In todays post, we will complete our understanding of how the EVM executes a smart contract. We will investigate the actual interpreter loop, discuss gas handling and have a short look at pre-compiled contracts.
The jump table and the main loop
In the last post, we have seen that the entry point to the actual code execution is the Run method of the EVM interpreter. This method is essentially going through the bytecode step by step and, for each opcode, looking up the opcode in a data structure known as jump table– Among other things, this table contains a reference to a Go function that is to be executed to process the instruction. More specifically, an entry in the jump table contains the following fields, which partially refer to other tables in other source code files.
- First, there is a Go function which is invoked to process the operation
- Next, there is a gas value which is known as the constant gas cost of the operation. The idea behind this is that the gas cost for the execution of an instruction typically has two parts – a static part which is independent of the parameters and a dynamic part which depends on parameters like the memory consumption or other parameters. This field represents the static part
- The third field is again a function that can be used to derive the dynamic part of the gas cost
- The fourth field –
minStack– is the number of stack items that this operation expects - The next field –
maxStack– is the maximum size of the stack that will still allow this operation to work without overflowing the stack. For most operations, this is simply the maximum stack size minus the number of items that the operation pops from the stack plus the number of items that it adds to the stack - The next field,
memorySize, specifies how much memory the opcode needs to execute. Again, this is a function, as the result could depend on parameters - The remaining fields are a couple of flags that describe the type of operation. The flag
haltsis set if the operation ends the execution of the code. At the time of writing, this is set for the opcodesSTOP,RETURNandSELFDESTRUCT. - Similarly, the
revertsflag indicates whether this opcode explicitly reverts the execution and is currently only set for theREVERTopcode itself - The return flag indicates whether this opcode returns any data. This is the case for the call operations
STATICCALL,DELEGATECALL,CALL, andCALLCODE, but also forREVERTand contract creation viaCREATEandCREATE2 - The
writesflag indicates whether the operation modifies the state and is set of operations likeSSTORE - Finally, the
jumpsflag indicates whether the operation is a jump instruction and therefore modifies the program counter
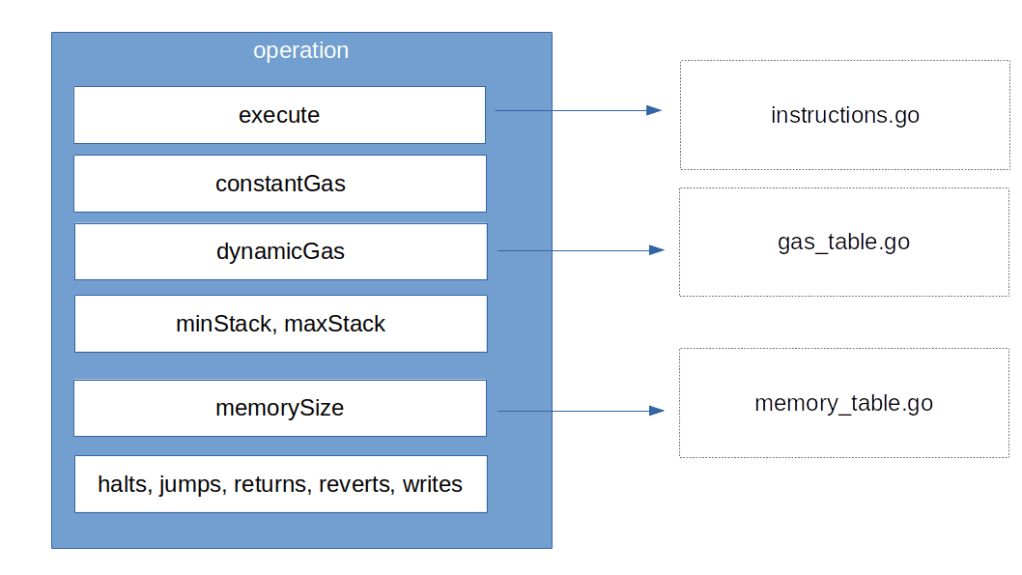
Another data structure that will be important for the execution of the code is a set of fields known as the call context. This refers to a set of variables that make up the current of the interpreter and are reset every time a new execution starts, like memory, stack and the contract object.
