate different VXLANs from each other, a 24 bit VXLAN network identifier (VNI) is used. The implementation needs to make sure that Ethernet frames are only delivered within the same VNI, thus isolating the different VXLAN networks from each other. A host that is able to provide VXLAN devices and to participate in the exchange of UDP packets is called a VXLAN tunnel endpoint (VTEP). Thus to send an Ethernet frame over VXLAN, a VTEP needs to
Add a VXLAN header that contains the VNI, so that the receiving VTEP can make sure that the frame is only delivered within the correct VNI
Pass the resulting data as payload to the own IP stack, which will add a UDP, IP and Ethernet header to be able to transmit the frame over an existing layer 2 network
To be able to locate the UDP target address to which we have to send an encapsulated Ethernet frame, each VTEP needs to maintain a table containing mapping between the IP addresses of other VTEPs and the corresponding MAC addresses. A VTEP typically learns how to populate this table and uses IP multicast to ask other VTEPS to resolve unknown MAC addresses, similar to the ARP protocol.
When VXLAN is used, there are a few points that should be kept in mind. First, we do of course add quite a bit of overhead. For every Ethernet frame that is being exchanged, we add a second Ethernet header, an IP header and a UDP header, plus the processing time it takes on the host to travel the networking stack up and down once more. In addition, there is a problem with the MTU (maximum transfer unit) configured for the VXLAN endpoints. As the Ethernet frames on the physical network are longer than the Ethernet frames on the overlay network (as we need the additional headers), we will have to increase the MTU on the physical network to account for this in order to avoid unnecessary fragmentation. Also, using VXLAN implies that your Ethernet frames flow in clear text over the IP connection, so if you want to use VXLAN across unsecure network areas, then you should use some form of encryption like IPSec.
Lab 9: setting up a point-to-point VXLAN connection
To see this in action, let us first implement a very basic scenario. Assume that we have two hosts (virtual machines provided by VirtualBox in our case) that are part of the same layer 3 network. On each host, we ask the Linux kernel to create a virtual device of type VXLAN. To this virtual device, we can assign IP addresses as usual. Any Ethernet frames sent to the device will be encapsulated using the VXLAN protocol and will be sent to the peer, where the Linux kernel will strip off the outer header and re-inject the Ethernet frame. So the Linux kernel acts as a VTEP on both sides.
Again, I have automated the setup using Vagrant and Ansible. To run the example, simply enter the following commands
git clone https://github.com/christianb93/networking-samples
cd networking-samples/lab9
vagrant up
To inspect the setup, let us first SSH into boxA. If you run ifconfig -a, you will in fact see a new device called vxlan0. This device has been created and configured by our Ansible script using the following commands.
ip link add type vxlan id 100 remote 192.168.50.5 dstport 4789 dev enp0s8
ip addr add 192.168.60.4/24 dev vxlan0
ip link set vxlan0 up
The first command creates the device, specifying the VNI 100, the IP address of the peer, the port number to use for the UDP connection (we use the port number defined in RFC 7348) and the physical device to be used for the transmission. The second and third command then assign an IP address and bring the device up.
When you run netstat -a on boxA, you will also find that a UDP socket has been created on port 4789, this socket is ready to accept UDP packets from the peer carrying encapsulated Ethernet frames. The setup on boxB is similar, using of course a different IP address.
Let us now try to exchange traffic and to display the packets that go forth and back. For that purpose, open an SSH session on boxB as well and start a tcdump session listening on vxlan0.
sudo tcpdump -e -i vxlan0
You will a sequence of ARP and IPv4 packets, with the source and target MAC addresses matching the MAC addresses of the vxlan0 devices on the respective hosts. Thus the device acts like an ordinary Ethernet device, as expected.
Now let us change the setup and start to dump traffic on the underlying physical interface.
sudo tcpdump -e -i enp0s8
When you now repeat the ping, you will see that the packets arriving at the physical interface are UDP packets. In fact, tcpdump properly recognizes these frames as VXLAN frames and also prints the inner headers. We see that the outer Ethernet headers contain the MAC addresses of the underlying network interfaces of boxA and boxB, whereas the inner headers contain the MAC addresses of the vxlan0 devices.
Lab 10: VXLAN and IP multicasting
So far, we have used a direct point-to-point connection between the two hosts involved in the VXLAN network. In reality, of course, things are more complicated. Suppose, for instance, that we have three hosts representing VTEP endpoints. If an Ethernet frame on one of the hosts reaches the VXLAN interface, the kernel needs to determine to which of the other hosts the resulting UDP packet should be sent.
