The quantum Fourier transform is a key building block of many quantum algorithms, from Shor’s factoring algorithm over matrix inversion to quantum phase estimation and simulations. Time to see how this can be implemented with Qiskit.
Recall that the quantum Fourier transform (or, depending on conventions, its inverse) is given by
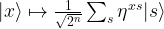
where 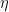
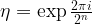
How can we effectively create this state with a quantum circuit? They key to this is the observation (see the references below) that the result of the quantum Fourier transform can be written as a product state, namely as
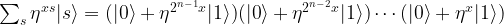
which you can easily verify by multiplying out the product and collecting terms.
Here we use the tensor product order that is prescribed by OpenQASM, i.e. the most significant bit is q[n-1]. This bit is therefore given by

Let us analyse this expression further. For that purpose, we decompose x into its representation as a binary number, i.e. we write

with xi being the binary digits of x. If we now multiply this by 2n-1, we will get 
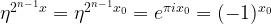
Thus, we can write the most significant qubit of the Fourier transform as

which is nothing but

Thus we obtain the most significant qubit of the quantum Fourier transform by simply applying a Hadamard gate to the least significant qubit of the input.
This is nice and simple, but what about the next qubit, i.e. qubit n-2? From the decomposition above, we can see that this is simply

Using exactly the same arguments as for the most significant qubit, we easily find that this is

Thus we obtain this qubit from qubit 1 by first applying a Hadamard gate and then a conditional phase gate, i.e. a conditional rotation around the z-axis, conditioned on the value of x0. In general, qubit n-j is

which is a Hadamard gate followed by a sequence of conditional rotations around the z-axis, conditioned on the qubits with lower significance.
So we find that each qubit of the Fourier transform is obtained by applying a Hadamard followed by a sequence of conditional rotations. However, the order of the qubits in the output is reversed, i.e. qubit n-j is obtained by letting gates act on qubit j. Therefore, at the end of the circuit, we need to revert the order of the qubits.
In OpenQASM and Qiskit, a conditional rotation around the z-axis is called CU1, and there are swap gates that we can use to implement the final reversing of the qubits. Thus, we can use the following code to build a quantum Fourier transformation circuit acting on n qubits.
def nBitQFT(q,c,n):
circuit = QuantumCircuit(q,c)
#
# We start with the most significant bit
#
for k in range(n):
j = n - k
# Add the Hadamard to qubit j-1
circuit.h(q[j-1])
#
# there is one conditional rotation for
# each qubit with lower significance
for i in reversed(range(j-1)):
circuit.cu1(2*np.pi/2**(j-i),q[i], q[j-1])
#
# Finally we need to swap qubits
#
for i in range(n//2):
circuit.swap(q[i], q[n-i-1])
return circuit
Here is the circuit that this code produces for n=4. We can clearly see the structure – on each qubit, we first act with a Hadamard gate, followed by a sequence of conditional rotations with decreasing angle, conditioned on the less significant qubits, and finally reorder the qubits.

This is already a fairly complex circuit, and we need to find a way to test it. Let us look at the options we have. First, a quantum circuit is a unitary transformation and can be described by a matrix. In our case, it is especially easy to figure out what this matrix should be. Looking at the formula for the quantum Fourier transform, we find that the matrix describing this transformation with respect to the computational basis has the elements
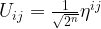
The Qiskit frameworks comes with a simulator called the unitary_simulator that accepts a quantum circuit as input and returns the matrix describing that circuit. Thus, one possible test approach could be to build the circuit, run the unitary simulator on it, and to compare the resulting unitary matrix with the expected result given by the formula above. In Python, the expected result is produced by the following code
def qftMatrix(n):
qft = np.zeros([2**n,2**n], dtype=complex)
for i in range(2**n):
for j in range(2**n):
qft[i,j] = np.exp(i*j*2*1j*np.pi/(2**n))
return 1/np.sqrt(2**n)*qft
and the test can be done using the following function
def testCircuit(n):
q = QuantumRegister(n,"x")
c = ClassicalRegister(n,"c")
circuit = nBitQFT(q,c,n)
backend = Aer.get_backend('unitary_simulator')
job = execute(circuit, backend)
actual = job.result().get_unitary()
expected = qftMatrix(n)
delta = actual - expected
print("Deviation: ", round(np.linalg.norm(delta),10))
return circuit
The outcome is reassuring – we find that the matrices are the same within the usual floating point rounding differences.
After passing this test, a next reasonable validation step could be to run the algorithm on a specific input. We know that the QFT will map the state 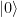
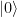
Let us try this out. Our test circuit will consist of a layer of Hadamard gates to create the equal superposition, followed by the QFT circuit, followed by a measurement. The resulting circuit for n=4 is displayed below.

