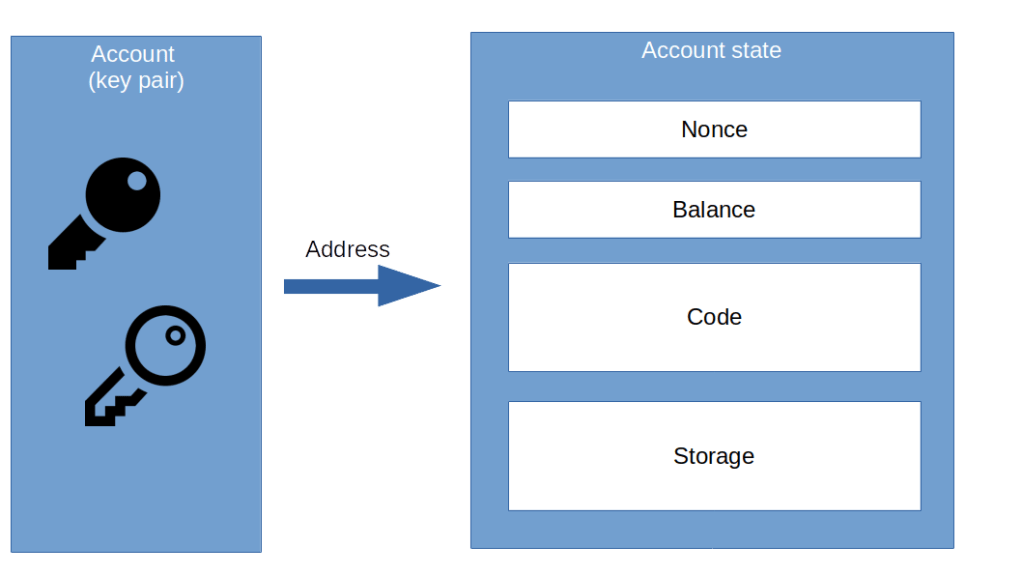
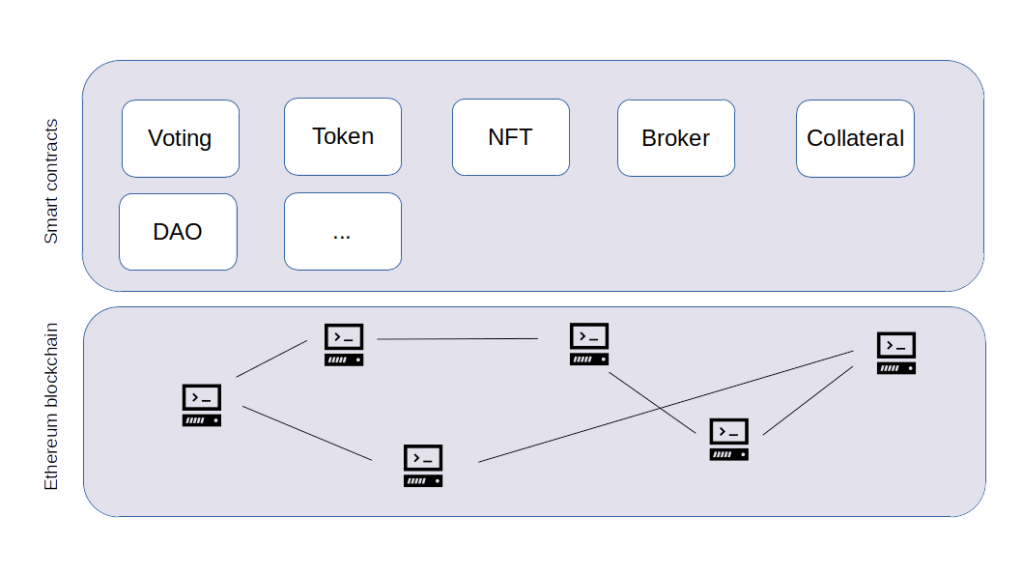
What is a token? The short answer is that a token is a smart contract that records and manages ownership in a digital currency. The long answer is in this post.
Building a digital currency – our first attempt
Suppose for a moment you wanted to issue a digital currency and were thinking about the design of the required software package. Let us suppose further that you have never heard of a blockchain before. What would you probably come up with?
First, you would somehow need to record ownerhip. In other words, you will have to store balances somewhere, and associate a balance to every participant or client in the system, represented by an account. In a traditional IT, this would imply that somewhere, you fire up a database, maybe a relational database, that has a table with one row per account holding the current balance of this account.
Next, you would need a function that allows you to query the balance, something like balanceOf, to which you pass an account and with returns the balance of this account, looking up the value in the database. And finally, you would want to make a transfer. So you would have a method transfer which the owner of an account can use to transfer a certain amount to another account. This method would of course have to verify that whoever calls it (say you expose it as an API) is the holder of the account from which the transfer is made, which could be done using certificates or digital signatures and is well possible with traditional technology. So your first design would be rather minimalistic.