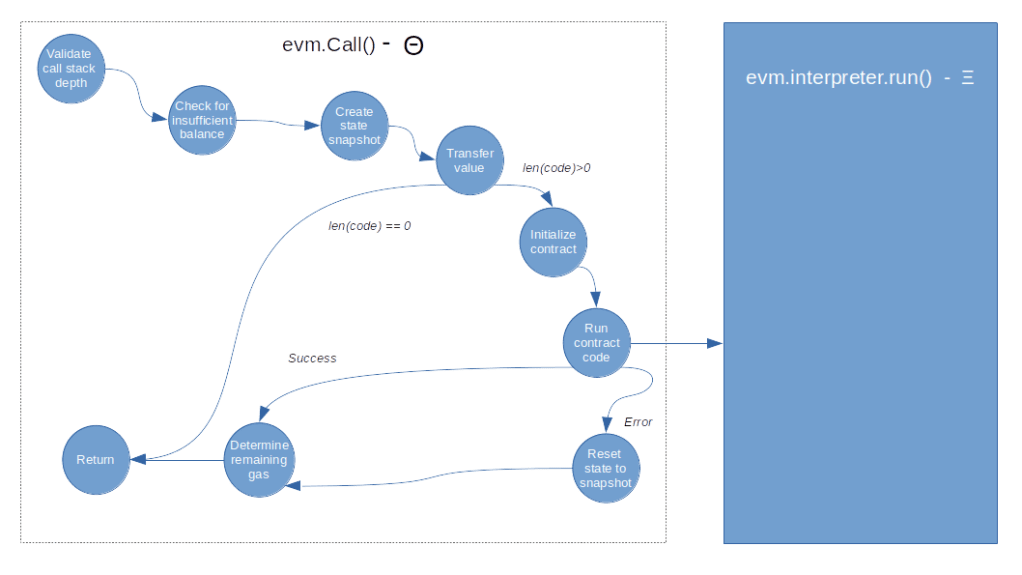
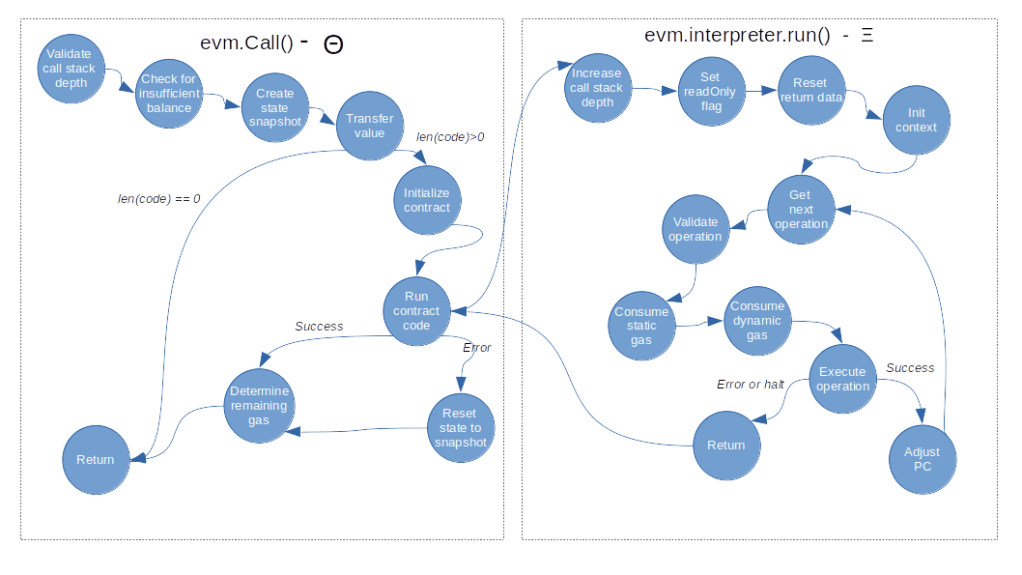
Let us now go through the Run method step by step and try to understand what it does. First, it increments the call stack depth which will be decremented again at the end of the function. It also sets the read only flag of the interpreter if not yet done and resets the return data field. Next, we initialize the call context and set the program counter to zero before we eventually enter a loop called the main loop.