It we run this circuit on the QASM simulator embedded into Qiskit, the result is as expected – for 1024 shots, we get 1024 times the output ‘0000’. So our circuit works – at least theoretically. But what about real hardware?
Let us compile and run the circuit targeting the IBM Q Experience 14 qubit device. If we dump the QASM code after compilation, we see that the overall circuit will have roughly 140 gates. This is already significant, and we expect to see some noise. To see how bad it is, I have conducted several test runs and plotted the results as a histogramm (if you want to play with this yourself, you will find the notebook on Github). Here is the output of a run with n=4.
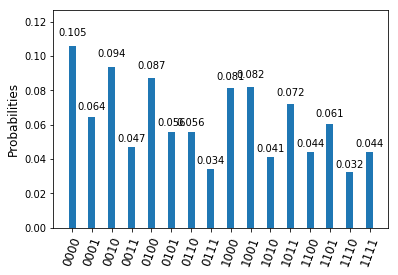
We still see a clear peak at the expected result, but also see that the noise level is close to making the result unusable – if we did not know the result upfront, we would probably not dare to postulate anything from this output. With only three qubits, the situation becomes slightly better but is still far from being satisfactory.

Of course we could now start to optimize the circuit – remove cancelling Hadamard gates, remove the final swap gates, reorder qubits to take the coupling map into account and so on – but it becomes clear that with the current noise level, we are quickly reaching a point where even comparatively simple circuit will inflict a level of noise that is at best difficult to handle. Hopefully, this is what you expected after reading my posts on quantum error correction, but I found it instructive to see noise in action in this example.
References
1. M. Nielsen, I. Chuang, Quantum Computation and Quantum Information, Cambridge University Press 2010
2. R. Cleve, A. Ekert, C. Macchiavello, M. Mosca, Quantum Algorithms revisited, arXiv:9708016


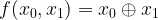
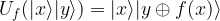


 , so that our state is now
, so that our state is now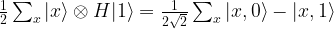
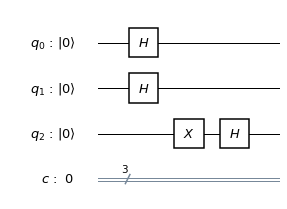
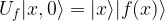



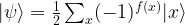
 . Clearly,
. Clearly,

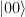 which is the same thing as the probability to measure
which is the same thing as the probability to measure  when we perform a measurement in the computational basis. Thus we finally obtain the following circuit
when we perform a measurement in the computational basis. Thus we finally obtain the following circuit











