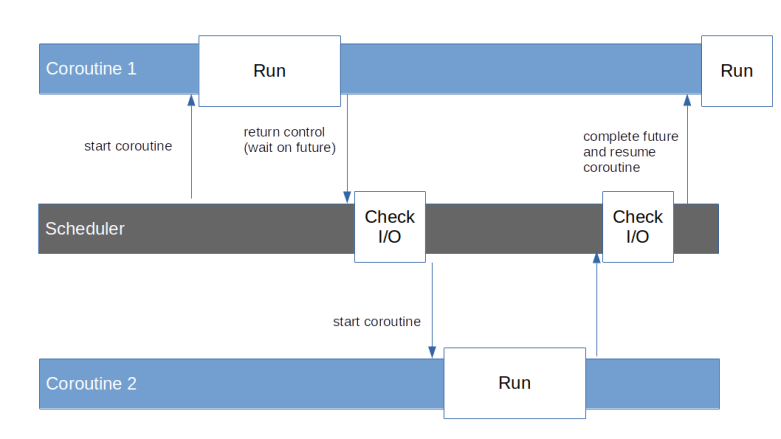
As explained in my previous post, historically coroutines in Python have evolved from iterators and generators, and understanding generators is still vital to understanding native coroutines. In this post, we take a short tour through iterators in Python and how generators have traditionally been implemented.
Iterables and iterators
In Python (and in other programming languages), an iterator is an object that returns a sequence of values, one at a time. While in languages like Java, iterators are classes implementing a specific interface, Python iterators are simply classes that have a method __next__ which is supposed to either return the next element from the iterator or raise a StopIteration exception to signal that no further elements exist.
Iterators are typically not created explicitly, but are provided by factory classes called iterables. An iterable is simply a class with a method __iter__ which in turn returns an iterator. Behind the scenes, iterables and iterators are used when you run a for-loop in Python – Python will first invoke the __iter__ of the object to which you refer in the loop to get an iterator and then call the __next__ method of this iterator once for every iteration of the loop. The loop stops when a StopIteration is raised.
This might sound a bit confusing, so let us look at an example. Suppose you wanted to build an object which – like the range object – allows you to loop over all numbers from 0 to a certain limit. You would then first write a class that implements a method __next__ that returns the next value (so it has to remember the last returned value), and then implement an iterable returning an instance of this class.
class SampleIterator:
def __init__(self, limit):
self._position = 0
self._limit = limit
def __next__(self):
if self._position < self._limit:
self._position += 1
return self._position - 1
else:
raise StopIteration
class SampleIterable:
def __init__(self, limit):
self._limit = limit
def __iter__(self):
return SampleIterator(self._limit)
myIterable = SampleIterable(10)
for i in myIterable:
print("i = %d" % i)
Often, the same object will implement the __next__ method and the __iter__ method and therefore act as iterable and iterator at the same time.
Note that the iterator typically needs to maintain a state – it needs to remember the state after the last invocation of __next__ has completed. In our example, this is rather straightforward, but in more complex siutations, programmatically managing this state can be tricky. With PEP-255, a new approach was introduced into Python which essentially allows a programmer to ask the Python interpreter to take over this state management – generators.
Generators in Python
The secret sauce behind generators in Python is the yield statement. This statement is a bit like return in that it returns a value and the flow of control to the caller, but with the important difference that state of the currently executed function is saved by Python and the function can be resumed at a later point in time. A function that uses yield in this way is called a generator function.
Again, it is instructive to look at an example. The following code implements our simple loop using generators.
def my_generator(limit=5):
_position = 0
while _position < limit:
yield _position
_position += 1
for i in my_generator(10):
print("i = %d" % i)
We see that we define a new function my_generator which, at the first glance, looks like an ordinary function. When we run this function for the first time, it will set a local variable to set its current position to zero. We then enter a loop to increase the position until we reach the limit. In each iteration, we then invoke yield to return the current position back to the caller.
In our main program, we first call my_generator() with an argument. As opposed to an ordinary function, this invocation does not execute the function. Instead, it evaluates the argument and builds and returns an object called a generator object. This object is an iterator, i.e. it has a __next__ method. When this method is called for the first time, the execution of our function body starts until it hits the first yield statement. At this point, the execution returns to the caller and whatever we yield is returned by the call to __next__. When now __next__ is invoked again, the Python interpreter will restore the current state of the function and resume its execution after the yield. We increase our internal position, enter the loop again, hit the next yield and so forth. This continues until the limit is reached. Then, the function returns, which is equivalent to raising a StopIteration and signals to the caller that the iterator is exhausted.