Within this loop, we first check every 1000th step whether the abort flag is set. If yes, we stop execution (my understanding is that this feature is primarily used to cancel running EVM operations that were started as part of an API call). Next, we use the current value of the program counter to read the next opcode that we need to process, and look up that operation in the jump table (raising an error if there is no entry, which indicates an invalid opcode).
Once we have the jump table entry in our hands, we can now check the current stack size against the minimum and maximum stack size of the instruction and make sure that we raise an error if we try to process an operation in read-only mode that potentially updates the state.
We then calculate the gas required to perform the operation. As already explained, the gas consumption has two parts – a static part and a dynamic part. For each of these two contributions, we invoke the method UseGas() of the contract object, which will reduce the gas left that the contract tracks and also raise an error if we are running out of gas.
We then execute the operation by invoking the Go function to which it is mapped. This function will typically get some data from the stack, perform some calculations and push data back to the stack, but can also modify the state and perform more complex operations. Most if not all operations are contained in instructions.go, and it is instructive to scan the file and look at a few operations to get a feeling for how this works (we will go through a more complex example, the CALL operation, in a later post).
Once the instruction completes, we check the returns flag of the jump table entry to see whether the instruction returns any data, and if yes, we copy this data to the returnData field of the interpreter so that it is available for the next instruction. We then decide whether the execution is complete and we need to return to leave the main loop, or whether we need to continue execution with an updated program counter.
So the main loop is actually rather straightforward, and, together with our discussion of the Call() method in the previous post, we now have a fairly complete picture of how contract execution works.
Handling gas consumption
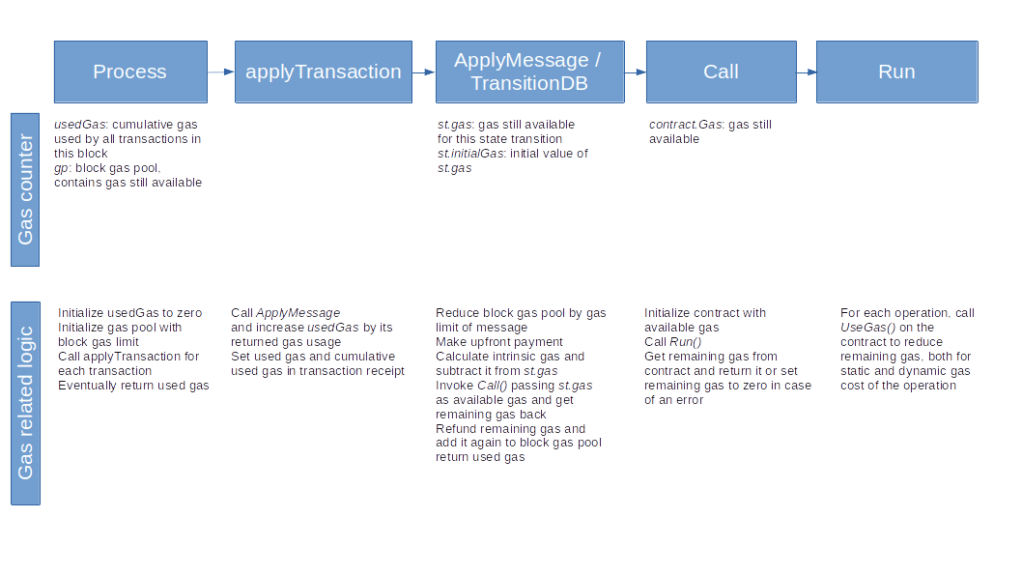
Let us leverage this end-to-end view to put together the various bits and pieces to understand how gas consumption is handled. We start our discussion on the level of an entire block. In one of the previous posts, we have already seen that when a block is processed here, two gas related variables are maintained. First, the processing keeps track of the gas used for all transactions in this block, which corresponds to the gasUsed field of a block header. In addition, there is a block gas pool, which is simply a counter initialized with the current block gas limit and used to keep track of the gas which is still available without violating this limit.