Of course, we could simply broadcast the packet to all hosts on the IP network, using a broadcast, but this would be terribly inefficient. Instead, VXLAN uses IP multicast functionality. To this end, the administrator setting up VXLAN needs to associate an IP multicast address with each VNI. A VTEP will then join this group and will use the IP multicast address for all traffic that needs to go to one or more Ethernet destinations. In a local network, you want to use one of the “private” IP multicast groups in the range 239.0.0.0 – 239.255.255.255 reserved by RFC 2365, for instance within the local scope 239.255.0.0/16.
To study this, I have created lab 10 which establishes a scenario in which three hosts serve as VTEP to span a VXLAN with VNI 100. As always, grab the code from GitHub, cd into the directory lab10 and run vagrant up to start the example.
The setup is very similar to the setup for the point-to-point connection above, with the difference that when bringing up the VXLAN device, we have removed the remote parameter and replaced it by the group parameter to tie the VNI to the multicast group.
ip link \
add type vxlan \
id 100 \
group 239.255.0.1 \
ttl 5 \
dstport 4789 \
dev enp0s8
Note the parameter TTL which defines the initial TTL that will be set on the UDP packets sent out by the VTEP. When I tried this setup first, I did not set the TTL, resulting in the default of one. With this setup, however, ARP requests were not answered by the target host, and I had to increase the TTL by adding the additional parameter.
Let us test this setup. Open SSH connections to the boxA and boxB. First, we can use ip maddr show enp0s8 to verify that on both machines, the interface enp0s8 has joined the multicast group 239.255.0.1 that we specified when bringing up the VXLAN. Then, start a tcpdump session on enp0s8 on boxC and ping the VXLAN IP address 192.168.60.5 of boxB from boxA. As this is the first time we establish this connection, the Ethernet device should emit an ARP request. This ARP request is encapsulated and sent out as an IP multicast with IP target address 239.255.0.1. In tcpdump, the corresponding output (again displaying the outer and inner headers) looks as follows.
We can clearly see that the outer IP header has the multicast IP address as target address, and that the inner frame is an ARP request, looking to resolve the IP address of the VXLAN device on boxB.
The multicast mechanism is used to initially discover the mapping of IP addresses to Ethernet addresses. However, this is typically only required once, because the VTEP is able to learn this mapping by storing it in a forwarding database (FDB). To see this mapping, switch to boxA and run
bridge fdb show dev vxlan0
In the output, you should be able to locate the Ethernet address of the VXLAN device on boxC, being mapped to the IP address of boxC on the underlying network, i.e. 192.168.50.6.
Other overlay solutions
In this post, we have studied overlay networks based on VXLAN in some detail. However, VXLAN is not the only available overlay protocol. We just mention two alternative solutions without going into details.
First, there is GRE (Generic Routing Encapsulation). which is defined in RFC 2784. GRE is a generic protocol to encapsulate packets within other packets. It defines a GRE header, which is put between the headers of the outer protocol and the payload, similar to the VXLAN header. Other than VXLAN, GRE allows different protocols both as payload protocols and as delivery (outer) protocols. Linux supports both IP over IP tunneling using GRE, using the device type gre for IP-over-IP tunnels and the device type gretap for Ethernet-over-IP tunneling.
Then, there is GENEVE, which is an attempt to standardize encapsulation protocols. It is very similar to VXLAN, tunneling Ethernet frames over UDP, but defines a header with optional fields to allow for future extensions.
And finally, Linux offers a few additional tunneling protocols like the IPIP module for tunneling of IP over IP traffic or SIT to tunnel IPv6 over IPv4 which have been present in the kernel for some time and predate some of the standards just discussed.
In this and the previous posts, we have mainly used Linux kernel technology to realize network virtualization. However, there are other options available. In the next post, I will start to explore Open vSwitch (OVS), which is an open-source software defined switching solution.
In the previous posts, we have mainly been looking at virtual networking within one single physical hosts. This is nice, but to build cloud environments, we need to establish virtual networks across several physical hosts. In this post, we will start to look into technologies that make this possible and learn how VLAN tagging supports virtual Ethernet networks.
An introduction to virtual Ethernet networks
Today, essentially every Ethernet network you will come across is a switched network, where every server is more or less directly connected to a switch, and the switches are connected to each other to propagate traffic through your data center. A naive approach would be to use layer 2 switches to combine all Ethernet networks into one large broadcast domain, where every node is connected to every other node by a sequence of switches. This approach, however, creates a very large broadcast domain and is difficult to maintain as changes to the topology need to be done by a physical rearrangement. It might therefore be beneficial to have some way of dividing your physical Ethernet network into two or more logical (“virtual”) networks.