 called the Pauli group. Put differently, the Pauli group consists of those linear operators on the Hilbert space that can be written as a product
called the Pauli group. Put differently, the Pauli group consists of those linear operators on the Hilbert space that can be written as a product
 and an overall phase factor
and an overall phase factor 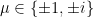 (we can even assume that all the
(we can even assume that all the 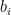 are equal to one as
are equal to one as  is a multiple of
is a multiple of  ). Any two elements of the Pauli group either commute or anti-commute. Within this group, we now consider a finite set
). Any two elements of the Pauli group either commute or anti-commute. Within this group, we now consider a finite set  of commuting elements and the subgroup S of the Pauli group generated by this set. This group (which is abelian as it is generated by mutually commuting elements) is called the stabilizer group. To this group, we can associate the subspace that consists of all vectors that are fixed by all elements of the group, i.e. the space
of commuting elements and the subgroup S of the Pauli group generated by this set. This group (which is abelian as it is generated by mutually commuting elements) is called the stabilizer group. To this group, we can associate the subspace that consists of all vectors that are fixed by all elements of the group, i.e. the space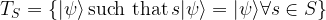
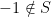 – you might want to take a look at
– you might want to take a look at 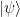 is a state in the code space, we can then calculate
is a state in the code space, we can then calculate
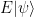 is now in the -1 eigenspace of s. Thus if we measure all elements of S, the outcome -1 for one of the measurements will tell us that an error has occurred. A similar argument shows that if the product of any two errors anti-commutes with at least one element of S, then we can also correct the error based on only the measurement results of elements in S. Mathematically speaking, the set of all elements of the Pauli group that commute with all elements of S is the centralizer of S, which in this case turns out to be equal to the normalizer N(S) of S, and a set
is now in the -1 eigenspace of s. Thus if we measure all elements of S, the outcome -1 for one of the measurements will tell us that an error has occurred. A similar argument shows that if the product of any two errors anti-commutes with at least one element of S, then we can also correct the error based on only the measurement results of elements in S. Mathematically speaking, the set of all elements of the Pauli group that commute with all elements of S is the centralizer of S, which in this case turns out to be equal to the normalizer N(S) of S, and a set  of errors can be detected and corrected if and only if
of errors can be detected and corrected if and only if
 . So the elements of the Pauli group that are neither in S nor in N(S) correspond to correctable errors.
. So the elements of the Pauli group that are neither in S nor in N(S) correspond to correctable errors.
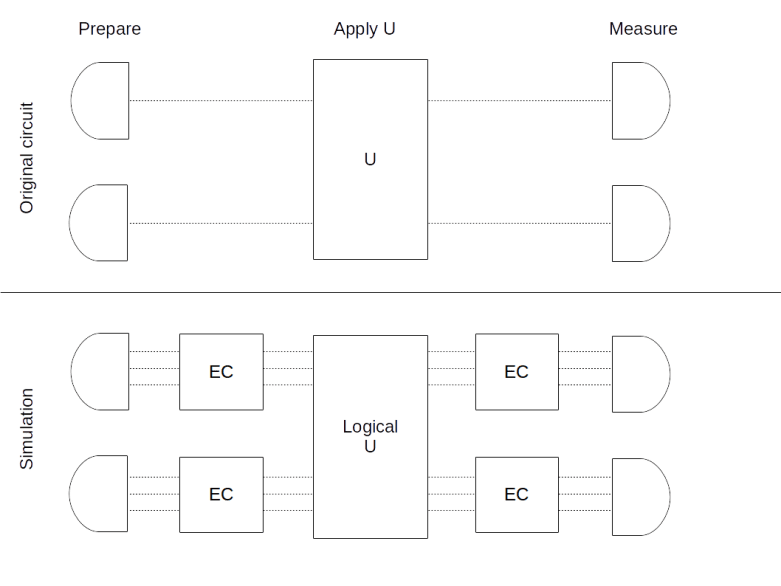
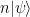 is again fixed by all elements of S and therefore in the code space TS. Thus the elements of N(S) generate automorphisms of the code space, i.e. logical operations. It is one of the strengths of the stabilizer formalism that once we have the stabilizer group S, we can not only derive the code space and the correctable errors, but can also use group theoretic considerations to describe logical operations – this will become clearer as we study surface codes in a later post.
is again fixed by all elements of S and therefore in the code space TS. Thus the elements of N(S) generate automorphisms of the code space, i.e. logical operations. It is one of the strengths of the stabilizer formalism that once we have the stabilizer group S, we can not only derive the code space and the correctable errors, but can also use group theoretic considerations to describe logical operations – this will become clearer as we study surface codes in a later post.

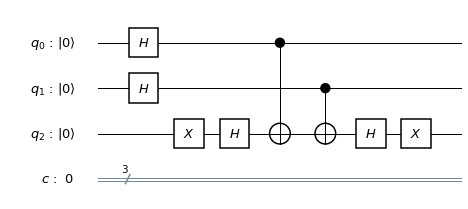
 will be mapped to
will be mapped to  . Thus our circuit does in fact implement a CNOT gate on the logical level.
. Thus our circuit does in fact implement a CNOT gate on the logical level.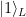 . Thus even a single error in the input will render the result unusable. This is an example for uncontrolled error propagation: a single error in the control word input has propagated across all three qubits that make up the second input and our code – which is only able to protect against single qubit errors – fails.
. Thus even a single error in the input will render the result unusable. This is an example for uncontrolled error propagation: a single error in the control word input has propagated across all three qubits that make up the second input and our code – which is only able to protect against single qubit errors – fails.