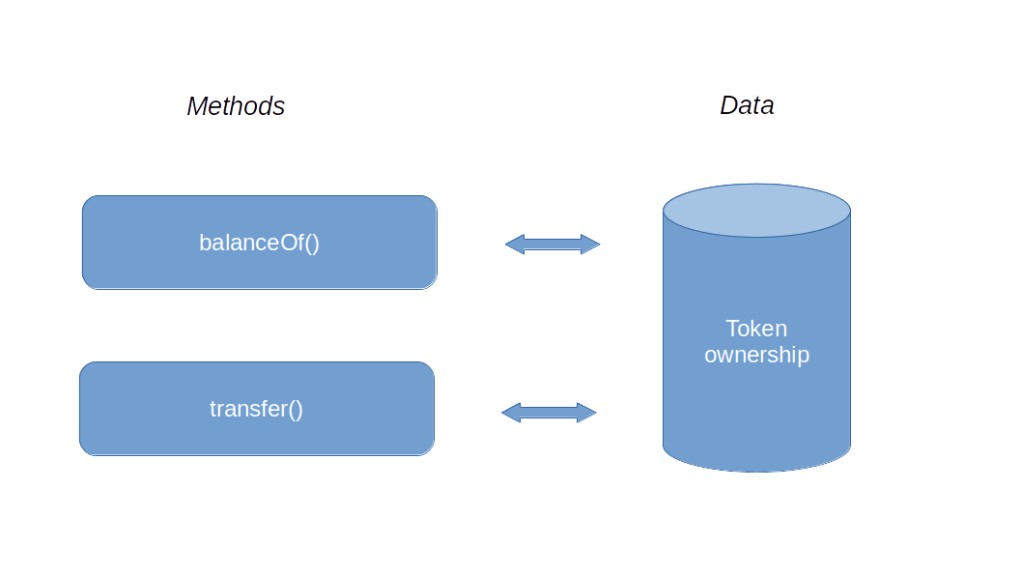
This would probably work, but is not yet very powerful. Let us add a direct debit functionality, i.e. let us allow users to withdraw a pre-approved amount of money from an account. To realize this, you could come up with a couple of additional functions.
- First, you would add a function
approve()that the owner of an account can invoke to grant permission to someone else (identified again by an account) to withdraw a certain amount of currency - You would probably also want to store these approvals in the database and add a function
approval()to read them out - Finally, you would add a second function – say
transferFrom– to allow withdrawals
Updating your diagram, you would thus arrive at the following design for your digital currency.
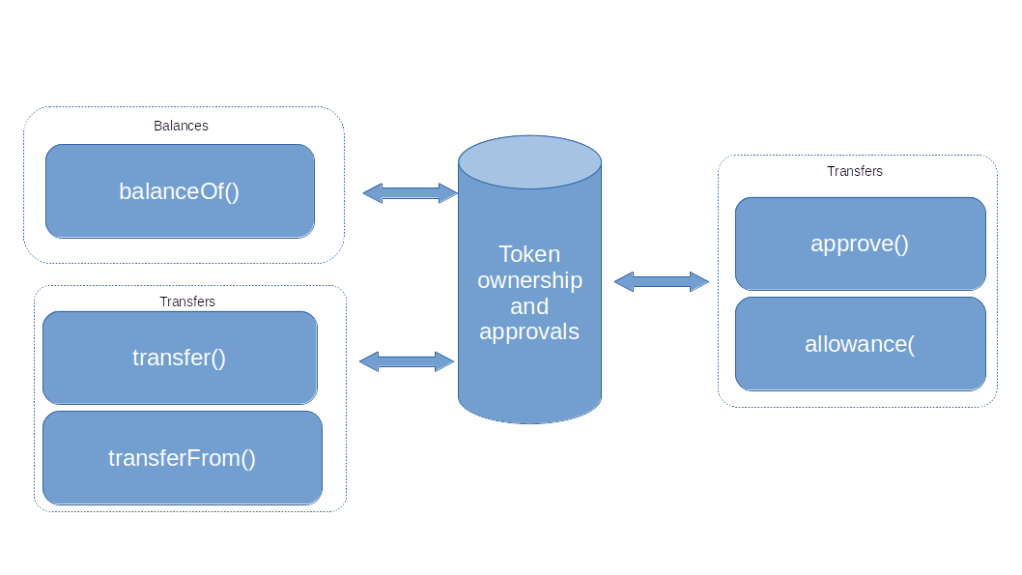
This is nice, but it still has a major drawback – someone will eventually need to operate the database and the application, and could theoretically manipulate balances and allowances directly in the database, bypassing all authorizations. The same person could also try to manipulate the code, building in backdoors or hidden transfers. So this system only qualifies as an acceptable digital currency if it is embedded into a system of regulations and audits that tries to avoid these sort of manipulations.