For servers that are connected to the same switch, this can be implemented by an approach known as port-based VLAN. To illustrate the idea, let us look at the following configuration, where four servers are connected to four different ports of one switch.
With this setup, a broadcast issued by one server will reach every other server, and all servers are part of one Ethernet network. To introduce virtualization, we could simply add some logic to the switch to divide the ports into two sets, where forwarding of Ethernet frames is only done within those two sets. If, for instance, we define one set to consist of the two ports connected to server 1 and server 2 (green), and the other consisting of the remaining two ports (red), and configure the switch such that it will only forward frames between ports with the same color, we will effectively have established two virtual networks.
This is nice, as – if your switch supports it – no additional hardware is required and you can define and change the configuration entirely in software. But there is a problem. Typically, your data center will have more than one switch. How can you extend these virtual networks across multiple switches? Of course, you could add an additional connection for every virtual network between any two switches, but this will blow up your hardware requirements and again make changes in hardware necessary. To avoid this, a technology called VLAN trunking is needed.
With VLAN trunking, different virtual LANs (VLANs) can share the same physical connection. To enable this, Ethernet frames that travel on this shared part of your infrastructure are enhanced by adding a VLAN tag which contains a numerical ID identifying the VLAN to which they belong, as indicated in the following diagram.
Here, we have two switches, which both use port-based virtual networks as just discussed. The upper two ports of each switch belong to the green network which is assigned the ID 1 (VLAN ID or VID, note that in reality, this ID is often reserved) and the other set of ports is part of VLAN 2 (the red network). When a frame leaves, for instance, the server in the upper left corner and needs to be forwarded to the server in the upper right corner, the switch will add a VLAN tag to indicate that this frame is part of VLAN 1. Then the frame travels across the connection between the two switches. Then the switch on the right hand side receives the frame, it strips off the VLAN frame again and, based on the tag, injects the frame back into its own VLAN 1, so that it can only reach the green ports on the right hand side.
Thus your network is divided into two parts. In the middle, on the connection between the two switches, frames carry the VLAN tag to flag them as being part of the red or green network. Thus the ports facing this part need to be aware of the VLAN tag – these ports are often called trunk ports. The parts of the network behind the switches, however, do never see a VLAN tag, as it is added and removed by the switches when transmitting and receiving on trunk ports. These ports are called access ports. Thus the servers do not need to known to which VLAN they belong, and the configuration can be done entirely on the switches and in software.
The standard that describes all this and also defines how a VLAN tag is added to an Ethernet frame is called IEEE 802.1Q. This standard adds a 16-bit field called TCI – tag control information to the layout of an Ethernet frame. Four bits of this field are reserved for other purposes, so that 12 bits remain for the VLAN ID, allowing a maximum of 4096 different VLANs.
Lab 8: VLAN networking with Linux
Linux has the capability to create virtual Ethernet devices that are associated with a VLAN network. To see this in action, get lab 8 from my GitHub repository and run it.
git clone https://github.com/christianb93/networking-samples
cd networking-samples/lab8
vagrant up
The Vagrantfile and the three Ansible playbooks that are located in this directory will now execute and bring up three virtual machines. Here is a diagram summarizing the network configuration that the scripts create (we will see how this is done manually further below).
We see that all three machines are connected to one virtual Ethernet cable (we use a VirtualBox internal network for that purpose). The three interfaces attached to this network are configured as part of the IP network 192.168.50.0/24.
However, in addition, we have set up two virtual networks – one network with VLAN ID 100 (green), and a second network with VLAN ID 200 (red). In each Linux machine, the virtual networks to which the machine is attached is represented by a virtual device called a VLAN device.
Let us look at boxA to see how this works. On boxA, the Ansible playbook that got executed during the vagrant up did run the following command
vconfig add enp0s8 100
This command is creating a new network interface enp0s8.100 sitting on top of enp0s8 but being associated with the VID 100. This device is an ordinary device from the point of view of the operating system, i.e. you can assign IP addresses, add routes and so forth.