Instead of using the for loop, we can also go through the same steps manually to see how this works.
generator = my_generator(5)
while True:
try:
value = generator.__next__()
print("Value: %d" % value)
except StopIteration:
break
This is already quite close to the programming model of a co-routine – we can start a coroutine, yield control back to the caller and resume execution at a later point in time. However, there are a few points that are still missing and that have been added to Python coroutines with additional PEPs.
Delegation to other coroutines
With PEP-380, the yield from statement was added to Python, which essentially allows a coroutine to delegate execution to another coroutine.
A yield from statement can delegate either to an ordinary iterable or to another generator.
What yield from is essentially doing is to retrieve an iterator from its argument and call the __next__ method of this iterator, thus – if the iterable is a generator – running the generator up to the next yield. Whatever this yield returns will then be yielded back to the caller of the generator containing the yield from statement.
When I looked at this first, I initially was under the impression that if a generator A delegates to generator B by doing yield from B, and B yields a value, control would go back to A, similar to a subroutine call. However, this is not the case. Instead of thinking of a yield from like a call, its better to think of it like a jump. In fact, when B yields a value, this value will be returned directly to the caller of A. The yield from statement in A only returns when B either returns or raises a StopIteration (which is equivalent), and the return value of B will then be the value of the yield from statement. So you might think of the original caller and A as being connected through a pipe through which yielded values are sent back to the caller, and if A delegates to B, it also hands the end of the pipe over to B where it remains until B returns (i.e. is exhausted in the sense of an iterator).

Passing values and exceptions into coroutines
We have seen that when a coroutine executes a yield, control goes back to the caller, i.e. to the code that triggered the coroutine using __next__, and when the coroutine is resumed, its execution continues at the first statement after the yield. Note that yield is a statement and takes an argument, so that the coroutine can hand data back to the caller, but not the other way round. With PEP-342, this was changed and yield became an expression so that it actually returns a value. This allows the caller to pass a value back into the generator function. The statement to do this is called send.
Doing a send is a bit like a __next__, with the difference that send takes an argument and this argument is delivered to the coroutine as result of the yield expression. When a coroutine runs for the first time, i.e. is not resumed at a yield, only send(None) is allowed, which, in general, is equivalent to __next__. Here is a version of our generator that uses this mechanism to be reset.
def my_generator(limit=5):
_position = 0
while _position < limit:
cur = _position
val = yield cur
if val is not None:
#
# We have been resumed due to a send statement.
#
_position = val
yield val
else:
_position += 1
We can now retrieve a few values from the generator using __next__, then use send to set the position to a specific value and then continue to iterate through the generator.
generator = my_generator(20) assert 0 == generator.__next__() assert 1 == generator.__next__() generator.send(7) assert 7 == generator.__next__()
Instead of passing a value into a coroutine, we can also throw an exception into a coroutine. This actually quite similar to the process of sending a value – if we send a value into a suspended coroutine, this value becomes visible inside the coroutine as the return value of the yield at which the coroutine is suspended, and if we throw an exception into it, the yield at which the coroutine is suspended will raise this exception. To throw an exception into a coroutine, use the throw statement, like
generator = my_generator(20) assert 0 == generator.__next__() generator.throw(BaseException())
If you run this code and look at the resulting stack trace, you will see that in fact, the behavior is exactly as if the yield statement had raised the exception inside the coroutine.
The generator has a choice whether it wants to catch and handle the exception or not. If the generator handles the exception, processing continues as normal, and the value of the next yield will be returned as result of throw(). If, however the generator decides to not handle the exception or to raise another exception, this exception will be passed through and will show up in the calling code as if it had been raised by throw. So in general, both send and throw statements should be enclosed in a try-block as they might raise exceptions.
Speaking of exceptions, there are a few exceptions that are specific for generators. We have already seen the StopIteration exception which is thrown if an iterator or generator is exhausted. A similar exception is GeneratorExit which can be thrown into a generator to signal that the generator should complete. A generator function should re-raise this exception or raise a StopIteration so that its execution stops, and the caller needs to handle the exception. There is even a special method close that can be used to close a coroutine which essentially does exactly this – it throws a GeneratorExit into the coroutine and expects the generator to re-raise it or to replace it by a StopIteration exception which is then handled. If a generator is garbage-collected, the Python interpreter will execute this method.
This completes our discussion of the “old-style” coroutines in Python using generator functions and yielding. In the next post, we will move on to discuss the new syntax for native coroutines introduced with Python 3.5 in 2015.