The ERC20 token standard
Now suppose further that you are still sitting in at your desk and scratching your head, thinking about this challenge when someone walks into your office and tells you that a smart person has just invented a technology called blockchain that allows you to store data in way that makes it extremely hard to manipulate it and also allows you to store and run immutable programs called smart contracts. Chances are that this would sound like the perfect solution to you. You would dig into this new thing, write a smart contract that stores balances and approvals in its storage on the blockchain and whose methods implement the functions that appear in your design, and voila – you have implemented your first token.
Essentially, this is how a token works. A token is a smart contract that, in its storage, maintains a data structure mapping accounts to balances, and offers methods to transfer digital currency between accounts, thus realizing a digital currency on top of Ethereum. These “sub-currencies” were among the first applications of smart contracts, and attempts to standardize these contracts have already been started in 2015, shortly after the Ethereum blockchain was launched (see for instance this paper cited by the later standard). The final standard is now known as ERC20.
I strongly advise you to take a look at the standard itself, which is actually quite readable. In addition to the functions that we have already discussed, it defines a few optional methods to read token metadata (like its name, a symbol and how to display decimals), a totalSupply method that returns the total number of token emitted and events that fire when approvals are made or token are transferred. Here is an overview of the components of the standard.
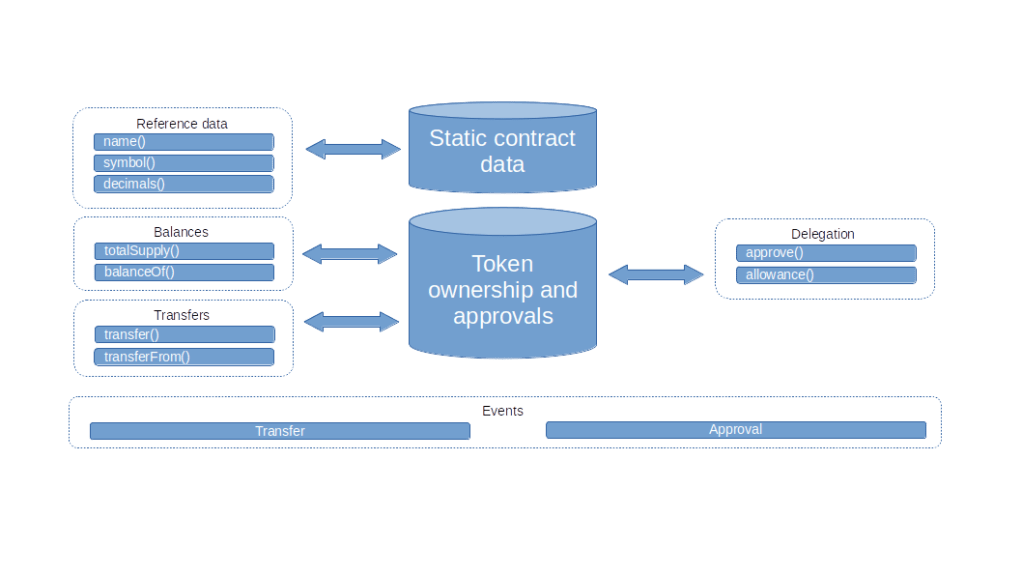
Note that it is up to the implementation whether the supply of token is fixed or token can be created (“minted”) or burnt. The standard does, however, specify that an implementation should emit an event if this happens.
Coding a token in Solidity
Let us now discuss how to implement a token according to the ERC20 standard in Solidity. The code for our token can be found here. Most of it is straightforward, but there is a couple of features of the Solidity language that we have not yet come across and that require explanation.
First, let us think about the data structures that we will need. Obviously, we somehow need to store balances per account. This calls for a mapping, i.e. a set of key-value pairs, where the keys are addresses and the value for a given address is the balance of this address, i.e. the number of token owned by this address. The value can be described by an integer, say a uint256. The address is not simply a string, as Solidity has a special data type called address. So the data structure to hold the balances is declared as follows.
mapping(address => uint256) private _balances;
Mappings in Solidity are a bit special. First, there is no way to visit all elements of a map like this, i.e. there nothing like x.keys() to get a list of all keys that appear in the mapping. Solidity will also allow you to access an element of a mapping that has not been initialized, this will return the default value for the respective data type, i.e. zero in our case. Thus, logically, our mapping covers all possible addresses and assigns an initial balance zero to them.
