In this post, we will use the Kubernetes code generator to create client code and informers which will allow us to set up the basic event handlers for our customer controller.
Before we start to dig into this, note that compared to my previous post, I had to make a few changes to the CRD definition to avoid dashes in the name of the API group. The updated version of the CRD definition looks as follows.
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: bitcoinnetworks.bitcoincontroller.christianb93.github.com
spec:
version: v1
group: bitcoincontroller.christianb93.github.com
scope: Namespaced
subresources:
status: {}
names:
plural: bitcoinnetworks
singular: bitcoinnetwork
kind: BitcoinNetwork
validation:
openAPIV3Schema:
properties:
spec:
required:
- nodes
properties:
nodes:
type: integer
Step 5: running the code generators
Of course we will use the Kubernetes code generator to generate the code for the clientset and the informer. To use the code generator, we first need to get the corresponding packages from the repository.
$ go get k8s.io/code-generator $ go get k8s.io/gengo
The actual code generation takes place in three steps. In each step, we will invoke one of the Go programs located in $GOPATH/src/k8s.io/code-generator/cmd/ to create a specific set of objects. Structurally, these programs are very similar. They accept a parameter that specifies certain input packages that are scanned. They then look at every structure in these packages and detect tags, i.e. comments in a special format, to identify those objects for which they need to create code. Then they place the resulting code in an output package that we need to specify.
Fortunately, we only need to prepare three inputs files for the code generation – the first one is actually scanned by the generators for tags, the second and third file have to be provided to make the generated code compile.
- In the package apis/bitcoincontroller/v1, we need to provide a file types.go in which define the Go structures corresponding to our CRD – i.e. a BitcoinNetwork, the corresponding list type BitcoinNetworkList, a BitcoinNetworkSpec and a BitcoinNetworkStatus. This is also the file in which we need to place our tags (as the scan is based on package structures, we could actually call our file however we want, but following the usual conventions makes it easier for third parties to read our code)
- In the same directory, we will place a file register.go. This file defines some functions that will later be called by the generated code to register our API group and version with a scheme
- Finally, there is a second file register.go which is placed in apis/bitcoincontroller and defines a constant representing the fully qualified name of the API group
We first start with the generator that creates the code to create deep copies for our API objects. In this case, we mark the structures for which code should be generated with the tag +k8s.deepcopy-gen=true (which we could also do on package level). As we also want to create DeepCopyObject() methods for these structures, we also add the additional tags
+k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
Then we invoke the code generator using
go run $GOPATH/src/k8s.io/code-generator/cmd/deepcopy-gen/main.go \ --bounding-dirs github.com/christianb93/bitcoin-controller/internal/apis \ --input-dirs github.com/christianb93/bitcoin-controller/internal/apis/bitcoincontroller/v1
By default, the generator will place its results in a file deepcopy_generated.go in the input directory. If you run the controller and open the file, you should find the generated code which is not hard to read and does in fact simply create deep copies. For a list, for instance, it creates a new list and copies item by item. As our structures are not deeply nested, the code is comparatively straightforward. If something goes wrong, you can add the switch --v 5 to increase the log level and obtain additional debugging output.
The second code generator that we will use is creating the various clients that we need – a clientset for our new API group and a client for our new resource. The structure of the command is similar, but this time, we place the generated code in a separate directory.
go run $GOPATH/src/k8s.io/code-generator/cmd/client-gen/main.go \ --input-base "github.com/christianb93/bitcoin-controller/internal/apis" \ --input "bitcoincontroller/v1" \ --output-package "github.com/christianb93/bitcoin-controller/internal/generated/clientset" \ --clientset-name "versioned"
The first two parameters taken together define the package that is scanned for tagged structures. This time, the magic tag that will cause a structure to be considered for code generation is +genclient. The third parameter and the fourth parameters similarly define where the output will be placed in the Go workspace. The actual package name will be formed from this output path by appending the name of the API group and the version. Make sure to set this variable, as the default will point into the Kubernetes package and not into your own code tree (it took me some time to figure out the exact meaning of all these switches and a few failed attempts plus some source code analysis – but this is one of the beauties of Go – all the source code is at your fingertip…)
When you run this command, it will place a couple of files in the directory $GOPATH/src/github.com/christianb93/bitcoin-controller/internal/generated/clientset. With these files, we have now all the code in place to handle our objects via the API – we can create, update, get and list our bitcoin networks. To list all existing bitcoin networks, for instance, the following code snippet will work (I have skipped some of the error handling code to make this more readable).
import (
"fmt"
"path/filepath"
bitcoinv1 "github.com/christianb93/bitcoin-controller/internal/apis/bitcoincontroller/v1"
clientset "github.com/christianb93/bitcoin-controller/internal/generated/clientset/versioned"
"k8s.io/client-go/tools/clientcmd"
"k8s.io/client-go/util/homedir"
)
home := homedir.HomeDir()
kubeconfig := filepath.Join(home, ".kube", "config")
config, err := clientcmd.BuildConfigFromFlags("", kubeconfig)
// Create BitcoinNetwork client set
c, err := clientset.NewForConfig(config)
client := c.BitcoincontrollerV1()
list, err := client.BitcoinNetworks("default").List(metav1.ListOptions{})
for _, item := range list.Items {
fmt.Printf("Have item %s\n", item.Name)
}
This code is very similar to the code that we have used in one of our first examples to list pods and nodes, with the only difference that we are now using our generated packages to create a clientset. I have written a few tests to verify that the generated code works.