When we now process a single transaction contained in the block, we invoke the function applyTransaction. In this function, we increase the used gas counter on the block level by the gas consumed by the transaction and use that information to create the transaction receipt, that contains both the gas used by the transaction and the current value of the cumulative gas usage on the block level. This is done based on the return value of the ApplyMessage function, which itself immediately delegates to the TransitionDB method of a newly created state transition object.
The state transition object contains two additional gas counters. The first counter (st.gas) keeps track of the gas still available for this transaction, and is initialized with the gas limit of the transaction, so this is the equivalent of the gas pool on the block level. The second counter is the initial value of this field and only used to be able to calculate the gas actually used later on.
When we now process the transaction, we go through the following steps.
- First, we initialize the gas counters
- Then, we deduct the upfront payment from the senders balance. The upfront payment is the gas price times the gas limit and therefore the maximum amount of Ether that the sender might have to pay for this transaction
- Similarly, we reduce the block gas limit by the gas limit of the transaction
- Next, we calculate the intrinsic gas for the transaction. This is the amount of gas just for executing the plain transaction, still without taking any contract execution into account. It is calculated (ignoring contract creations) by taking a flat fee of currently 21000 units of gas per transaction, plus a fee for every byte of the transaction input (which is actually different for zero bytes and non-zero bytes). In addition, there is a fee for each entry in the access list (this is basically a list of accounts and addresses for which a discount applies when accessing them, see EIP-2930). In the yellow paper, the intrinsic gas is called g0 and defined in section 6.2
- We then reduce the remaining gas by the intrinsic gas cost (again according to what section 6.2 of the yellow paper prescribes) and invoke
Call(), using the remaining gas counterst.gasas the parameter which determines the gas available for this execution. Thus the gas available to the contract execution is the gas limit minus the intrinsic gas cost. We have already seen that this creates aContractcontaining another gas counter which keeps track of the gas consumed during the execution. Within the interpreter main loop, we calculate static and dynamic gas cost for each opcode and reduce the counter accordingly. At the end, the remaining gas is returned - We update the remaining gas counter
st.gaswith the value returned byCall(). We then perform a refund, i.e. we the remaining gas times gas price back to the sender and also put the remaining gas back into the gas pool on block level
This has a few interesting consequences. First, it demonstrates that the total gas cost of executing a transaction does actually consist of two parts – the intrinsic gas for the transaction and the cost of executing the opcodes of the smart contract (if any). Both of these components have a static part (the 21000 base fee for the intrinsic gas cost and the static fee per opcode for the code execution) and a dynamic part, which depends on the transaction.
The second thing that you want to remember is that in order to make sure that a transaction is processed, it is not sufficient to have enough Ether to pay for the gas actually used. Instead, you need to have at least the gas limit times the gas price, otherwise the upfront payment will fail. Similarly, you need to make sure that the gas limit of your transaction is lower than the block gas limit, otherwise the block will not be mined.
Pre-compiled contracts
There is a special case of calling a contract that we have ignored so far – pre-compiled contracts. Before diving down into the code once more, let me quickly explain what pre-compiled contracts are and why they are useful.