A similar mapping can be used to track allowances. This is a mapping whose values are again mappings. The first key (the key of the top-level mapping) is the owner of the account, the second key is the address authorized to perform a transfer (called the spender) , and the value is the allowance.
mapping (address => mapping (address => uint256)) private _allowance;
The next mechanism that we have not yet seen is the constructor which will be called when the contract is deployed. We use it to initialize some variables that we will need later. First, we store the msg.sender which is one of the pre-defined variables in Solidity and is the address of the account that invoked the constructor, i.e. in our case the account that deployed the contract. Note that msg.sender refers to the address of the EOA or contract that is the immediate predecessor of the contract in the call chain. In contrast to this, tx.origin is the EOA that signed the transaction. In the constructor, we also set up the initial balance of the token owner.
The remaining methods are straightforward, with one exception – validations. Of course, we need to validate a couple of things, for instance that the balance is sufficient to make a transfer. Thus we would check a condition, and, depending on the boolean value of that condition, revert the transaction. This combination is so common that Solidity has a dedicated instruction to do this – require. This accepts a boolean expression and a string, and, if the expression evaluates to false, reverts using the string as return value. Unfortunately, it is currently not possible for an EOA to get access to the return value of a reverted transaction, as this data is not part of the transaction receipt (see EIP-658 and EIP-758 for some background on this), but this is possible if you make a call to the contract.
This raises an interesting question. In some unit tests, for instance in this one that I have written to test my token implementation, we test whether a transaction reverts by assuming that submitting a transaction raises a Python exception. For instance, the following lines
with brownie.reverts("Insufficient balance"):
token.transfer(alice.address, value, {"from": me.address});
verify that the transfer method of our token contract actually reverts with an expected message. Now we have just seen that the message is not part of the transaction receipt – how does Brownie know? It turns out that the handling of reverted transactions in the various frameworks is a bit tricky, in this case this works because we do not provide a gas limit – I will dive a bit deeper into the mechanics of revert in a later post.
Testing the token using MetaMask
Let us now deploy and test our token. If you have not done so, clone my repository, set up a Brownie project directory, add symbolic links to the contracts and test cases and run the tests.
git clone https://github.com/christianb93/nft-bootcamp
cd nft-bootcamp
mkdir tmp
cd tmp
brownie init
cd contracts
ln ../../contracts/Token.sol .
cd ../tests
ln ../../tests/test_Token.py
cd ..
brownie test
Assuming that the unit tests complete successfully, we can use Brownie to deploy a copy of the token as usual (or any of the alternative methods discussed in previous posts)
brownie console
me = accounts[0]
token = Token.deploy({"from": me})
token.balanceOf(me)
At this point, the entire supply of token is allocated to the contract owner. To play with MetaMask, we need two additional accounts of which we know the private keys. Let us call them Alice and Bob. Enter the following commands to create these accounts and make sure to write down their addresses and private keys. We also transfer an initial supply of 1000 token to Alice and equip Alice with some Ether to be able to make transactions.
alice = accounts.add()
alice.private_key
alice.address
bob = accounts.add()
bob.private_key
bob.address
token.transfer(alice, 1000, {"from": me})
me.transfer(alice, web3.toWei(1, "ether"))
alice.balance()
Next, we will import or keys and token into MetaMask. If you have not done this yet, go ahead and install the MetaMask extension for your browser. You will be directed to the extension store for your browser (I have been using Chrome, but Firefox should work as well). Add the extension (you might want to use a separate profile for this). Then follow the instructions to create a new wallet. Set a password to protect your wallet and save the seed phrase somewhere.
You should now see the MetaMask main screen in front of you. At the right hand side at the top of the screen, you should see a switch to select a network. Click on it and select “Localhost 8545” to connect to the – still running – instance of Ganache. Then, click on the icon next to the network selector and import the account of Alice by entering the private key. You should now see a new account (for me, this was “Account 2”) with the balance of 1 ETH.
Next, we will add the token. Click on “Add Token”, collect the contract address from brownie (token.address) and enter it. You should now see a balance of “10 MTK”. Note how MetaMask uses the decimals – Alice owns 1000 token, and we have set the decimals (the return value of token.decimals()) to two, so that MetaMask interprets the last two zeros as decimals and displays ten.
Now let us use MetaMask to make a transfer – we will send 100 token to Bob. Click on “Send” and enter the address of Bob. Now select 1 MTK (remember the decimals again). Confirm the transaction. After a few seconds, MetaMask should inform you that the transaction has been mined. You will also see that the balance of Alice in ETH has decreased slightly, as she needed to pay for the gas, and her MTK balance has been decreased. Finally, switch back to Brownie and run
token.balanceOf(bob)
to confirm that Bob is now proud owner of 100 token.
Today, we have discussed the structure of a token contract, introduced you to the ERC20 standard, presented an implementation in Solidity and verified that this contract is able to interact with the MetaMask wallet as expected. In the next post, we will discuss a few of the things that can go terribly wrong if you implement smart contracts without thinking about the potential security implications of your design decisions.