To complete our code generation, we now have to generate listers and informers. The required commands will first generate the listers package and then the informers package that uses the listers.
go run $GOPATH/src/k8s.io/code-generator/cmd/lister-gen/main.go \ --input-dirs "github.com/christianb93/bitcoin-controller/internal/apis/bitcoincontroller/v1"\ --output-package "github.com/christianb93/bitcoin-controller/internal/generated/listers" go run $GOPATH/src/k8s.io/code-generator/cmd/informer-gen/main.go \ --input-dirs "github.com/christianb93/bitcoin-controller/internal/apis/bitcoincontroller/v1"\ --versioned-clientset-package "github.com/christianb93/bitcoin-controller/internal/generated/clientset/versioned"\ --listers-package "github.com/christianb93/bitcoin-controller/internal/generated/listers"\ --output-package "github.com/christianb93/bitcoin-controller/internal/generated/informers"
You can find a shell script that runs all necessary commands here.
Again, we can now use our listers and informers as for existing API objects. If you want to try this out, there is also a small test set for this generated code.
Step 6: writing the controller skeleton and running first tests
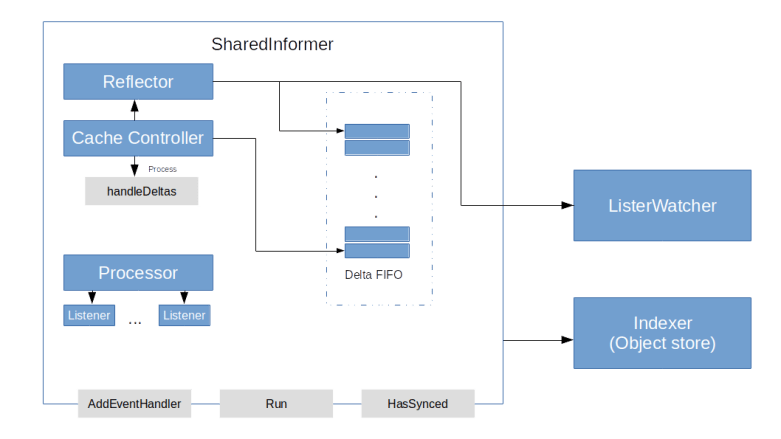
We can now implement most of the code of the controller up to the point where the actual business logic kicks in. In main.go, we create a shared informer and a controller object. Within the controller, we add event handlers to this informer that put the events onto a work queue. Finally, we create worker threads that pop the events off the queue and trigger the actual business logic (which we still have to implement). If you have followed my previous posts, this code is straightforward and does not contain anything new. Its structure at this point in time is summarized in the following diagram.

We are now in a position to actually run our controller and test that the event handlers are called. For that purpose, clone my repository into your workspace, make sure that the CRD has been set up correctly in your cluster and start the controller locally using
$ go run $GOPATH/src/github.com/christianb93/bitcoin-controller/cmd/controller/main.go --kubeconfig "$HOME/.kube/config"
You should now see a few messages telling you that the controller is running and has entered its main loop. Then, in a second terminal, create a test bitcoin network using
$ kubectl apply -f https://raw.githubusercontent.com/christianb93/bitcoin-controller/master/deployments/testNetwork.yaml
You should now see that the ADD handler has been called and see a message that the worker thread has popped the resulting event off the work queue. So our message distribution scheme works! You will also see that even though there are no further changes, update events are published every 30 seconds. The reason for this behaviour is that the cache is resynced every 30 seconds which will push the update events. This can be useful to make sure that a reconciliation is done every 30 seconds, which might heal a potentially incorrect state which was the result of an earlier error.
This is nice, but there is a problem which becomes apparent if you now try to package our code in a container and run it inside the cluster as we have done it at the end of our previous post. This will not produce the same output, but error messages ending with “cannot list resource “bitcoinnetworks” in API group “bitcoincontroller.christianb93.github.com” at the cluster scope”.
The reason for this is that the pod is running with the default service account, and this account does not have the privileges to read our resources. In the next post, we will see how role based access control comes to the rescue.
As before, I have created the tag v0.2 to reflect the status of the code at the end of this post.