Such a VLAN device operates as follows. When an Ethernet frame arrives on the underlying device, enp0s8 in our case, the kernel checks whether the frame contains a VLAN tag. If no, the processing is as usual. If yes, then the kernel next checks whether a VLAN device is associated with this VID. If there is one, it strips off the VLAN tag, changes the frame so that it appears to be coming from the virtual VLAN device and re-injects the frame into the networking stack. The frame then travels up the stack and can be processed by the higher layers, e.g. the IP layer. Conversely, if a frame needs to be transmitted on enp0s8.100, the kernel adds a VLAN tag with the VID 100 to the frame and redirects it to the physical device enp0s8.
Let us see this in action. Open two SSH connections, one to boxA, and one to boxB – if you use the Gnome terminal, simply run
for i in "A" "B" ; do gnome-terminal -e "vagrant ssh box$i"; done
In boxA, start a tcpdump session on the VLAN device.
sudo tcpdump -e -i enp0s8.100
On boxB, ping boxA, using the IP address 192.168.60.4 (the IP address of the VLAN device). You will see an ordinary frame coming in, with ethertype IPv4. There is no VLAN tag within this frame, and the VLAN device operates like a physical device with no VLAN tagging.
Now, stop the tcpdump session and start it again, but this time, use enp0s8 instead of enp0s8.100, i.e. the underlying physical device. If you now run a ping again, you will see that the ethertype of the incoming packages has changed and is now 802.1Q, indicating that the frame is tagged (tcpdump will also show you the VLAN ID 100).
When you ping boxA from boxB using the IP address 192.168.50.4, the traffic will be as expected, coming in on enp0s8 without any VLAN tag, and will not reach enp0s8.100. Thus even though you have put a VLAN device on top of the physical interface, you can still use the physical interface as usual.
It is instructive to check the ARP cache on boxB using arp -n after the pings have been exchanged. You will see that the MAC address of the enp0s8 device on boxA now appears twice, once with the IP address 192.168.50.4 and once with 192.168.60.4. So the MAC address is shared between the virtual VLAN device and the physical device.
Still, the traffic is separated by the Linux kernel. If, for instance, you try to ping 192.168.70.6 (one of the IP addresses of boxC) from boxA, you will not be successful, because this IP address is on the red network and not reachable from the green network. If you run the ping on boxB, however, it will work, because boxB participates in both virtual networks.
This closes todays lab. In the next lab, we will start to look at a completely different approach to building virtual networks – overlay networks.
In the previous post, we have seen how a software-defined Linux bridge can be established and how it transparently connects two Ethernet devices. In this post, we will take a closer look at how to set up and monitor bridges and learn how VirtualBox uses bridges for virtual networking.
Lab 6: setting up and monitoring bridges
For this lab, we will start with the setup of lab 5 that we have gone through in the previous post. If you have destroyed your environments again, the easiest way to get back to the point where we left off is to let Vagrant and Ansible do the work. I have created a Vagrantfile and a set of playbooks to take care of this. So simply do
git clone https://github.com/christianb93/networking-samples
cd lab6
vagrant up
to bring up all machines and configure the network interfaces as in my last post. You can then use vagrant ssh to SSH into one of the three virtual machines.
First, let us go through the steps that we have used to set up boxB, the machine on which the bridge is running. Recall that, after installing the bridge-utils package, we used the following sequence of commands.
The first command is easy to understand. It uses the brctl command line utility to actually set up a bridge called myBridge.
Next, we re-configure the two devices that we will turn into bridge ports. As explained in chapter 10 of “Understanding Linux network internals”, if an Ethernet frame is received on an interface which has been added to a bridge, the usual processing of the frame (i.e. passing the frame to all registered layer 3 protocol handlers) is skipped, and the frame is handed over to the bridging code. Therefore, it does not make sense to have an IP address associated with our bridge ports enp0s8 and enp0s9 any more. In addition, we need to set the devices into promiscuous mode, i.e. we need to enable them to receive packets which are not directed towards their own Ethernet address. This becomes clear if you look at our network diagram once more.
If an Ethernet frame is sent out by boxC, directed towards the interface of boxA, it will have the MAC address of this interface as target address in its Ethernet header. Still, it needs to be picked up by the enp0s9 device on boxB so that it can be handed over to the bridge. If we would not put the device into promiscuous mode, it would drop the frame as its target MAC address does not match its own MAC address (strictly speaking, setting the device into promiscuous mode manually is not really needed, as the Linux kernel will do this automatically when we add the port to the bridge, but we do this here explicitly to highlight this point).
Once we have re-configured our two network devices, we add them to the bridge using brctl addif. We finally bring up the bridge using ifconfig.
