NFTs (non-fungible token) are one of the latest and most exciting developments in the blockchain universe, with use cases ranging from such essential things as breeding cute virtual kitten digitally on the blockchain to digital auctions as conducted earlier this year by the renowned fine art auctioneer Sothebys’s. In this post, we will explain why an NFT is nothing but a smart contract with specific functionality and talk about the ERC-721 standard that formally defines NFTs.
Non-fungible token
In a previous post in this series, we have looked at token according to the ERC-20 standard. We have seen that in its essence, a token is implemented by a smart contract that is maintaining a mapping of accounts to balances to track ownership in a digital currency.
As for a traditional currency, documenting ownership by just keeping track of how many token you own works because such a token is completely fungible – any two are the same. If you hold a token, say the Chainlink (LINK) token, the blockchain records a balance, say 100 LINK, and if you transfer 20 LINK to another account, it does not make sense to ask which of the 100 LINK you have transferred.
This is a good approach to model a currency, but sometimes, you want to achieve something else – you want to document ownership in a uniquely identifyable asset, say a piece of art, or a property. To do this, you would assign a unique ID to each asset, and then keep track of who owns which asset by maintaining a mapping of asset IDs to owners. This is more or less what a non-fungible token does.
Correspondingly, a non-fungible token contract (NFT contract) is essentially a smart contract that maintains a data structure to document ownership in a specific item, modeled as a mapping from item IDs (the so-called token ID) to the current owner. Suppose, for instance, an artist releases a collection of digital pieces of art, numbered from 1 to 100, and sells them as NFTs. Then, the token ID would range from 1 to 100, every ID would represent the corresponding piece of art, and the mapping would document who owns which item.
Apart from the mapping itself, the contract would also have to offer methods to transfer ownership, say a method transfer that would accept a token ID and the new owner as input and would adjust the mapping to update the owner accordingly. You could also come up again with an approach to pre-approve transfers so that the new owner could actively call into the contract to claim ownership, and, in addition, you would probably add a few convenience functions, for instance to figure out the current owner for a given token ID.
The ERC-721 standard
Similar to the ERC-20 standard, the community has developed a standard – the ERC-721 standard – for smart contracts representing NFTs. However, the ERC-721 standard is considerably more complicated than the ERC-20 standard. Here is an overview of its methods and events.
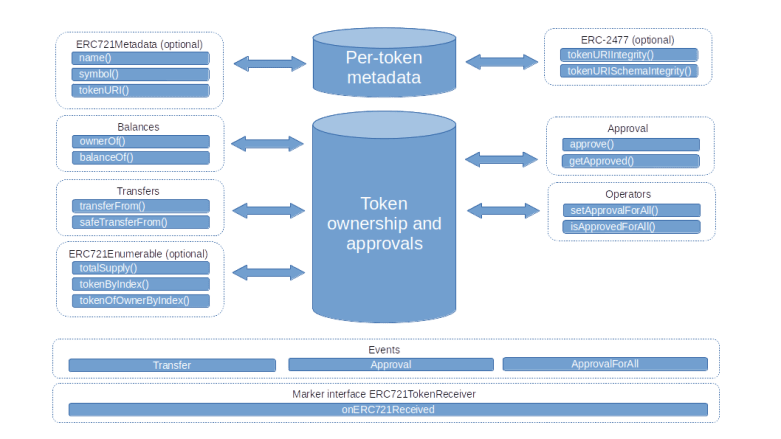
That might look a bit intimidating, but do not worry – we will go through each of the building blocks step by step, and things will fall into place.
Let us start with balances. ERC-721 defines two different approaches to balances. First, there is the ownerOf method which simply returns the owner of a specific asset, identified by the token ID. Essentially, this simply queries the mapping of token IDs to current owners that the contract maintains. Here, the token ID is a 256-bit integer, i.e. a uint256 in Solidity. In addition, there is still a balanceOf method that returns the total number of NFTs owned by a specific account (this is useful in combination with the enumeration features that we will discuss below).
Next, let us start to discuss transfers. The easiest way to initiate a token transfer is to use the method transferFrom. This method allows a caller to transfer a given token, identified by the token ID, from its current holder to different address. Of course, the sender of the message needs to be authorized to perform the transfer – the current owner of a token is always authorized, but there are more options, we will get to this point below.
