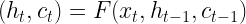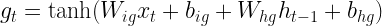In the previous post, we have discussed how attention can be applied to avoid bottlenecks in encoder-decoder architectures. In transformer-based models, attention appears in different flavours, the most important being what is called self-attention – the topic of todays post. Code included.
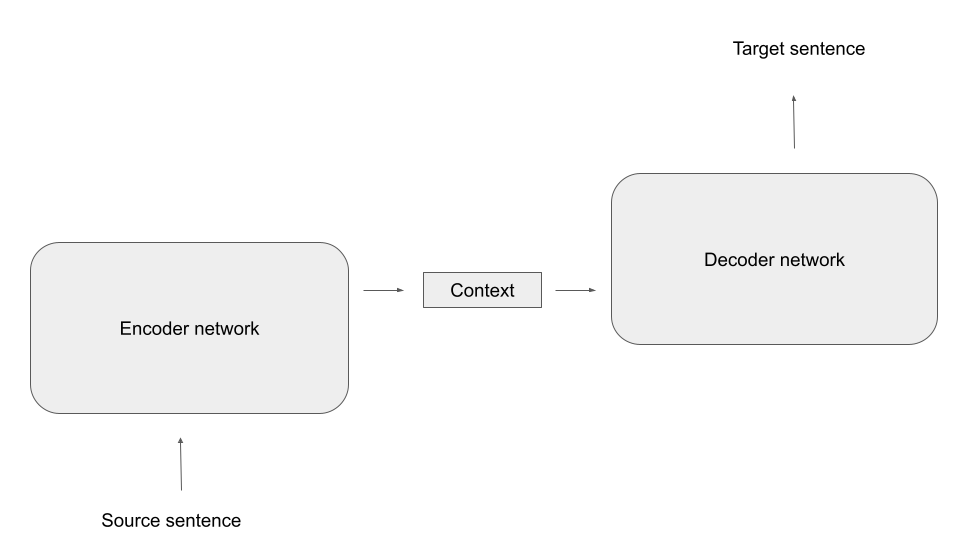
Before getting into coding, let us first describe the attention mechanism presented in the previous blog in a bit more general setting and, along the way, introduce some terminology. Suppose that a neural network has access to a set of vectors vi that we call the values. The network is aiming to process the information contained in the vi in a certain context and, for that purpose, needs to condense the information specific to that context into a single vector. Suppose further that each vector vi is associated with a vector ki called the key, that somehow captures which information the vector vi contains. Finally assume that we are able to form a query vector q that specificies what information the network needs. The attention mechanism will then assemble a linear combination

called the attention vector.
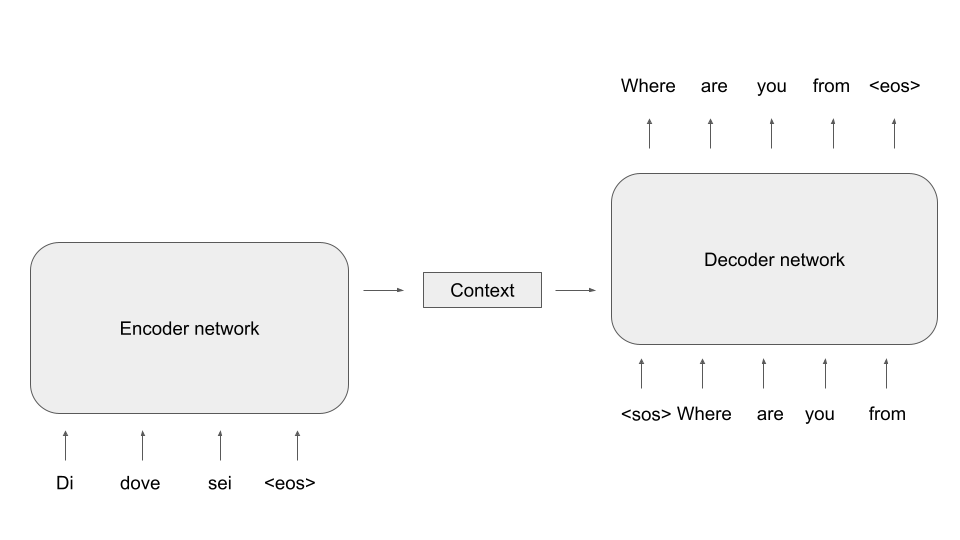
To make this more tangible, let us look at an example. Suppose an encoder processes a sequence of words, represented by vectors xi. While encoding a part of the sentence, i.e. a specific vector, the network might want to pull in some data from other parts of the sentence. Here, the query would be the currently processed word, while keys and values would come from other parts of the same sentence. As keys, queries and values all come from the same sequence, this form of attention is called self-attention. Suppose, for example, that we are looking at the sentence (once again taken from “War and peace”)
The prince answered nothing, but she looked at him significantly, awaiting a reply
When the model is encoding this sentence, it might help to pull in the representation of the word “prince” when encoding “him”, as here, “him” refers to “the prince”. So while processing the token for “him”, the network might put together an attention vector focusing mostly on the token for “him” itself, but also on the token for “prince”.