Let us now look a bit into the details of our bridge. First, recall that a bridge usually operates by learning MAC addresses. For a Linux bridge, this holds as well, and in fact, a Linux bridge maintains a table of known MAC addresses and the ports behind which they are located. To display this table, open an SSH connection to boxB and run
sudo brctl showmacs myBridge
If you look at the output, you will see that the bridge differentiates between local and non-local addresses. A local address is the MAC address of an interface which is attached to the bridge. In our case, these are the two interfaces enp0s9 and enp0s8 that are part of your bridge on boxB. A non-local address is the address of an Ethernet device on the local network which is not directly attached to the bridge. In our example, these are the Ethernet devices enp0s8 on boxA and boxC.
You also see that these entries are ageing, i.e. if no frames related to an interface that the bridge knows are seen for some time, the entry is dropped and recreated if the interface appears again. The reason for this behaviour is to avoid problems if you reconfigure your physical network so that maybe an Ethernet device thas has been part of the network behind port 1 moves into a part of the network which is behind port 2.
You can also monitor the traffic that flows through the bridge. If, for instance, you run a sniffer like tcpdump on box B using
sudo tcpdump -e -i myBridge
and then create some traffic using for instance ping, you will see that the packets cross the Ethernet bridge.
It is also instructive to run a traceroute on boxA targeted towards boxC. If you do this, you will find that there is no hop between the two devices, again confirming that our bridge operates on layer 2 and behaves like a direct connection between boxA and boxC.
Finally, let us quickly discuss the configuration of the bridge itself. If you look at the configuration using ifconfig myBridge, you will see that the bridge has a MAC address itself, which is the lowest MAC address of all devices added to the bridge (but can also be set manually). In fact, we will see in a second that it is also possible to assign an IP address to a bridge!
This is a bit confusing, after all, a bridge is logically simply a direct connection between the two ports, but nothing which can by itself emit and absorb Ethernet frames. However, on Linux, setting up a bridge also creates a “default-port” on the bridge which is handled like any other network device. Technically speaking, the bridge driver is itself a network device driver (implemented here), and you can ask it to transmit frames. I tend to think of the situation as in the following image.
When the Linux kernel asks the bridge to transmit a frame, the bridge code will consult its table of known MAC addresses and send the frame to the correct port. Conversely, if a frame is received by any of the two ports enp0s8 or enp0s9 and forwarded to the bridge, the bridge does not only forward the frame to the correct port depending on the destination address, but also delivers the frame to the higher layers of the Linux networking stack if its Ethernet target address matches the MAC address of the bridge (or any of the local MAC address in the table of known MAC addresses).
Let us try this out. In our configuration so far, we have not been able to reach boxB via the bridged network, and, conversely, we could not reach boxA and boxC from boxB (try a ping to verify this). Let us now assign an IP address to the bridge device itself and add a route. On boxB, run
which will automatically add a route as well. Now, our network diagram has changed as follows (note the additional IP address on boxB).
You should now be able to ping boxB (192.168.70.4) from both boxA and boxB and vice versa. This capability allows one to use one Linux host as both an Ethernet bridge and a router at the same time.
Lab 7: bridged networking with VirtualBox
So far, we have used VirtualBox to create virtual machines, and have played with bridges inside these machines. Now we will turn this around and see how conversely, VirtualBox can use bridges to realize virtual networks.
It is tempting to assume that what is called bridged networking in the VirtualBox documentation actually uses bridges. This, however, is no longer the case. Instead, when you define a bridged network with VirtualBox, the vboxnetflt netfilter driver that also featured in our last post will be used to attach a “virtual Ethernet cable” to an existing device, and the device will be set into promiscuous mode so that it can pick up Ethernet frames targeted towards the virtual ethernet card of the VM and redirect them to the VirtualBox networking engine. Effectively, this exposes the virtual device of the VM to the local network. This is the reason that this mode of operations is called public networking in Vagrant.
Let us try this out. Again, you can start the test setup using Vagrant. This time, the Vagrantfile contains several machines which we bring up one by one.
git clone https://github.com/christianb93/network-samples
cd lab7
vagrant up boxA
When you start this script, it will first scan your existing network interfaces on the host and ask you to which it should connect. Choose the device which connects your machine to the LAN, for me this is eno1 which has the IP address 192.168.178.25 assigned to it.
To run these tests, you need a second machine connected to the same LAN to which your host is connected via the device that we have just used (eno1). In my case, this second machine has the IP address 192.168.178.28. According to the diagram above, this machine should now be able to see our VM the local network. In fact, all we have to do is to establish the required route. First, on your second machine, run
where eth0 needs to be replaced by the device which this machine uses to connect to the LAN. Now SSH into the virtual machine boxA and set up the corresponding route there.
