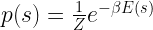
In the last post in the series on AI and machine learning, I have described the Boltzmann distribution which is a statistical distribution for the states of a system at constant temperature. We will now look at one of the most important applications of this distribution to an actual model, the Ising model.
This model was proposed by W. Lenz and first analysed in detail by his student E. Ising in his dissertation (of which [1] is a summary) to explain ferromagnetic behavior. In Isings model, a solid, like a piece of iron, is composed of a large number N of individual particles, each of them at a fixed location. A particle acts as a magnetic dipole that can be oriented in two different ways, corresponding to the different orientations of its spin. Ignoring the spatial structure for the time being, we can thus describe the state of the model as a point in the state space

We denote the elements of the state space by s and the i-th spin by 
Now, in general, a magnetic dipole which is exposed to a magnetic field B and has a magnetic dipole moment m will have a potential energy

which is the scalar product of m and B, i.e. the state of minimum energy is the one where the dipole is oriented along the magnetic field. In a solid, there are two sources for the magnetic field that act on each particle – there might be an external magnetic field H and there might be an interaction with the other magnetic dipoles in the model. We therefore model the total energy of a state s as

where 
Here the coefficient 
We now consider the system as being in contact with a heat bath at a certain temperature T, i.e. the system can exchange internal energy with a thermal reservoir, leading to fluctuations in the orientations of the particles. This appears to be a reasonable model, we could, for instance, consider a comparatively small part of a solid and take the surrounding, much larger solid as the heat bath. The probability for the system to be in a state s is therefore given by the Boltzmann distribution:

The macroscopic quantities that are of primary interest are of course the average energy, but also the magnetization
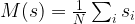
and its average value. At high temperatures and for H = 0, we expect that roughly half of the spins should be oriented in either direction, so the average magnetization should be zero. If we add an external field, then of course most of the dipoles will be aligned in the direction of this field, so the magnetization will be close to one or minus one. This fact – magnetization of a solid in the presence of an external magnetic field – is called paramagnetism. It turns out that for some materials, a non-zero magnetization can occur even if the external field is zero, as long as the temperature is below a certain value called the critical temperature – this behavior is known as ferromagnetism. Explaining this macroscopic behavior by a statistical model was the original intention of Isings work.
Now how do we actually evaluate our model? Our aim is to determine – for instance – the average magnetization at a given temperature. To do this naively, we would have to calculate the probabilities for all possible states s. Unfortunately, the number of states grows exponentially with the number N of particles. Suppose we wanted to use a toy model with only 40 x 40 spins – this is very small compared to the number of particles in an average macroscopic solid. As N = 1600 in this case, we would have 


However, we can try to approximate the average magnetization by using a sufficiently large sample. Thus we try to find a set of states 

How, then, do you create that sample? The answer is easy to write down, but difficult to motivate without the necessary background on Markov chains. Thus I will simply state the algorithm which is called Gibbs sampling and leave the theoretical background to another post (for the mathematically inclined reader, it is worth mentioning that the sample produced by the Gibbs sampler is not independent, but the law of large number still holds).
Before we can phrase the algorithm, we need another preparational step – we need to calculate a conditional probability. Suppose that the system is in a state s and we have chosen an arbitrary coordinate i. We can then ignore the actual state of the spin

Here 
- Randomly pick a coordinate i
- Calculate the conditional probability
using the formula above
- Draw a real number U between 0 and 1 from the uniform distribution
- If U is at most equal to P, set the spin at position i to +1, otherwise set it to -1
The algorithm then starts with a randomly chosen state and subsequently applies a large number of Gibbs sampling steps. After some time, called the burn-in time, the states after each step then form the sample we are looking for.
After all that theory, let us now turn to the practical implementation. We will restrict ourselves to the original model, i.e. 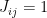
$ git clone https://github.com/christianb93/MachineLearning.git
In the newly created directory MachineLearning, you should then see a file Ising.py. Run this as follows.
$ python IsingModel.py
This will create a new temporary directory with a name that is unique and specifies the run (on Linux / Unix systems, you will find the newly created directory in /tmp/. In this subdirectory, you will find three files. A file with extension .txt summarizes the parameters of the run. The file that ends with IsingPartI.png displays the simulation results. An example is