In this example, we would compute keys and values from the input sequence, and the query would be computed from the word we are currently encoding, i.e. “him”. A weight is then calculated for each combination of key and query, and these weights are used to form the attention vector, as indicated in the diagram above (we will see in a minute how exactly this works).
Of course, this only helps if the weights that we use in that linear combination are somehow helping the network to focus on those values that are most relevant for the given key. At the same time, we want the weights to be non-negative and to sum up to one (see this paper for a more in-depth discussion of these properties of the attention weights which are a bit less obvious). The usual approach to realize this is to first define a scoring function

and then obtain the attention weights as a softmax function applied to these scores, i.e. as

For the scoring function itself, there are several options (see Effective Approaches to Attention-based Neural Machine Translation by Luong et al. for a comparison of some of them). Transformers typically use a form of attention called scaled dot product attention in which the scores are computed as

i.e. as the dot product of query and key divided by the square root of the dimension d of the space in which queries and keys live.
We have not yet explained how keys, values and queries are actually assembled. To do this and to get ready to show some code, let us again focus on self attention, i.e. queries, keys and values all come from the same sequence of vectors xi which, for simplicity, we combine into a single matrix X with shape (L, D), where L is the length of the input and D is the dimensionality of the model. Now the queries, keys and values are simply derived from the input X by applying a linear transformation, i.e. by a matrix multiplication, using a learnable set of matrices weights WQ (for the queries), WV (for the values) and WK (for the keys).

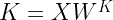

Note that the individual value, key and query vectors are now the rows of the matrices V, K and Q. We can therefore conveniently calculate all the scaled dot products in one step by simply doing the matrix multiplication

This gives us a matrix of dimensions (L, L) containing the scores. To calculate the attention vectors, we now still have to apply the softmax to this and multiply by the matrix V. So our final formula for the attention vectors (again obtained as rows of a matrix of shape (L, D)) is

In PyTorch, this is actually rather easy to implement. Here is a piece of code that initializes weight matrices for keys, values and queries randomly and defines a forward function for a self-attention layer.
wq = torch.nn.Parameter(torch.randn(D, D))
wk = torch.nn.Parameter(torch.randn(D, D))
wv = torch.nn.Parameter(torch.randn(D, D))
#
# Receive input of shape L x D
#
def forward(X):
Q = torch.matmul(X, wq)
K = torch.matmul(X, wk)
V = torch.matmul(X, wv)
out = torch.matmul(Q, K.t()) / math.sqrt(float(D))
out = torch.softmax(out, dim = 1)
out = torch.matmul(out, V)
return out
However, this is not yet quite the form of attention that is typically used in transformers – there is still a bit more to it. In fact, what we have seen so far is what is usually called an attention head – a single combination of keys, values and queries used to produce an attention vector. In real-world transformers, one typically uses several attention heads to allow the model to look for different patterns in the input. Going back to our example, there could be one attention head that learns how to model relations between a pronoun and the noun to which it refers. Other heads might focus on different syntactic or semantic aspects, like linking a verb to an object or a subject, or an adjective to the noun described by it. Let us now look at this multi-head attention.
The calculation of a multihead attention vector proceeds in three steps. First, we go through each of the heads which each has its own set of weight matrices (WQi, WKi, WVi) as before, and apply the ordinary attention mechanism that we have just seen to obtain a vector headi as attention vector for this head. Note that the dimension of this vector is typically not the model dimension D, but a head dimension dhead, so that the weight matrices now have shape (D, dhead). It is common, though not absolutely necessary, to choose the head dimension as the model dimension divided by the number of heads.
Next, we concatenate the output vectors of each head to form a vector of dimension nheads * dhead, where nheads is of course the number of heads. Finally, we now apply a linear transformation to this vector to obtain a vector of dimension D.