In boxA, you should now be able to ping 192.168.178.28, and conversely, in your second machine, you should be able to ping 192.168.50.4. The setup is logically equivalent to the following diagram.
Of course this setup is broken as we work with two different subnets / netmasks on the same Ethernet network, but hopefully serves well to illustrate bridged networking with VirtualBox.
Now we stop this machine again, create a bridge on the host and bring up the second and third machine that are used in this lab.
vagrant destroy boxA --force
sudo brctl addbr myBridge
vagrant up boxB
vagrant up boxC
Here, both machines have a network device using the bridged networking mode. The difference to the previous setup, however, is now that the virtual machines are not attached to an existing physical device, but to a bridge, and both are attached to the same bridge.
This configuration is very flexible and leaves many options. We could, for instance, use an existing bridge created by some other virtualization engine or even Docker to interact with other virtual networks. We could also, as in the previous post, set up forwarding and NAT rules and assign an IP address to the bridge device to use the bridge as a gateway into the LAN. And we can attach additional interfaces like veth and tun/tap devices to the bridge. I invite you to play with this to try out some of these options.
We have now seen some of the typical networking technologies in virtual networks in action. However, there are additional approaches that we have not touched upon net – network separation using VLAN tags and overlay networks. In the next post, we will study to look at VLANs in order to establish virtual networks on layer 2.


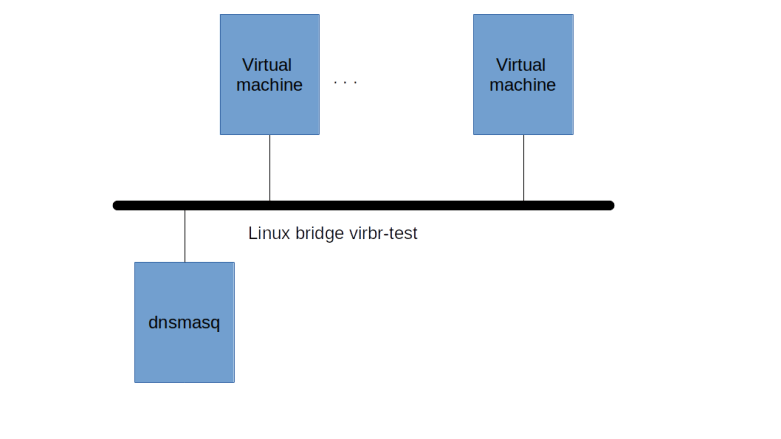

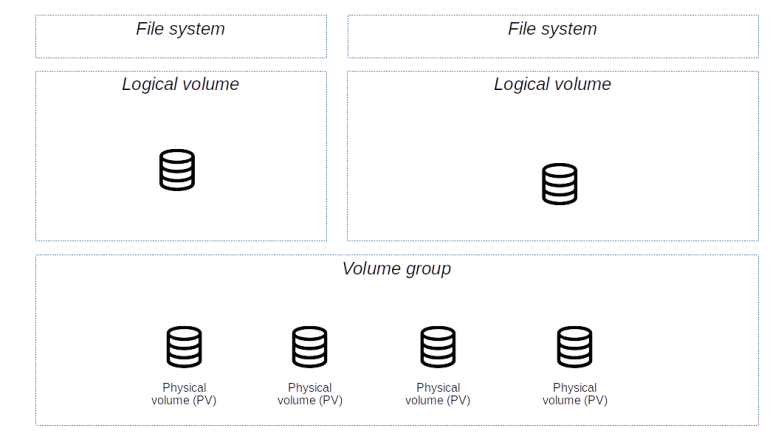
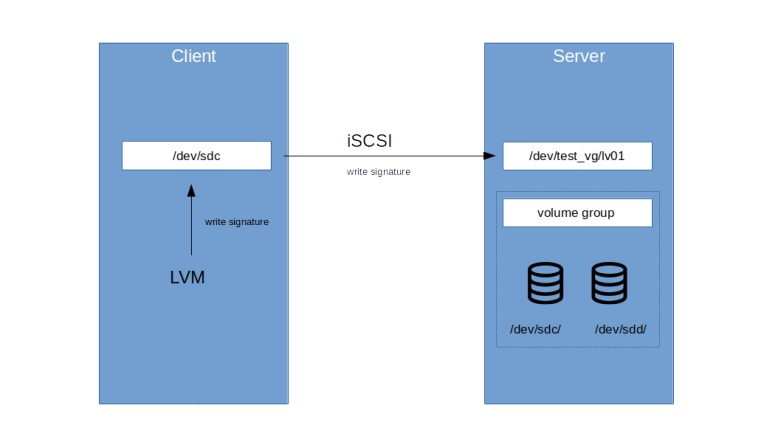


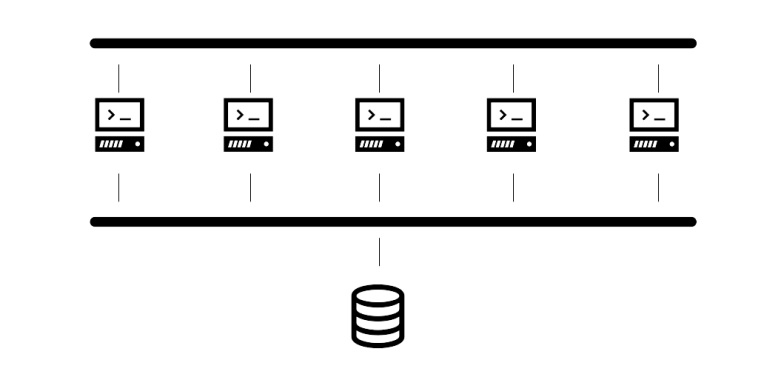
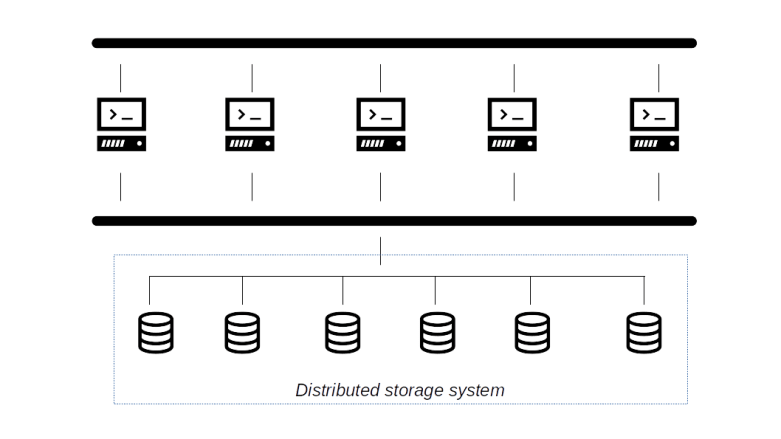
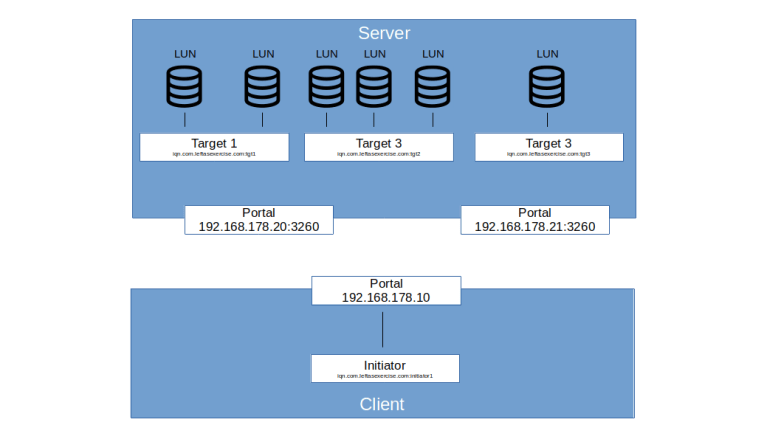






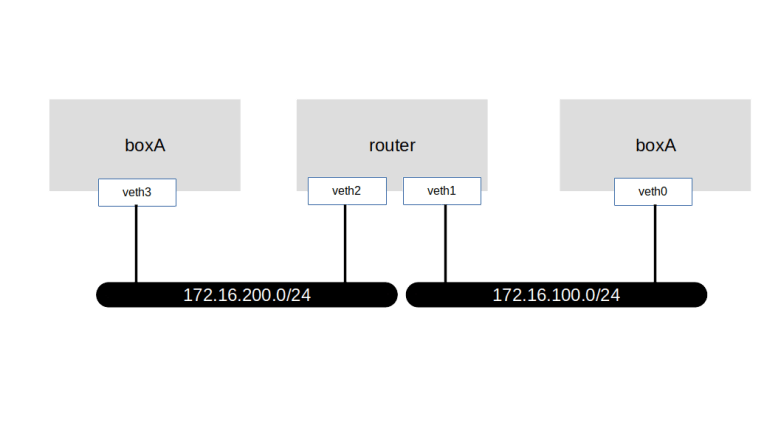
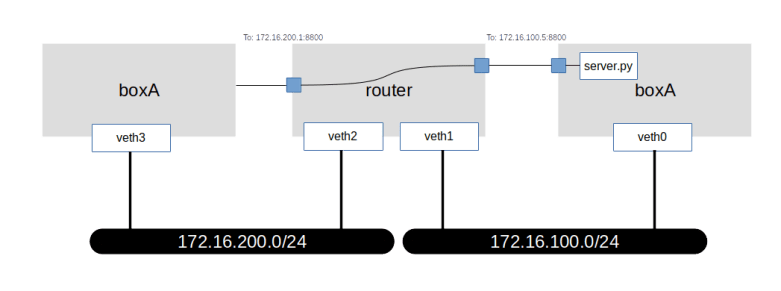




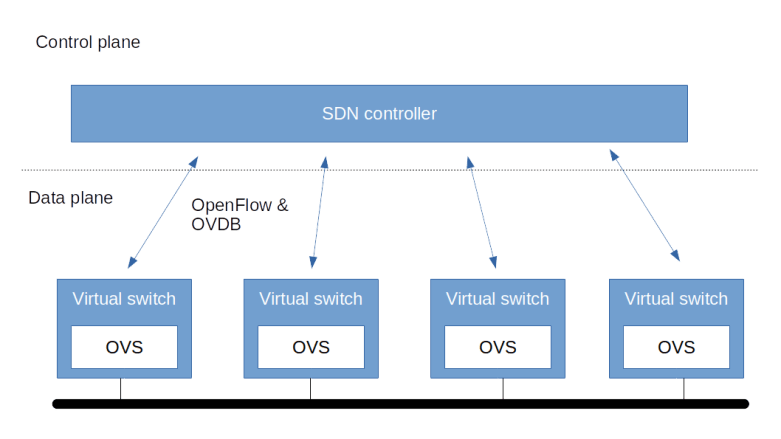
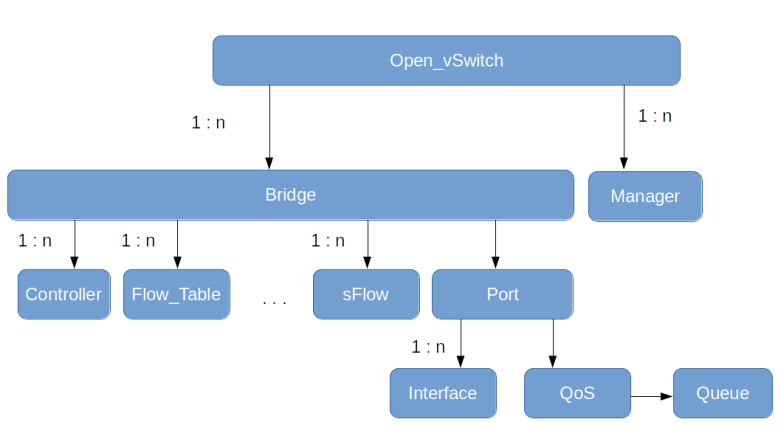

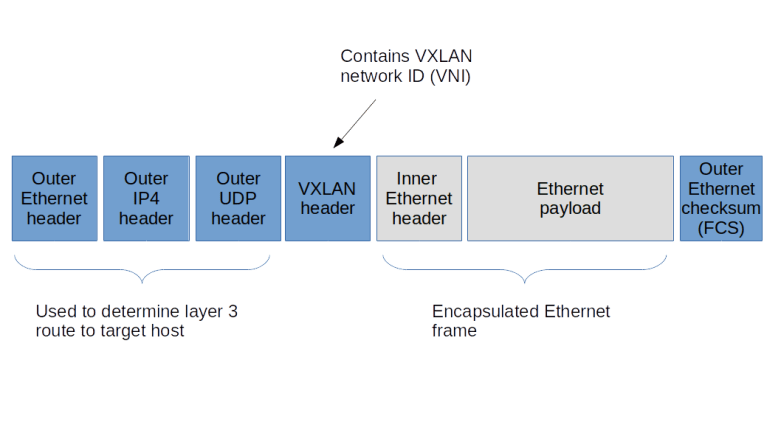
















{kind=link}