Suppose you wanted to develop a smart contract that needs to calculate a hash value. The EVM has a built-in opcode SHA3 to calculate the Keccak hash, but what about other hashing algorithms? Of course, as the EVM is Turing-complete, you could develop a contract that does this, but this would blow up your contract considerably and, in addition, would probably be extremely slow as this would mean executing complex mathematical operations in the EVM. As an alternative, the Ethereum designers came up with the idea of a pre-compiled contract. Roughly speaking, this is a kind of extension of the instruction set of the EVM, realized as contracts located at pre-defined addresses. The contract at address 0x2, for instance, calculates an SHA256 hash, and the contract at address 0x3 a RIPEMD-160 hash. These contracts are, however, not really placed on the blockchain – if you look at the code at this address using for instance the JSON API method eth_getCode, you will not get anything back. Instead, these pre-defined contracts are handled by the EVM. If the EVM processes a CALL targeting one of these addresses, it does not actually call a contract at this address, but simply runs a native Go function that performs the required calculation.
We have already seen where in the code this happens – when we initialize the target contract in the Call() method of the EVM, we check whether the target address is a pre-compiled contract and, if yes, execute the associated Go function instead of running the interpreter. The return values are essentially the same as for an ordinary call – return data, an error and the gas used for this operation.
The pre-compiled contracts as well as the gas cost for executing them are defined in the file contracts.go. At the time of writing, there are nine pre-compiled contracts, residing (virtually) at the addresses 0x1 to 0x9:
- EC recover algorithm, which can be used to determine the public key of the signer of a transaction
- SHA256 hash function
- RIPEMD-160 hash function
- the data copy function, which simply returns the input as output and can be used to copy large chunks of memory more efficiently than by using the built-in opcodes
- exponentation module some number M
- three elliptic curve operations to support zero-knowledge proofs (see the EIPs 196 and 197)
- the BLAKE2 F compression function hash function (see EIP-152)
Here is the final flow diagram for the smart contract execution that now also reflects the special case of a pre-compiled contract.
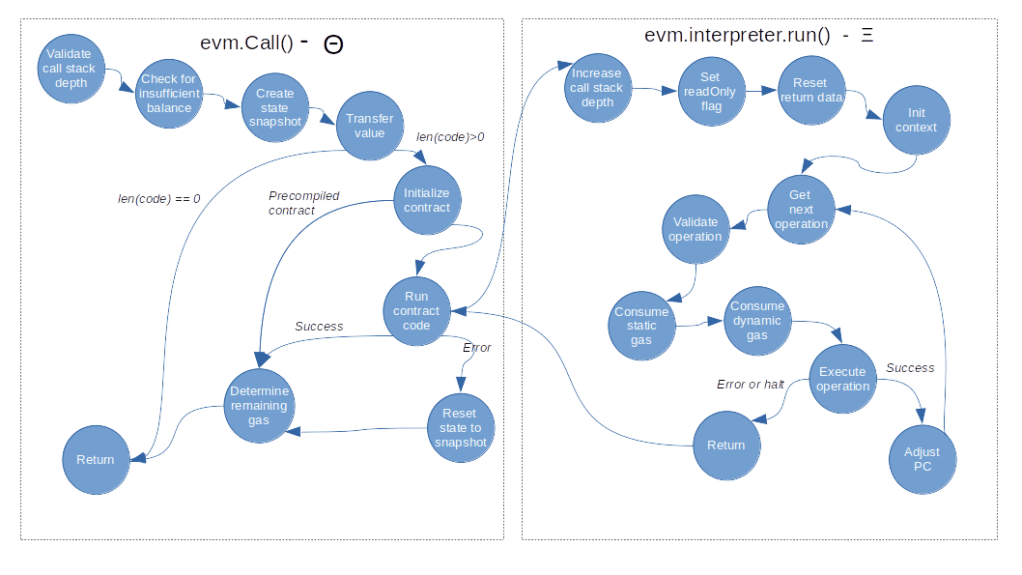
With this, we close our post for today. In the next post, we will take a closer look at the CALL opcode and its variations to understand how a smart contract can invoke another contract.