Here is a piece of Python code that implements multi-head attention as a PyTorch module. Note that here, we actually allow for two different head dimensions – the dimension of the value vector and the dimension of the key and query vectors.
class MultiHeadSelfAttention(torch.nn.Module):
def __init__(self, D, kdim = None, vdim = None, heads = 1):
super().__init__()
self._D = D
self._heads = heads
self._kdim = kdim if kdim is not None else D // heads
self._vdim = vdim if vdim is not None else D // heads
for h in range(self._heads):
wq_name = f"_wq_h{h}"
wk_name = f"_wk_h{h}"
wv_name = f"_wv_h{h}"
wq = torch.randn(self._D, self._kdim)
wk = torch.randn(self._D, self._kdim)
wv = torch.randn(self._D, self._vdim)
setattr(self, wq_name, torch.nn.Parameter(wq))
setattr(self, wk_name, torch.nn.Parameter(wk))
setattr(self, wv_name, torch.nn.Parameter(wv))
wo = torch.randn(self._heads*self._vdim, self._D)
self._wo = torch.nn.Parameter(wo)
def forward(self, X):
for h in range(self._heads):
wq_name = f"_wq_h{h}"
wk_name = f"_wk_h{h}"
wv_name = f"_wv_h{h}"
Q = X@getattr(self, wq_name)
K = X@getattr(self, wk_name)
V = X@getattr(self, wv_name)
head = Q@K.t() / math.sqrt(float(self._kdim))
head = torch.softmax(head, dim = -1)
head = head@V
if 0 == h:
out = head
else:
out = torch.cat([out, head], dim = 1)
return out@self._wo
We will see in a minute that this implementation works, but the actual implementation in PyTorch is a bit different. To see why, let us count parameters. For each head, we have three weight matrices of dimensionality (D, dhead), giving us in total
3 x D x dhead x nheads
parameters. If the head dimension times the number of heads is equal to the model dimension, this implies that the number of parameters is in fact 3 x D x D and therefore the same as if we head a single attention head with dimension D. Thus, we can organize all weights into a single matrix of dimension (D, D), and this is what PyTorch does, which makes the calculation much more efficient (and is also better prepared to process batched input, which our simplified code is not able to do).
It is instructive to take a look at the implementation of multi-head attention in PyTorch to see what happens under the hood. Essentially, PyTorch reshuffles the weights a bit to treat the head as an additional batch dimension. If you want to learn more, you might want to take a look at this notebook in which I go through the code and also demonstrate how we can recover the weights of the individual heads from the parameters in a PyTorch attention layer.
If you actually do this, you might stumble upon an additional feature that we have ignored so far – the attention mask. Essentially, the attention mask allows you to forbid the model to look at certain parts of the input when processing other parts of the input. To see why this is needed, let us assume that we want to use attention in the input of a decoder. When we train the decoder with the usual teacher forcing method, we provide the full sentence in the target language to the model. However, we of course need to prevent the model from simply peaking ahead by looking at the next word, which is the target label for the currently processed word, otherwise training is trivially successful but the network has not learned anything useful.
In an RNN, this is prevented by the architecture of the network, as in each time step, we only use the hidden state assembled from the previous time steps, plus the current input, so that network does not even have access to future parts of the sentence. In an attention-based model, however, the entire input is usually processed in parallel, so that the model could actually look at later words in the sentence. To solve this, we need to mask all words starting at position i + 1 when building the attention vector for word i, so that the model can only attend to words at positions less than or equal to i.
Technically, this is done by providing an additional matrix of dimension (L, L) as input to the self attention mechanism, called the attention mask. Let us denote this matrix by M. When the attention weights are computed, PyTorch does then not simply take the matrix product
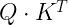
but does in fact add the matrix M before applying the softmax, i.e. the softmax is applied to (a scaled version of)

To prevent the model from attending to future words, we can now use a matrix M which is zero on the diagonal and below, but minus infinity above the diagonal, i.e. for the case L = 4:

As minus infinity plus any other floating point number is again minus infinity and the exponential in the softmax turns minus infinity into zero, this implies that the final weight matrix after applying the softmax is zero above the diagonal. This is exactly what we want, as it implies that the attention weights have the property
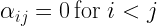
In other words, the attention vector for a word at position i is only assembled from this word itself and those to the left of it in the sentence. This type of attention mask is often called a causal attention mask and, in PyTorch, can easily be generated with the following code.
mask = torch.ones(L, L)
mask = torch.tril(mask*(-1)*float('inf'), diagonal = -1)
mask = mask.t()
print(mask)
This closes our post for today. We now understand attention, which is one of the major ingredients to a transformer model. In the next post, we will look at transformer blocks and explain how they are combined into encoder-decoder architectures.