Each of the little images represents one final state for a given temperature. In this example, a grid of 40 x 40 spins was calculated. The temperature was slowly decreased from 6.0 down to 0.2 in steps of 0.2. For each temperature, 4 million simulation steps were done, then the resulting grid was captured. The top row represents, from the left to the right, the temperatures 6.0, 5.8, 5.6, 5.4 and 5.2. Here we see the expected behaviour – patterns with roughly half of the particles in a spin-up position and half of the particles in a spin-down orientation.
In the bottom row of the diagram, that corresponds to the temperatures 1.0, 0.8, 0.6, 0.4 and 0.2, we also see the expected behavior for very low temperatures – all spins are oriented in the same direction. However, starting at temperatures 1.8, we see that large scale patterns start to emerge. especially for the temperatures 2.2 and 2.4 (rightmost pictures in the fourth row from the top). For these temperatures, entire connected regions display the same orientation of the spins and thus a non-zero mean magnetization. As the temperature rises, these patterns dissolve again.
This behaviour is typical for a so-called critical point and is what Ising was searching for. Ironically, Ising, who of course did not have the computational devices to run a simulation, concluded in his paper wrongly that this would not happen. Critical points are of great interest not only in statistical mechanics, but also in quantum field theory – we will not be able to explore this connection further, but it demonstrates how important the Ising model has become as a playground to bring together various branches from physics, computer science and mathematics.
The program has lots of parameters to play with – with the default values, for instance, it calculates comparatively small grids with 20 x 20 spins, so that a small number of iterations is sufficient, for larger grids you will need several million iterations. I recommend to play with this a bit to get a feeling for what happens. The image at the top of this article, for instance, was generated with the following command line:
$ python IsingModel.py --show=1 --N=160000 --rows=400 --cols=400 --steps=100000 --Tmax=2.4 --Tmin=1.7
and ran for roughly 13 minutes on my PC.
It is worth mentioning that neither the Gibbs sampling algorithm nor the chosen implementation are optimized. In fact, there are other algorithms like the exact sampling algorithm (see for instance [2]) that are providing much better results, and also the implementation could be improved greatly, for instance by using a Metropolis-Hastings checkerboard algorithm to allow for high parallelization and GPU computing (see for instance [3]). However, as understanding Gibbs sampling is vital for understanding Boltzmann machines, I have chosen to use a down-to-earth Gibbs sampling approach for this post – after all, its main purpose is not to gain new physical insights from simulation results but to get acquainted with Gibbs sampling as a standard sampling method, and, as always, to have some fun.
If you would like to learn more on the Ising model, please have a look at my notes that provide more details, show how to compute the conditional probability used for the Gibbs sampling and also cover the one-dimensional Ising model.
In the meantime, you might want to take a look at the beautiful article of J. Harder on WordPress who has some more sample pictures and a very interesting application of convolutional neuronal networks that he trained to be able to determine the temperatue at which the simulation was run from the visual representation of the simulation result.
References
1. E. Ising, Beitrag zur Theorie des Ferromagnetismus,
Zeitschrift f. Physik, Vol. 31, No.1 (1924), 253-258
2. D. MacKay, Information Theory, Inference and Learning Algorithms, Cambridge University Press, Cambridge 2003
3. M. Weigel, Simulating spin models on GPU, Computer Physics Communication 182 (2011), 1833-1836


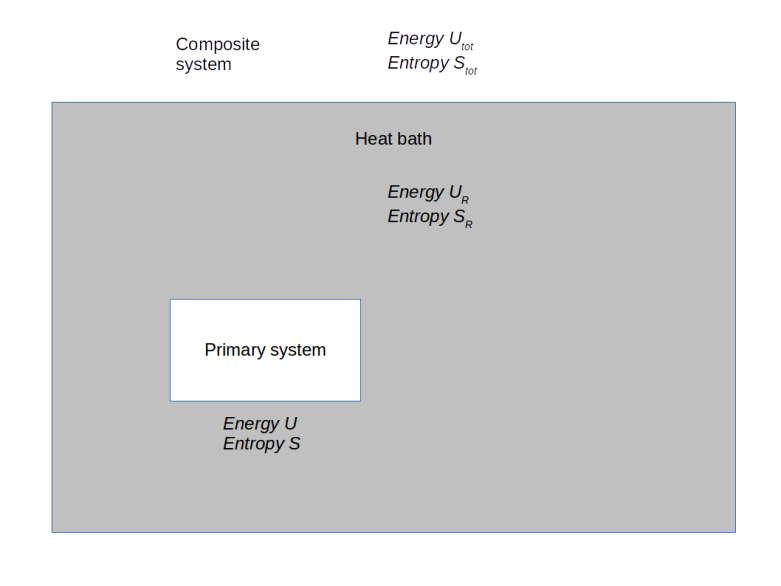
 , its entropy by
, its entropy by  , the energy of the heat bath by
, the energy of the heat bath by  and the entropy of the heat bath by
and the entropy of the heat bath by  (if energy and entropy are new concepts for you, I recommend my short
(if energy and entropy are new concepts for you, I recommend my short  . Let us denote the number of states of the heat bath with that energy by
. Let us denote the number of states of the heat bath with that energy by
 denote the number of states of the composite system with energy
denote the number of states of the composite system with energy  , because every such state combines with s to an admissible state of the composite system. If all these states are equally likely, the probability for s is therefore just the fraction of these states among all possible states of the composite system, i.e.
, because every such state combines with s to an admissible state of the composite system. If all these states are equally likely, the probability for s is therefore just the fraction of these states among all possible states of the composite system, i.e.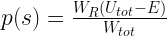

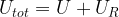
![W_{tot} = \exp \frac{1}{k} \left[ S(U) + S_R(U_{tot} - U) \right]](https://s0.wp.com/latex.php?latex=W_%7Btot%7D+%3D+%5Cexp+%5Cfrac%7B1%7D%7Bk%7D+%5Cleft%5B+%C2%A0+%C2%A0S%28U%29+%2B+S_R%28U_%7Btot%7D+-+U%29+%C2%A0+%C2%A0%5Cright%5D++&bg=FFFFFF&fg=000&s=1&c=20201002)
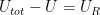 . The first derivative of the entropy with respect to the energy is – by definition – the inverse of the temperature:
. The first derivative of the entropy with respect to the energy is – by definition – the inverse of the temperature:
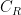 of the reservoir. In fact, we have
of the reservoir. In fact, we have

![p(s) = \exp \frac{1}{kT} \left[ (U - TS(U)) - E(s) \right]](https://s0.wp.com/latex.php?latex=p%28s%29+%3D+%5Cexp+%5Cfrac%7B1%7D%7BkT%7D+%5Cleft%5B+%28U+-+TS%28U%29%29+-+E%28s%29+%5Cright%5D++&bg=FFFFFF&fg=000&s=1&c=20201002)
 is the Helmholtz energy
is the Helmholtz energy 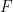 . If we also introduce the usual notation
. If we also introduce the usual notation 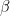 for the inverse of
for the inverse of 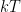 , we finally find that
, we finally find that