This is essentially the same structure and logic as the transfer method of a fungible token according to ERC20. However, there is a risk associated with using this method. Suppose that you use this method to transfer a token to a certain address, and that the receiver is a smart contract. Then the NFT will be transferred to the smart contract, and only a transaction originating from the smart contract can transfer the token to another account. If the smart contract is not prepared for this, i.e. if it does not have a method to initiate such a transfer, the NFT is forever lost (unless, maybe, the contract is an upgradeable contract) and therefore the NFT will remain assigned to the contract forever.
To at least partially mitigate this risk, the ERC-721 standard encourages contracts that are capable of managing NFTs to make this visible by implementing a marker interface. Specifically, a contract that is prepared to receive NFT should implement a method
function onERC721Received(address operator, address from, uint256 tokenId, bytes data) external returns(bytes4);
The idea behind this is similar to the receive and fallback functions in Solidity. Of course, the pure presence of this function does not say anything about its implementation, but at least it indicates that the author of the contract was aware of the possibility that the contract might receive an NFT.
In order to restrict transfers to transfers to either an EOA or a contract that implements the marker interface, an NFT contract offers the method safeTransferFrom. This method is very similar to an ordinary transfer, with two exceptions. First, it is supposed to check whether the receiving address is a smart contract (or, which is not exactly the same thing, has a non-zero code). If yes, it will try to invoke the method onERC721Received of the target contract which is supposed to return a defined sequence of four bytes (a “magic value”). If the target contract does not implement the method, or the method exists but returns a different value, then the transfer will fail.
Second, the method safeTransferFrom optionally accepts a data field that can contain an arbitrary sequence of bytes which is handed over to onERC721Received of the recipient. The target contract can then, for instance, log this data or perform some other operations like updating a balance and storing the passed data as a reference.
Let us now turn to authorizations – who is allowed to initiate a transfer? Of course, the owner of an NFT is always authorized to transfer it. In addition to this, the withdrawal pattern is supported as well, similar to the ERC20 standard. In fact, there is a method approve that the owner of an NFT can invoke to authorize someone else to transfer this token. Approvals can also be explicitly revoked, and of course approvals are reset if ownership for an NFT changes.
In addition to this explicit approval that refers to a specific token ID, it is also possible to register another address as being authorized to make any transfer on your behalf, i.e. as an operator. Once defined, an operator can transfer any token that you own and can also make approvals and therefore authorize withdrawals. This global approval method has no equivalent in the ERC20 standard, but there is an extension (EIP-777) to the standard which adds this functionality for fungible token as well.
Finally, the standard defines events that are supposed to be emitted when a transfer is made, an approval is granted or revoked or an operator is named or removed.
The enumeration extension
The ERC721 standard makes it easy to figure out the current owner of an NFT once you know the token ID – simply call ownerOf using the token ID as argument. However, the token ID can, in general, be any 256 bit number, and there is no reason to assume that this will always be a simple sequence. As a consequence, it is not obvious how to figure out which token IDs are actually in use, i.e. which token have already been minted.
To address this, the standard defines a set of optional methods that allow a user to enumerate all existing tokens. This proceeds in two steps. First, the method totalSupply is supposed to return the total number of token in existence, i.e. token that have already been minted. Then, the method tokenByIndex can be called with an index less than the total supply to get the ID of a specific token. Similar, the balanceOf method (which is mandatory) returns the number of token held by a specific owner, and tokenOfOwnerByIndex can be used to enumerate these token. Implementing these optional methods requires an additional data structure in the contract, for instance an array that contains all token IDs.
This enumeration extension is the only standardized way to get a list of existing token IDs. It forces the contract, however, to implement and maintain additional data structures and I would assume that many contract owners have chosen not to implement it (in the next post, we will look at a few real-word examples, and as a matter of fact, none of them implements this extension). Alternatively, a contract could emit a (non-standard) initial log entry upon contract creation to indicate all token IDs that are available directly after contract creation, and then a user could monitor the Transfer events which, per the specification, should be emitted if an additional token is minted.
That concludes our post for today. You might have noted that we have not yet discussed an extension that is indicated in the diagram at the top of this article – the metadata extension. This extension touches upon an interesting question – if an NFT documents ownership in (say) a digital asset, where is the actual asset stored? This question and its ramifications will be the topic of the next post in this series.