When you use your favorite search engine to search for information on quantum computing, the first term that will most likely jump at you is the qubit. In this post, I will try to explain what this is and how it is related to the usual framework of quantum mechanics.
Please be aware that this post is not meant to be a general introduction into quantum mechanics. I will have to assume some familiarity with the basics of quantum mechanics and the underlying mathematics (Hilbert spaces, states and measurements, operators, eigenvalues and so forth).
Qubits
In classical computing, the world is binary – information is expressed in terms of bits, i.e. units of information that can take on two values only – 1 or 0, true or false, high or low and so on, depending on the actual physical representation.
In the world of quantum computing, the smallest unit of information is represented by “the smallest quantum system”. But what is the smallest quantum system? Any nontrivial quantum system can actually be in an infinite number of states, and therefore it does not make sense any more to look for systems with only two states. What we can do, however, is to look for systems that have only two degrees of freedom. Mathematically, these are quantum mechanical systems that are described by a two-dimensional Hilbert space. In a certain sense, these are the smallest nontrivial quantum systems one can conceive, and similar to the classical world, where is a bit is the smallest nontrivial unit, these systems are called qubits and the fundamental building blocks in quantum computing.
I admit that this definition is a bit abstract, to let us look at some examples. An example that is often cited but mostly of theoretical interest is the spin. Imagine we are looking at a single, isolated charged particle, say an electron. Classically, this particle is described by its current position and its current movement (speed and direction). On a quantum mechanical level, it turns out that there is an additional property that becomes important – the electron somehow behaves as if it were rotating around an internal axis (this is only a very vague analogy as an electron is a point particle and does not have a classical size, but it is a useful description). Classically, you would expect that that rotation can happen in two ways – clockwise and counterclockwise. Let us use the notation 

However, quantum mechanics is more complicated than this. In fact, it turns out that the correct description for all possible states of such a system is not just the two options

with complex numbers a and b (more precisely, by the ray in the projective space of that Hilbert space).
There is no good classical analogy for such a state – trying to imagine that something is spinning “a little bit clockwise” and at the same time “a little bit counterclockwise” will make your head spin in either direction, but not take you anywhere. However, we get closer to the classical world if we conduct a measurement. In quantum mechanics, a measurable quantity is described by a hermitian operator, the possible outcomes are the eigenvalues of this operators and after the measurement, the system will be in the state described by one of the (normed) eigenvectors of the operators. In our case, a measurement might be set up in such a way that this operator has the basis 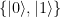
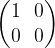
Of course, any two quantum systems which are described by a two-dimensional Hilbert space are equivalent, so every other system with that property could serve as a physical implementation of a qubit as well. This could for instance be a linearly polarized photon, with an eigenbasis given by the two orthogonal directions of polarization, or it could be a hydrogen atom with the ground state and the first excited state as the states
Multi-qubit systems and Hilbert spaces
It is nice to have a qubit, but you will probably anticipate that there is not so much we can do with a single qubit. Instead, we will need a large number of qubits that can interact. As always in quantum mechanics, the state of such a combined system is described by another Hilbert space, namely the tensor product of the single qubit Hilbert spaces.
So suppose that we are describing a single qubit by a two-dimensional Hilbert space H. A system of n identical qubits would then be described by the n-fold tensor product

of H with itself. Given states 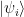

of these states. This gives us elements of the tensor product, but conversely, not every element of the tensor product can be written in this way (this is an important fact to which we will return below). It is, however, true that every state in the tensor product is a finite linear combination of product states. This is a major difference to the other common way to define a product of vector spaces, the direct product. In a direct product, the dimensions add up, in a tensor product, they multiply. Thus when we add a qubit, the dimension of our Hilbert space doubles and therefore grows exponentially with the number of qubits.
This is a good point in time to simplify our notation a bit. First, it is common to suppress the tensor product when it comes to states and to express the vector above simply as

Going further, we can also combine everything into one bra and write
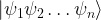
If we do this for the elements of a basis, we can simplify our notation even more. Let us do this for the states of a 2-qubit system first. By building tensor products of the base states
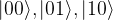

These four states actually form a basis for the tensor product. This is true in general – all possible tensor products of the vectors of a basis are a basis of the tensor product space. Now recall that, in binary notation, the 2-bit sequences 00, 01, 10 and 11 stand for the number 0 – 3. Using this, we could also write this basis as
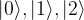
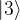
For a three qubit system, we could use the same notation to arrive at the basis
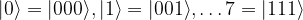
and so forth. In general, for a combined system of n qubits, we can label our basis with the numbers 0 to 2n-1, and our tensor product will have dimension 2n, with a general element being given as a sum
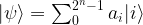
Entangled states
To close this post, let us come back to one very important point that is a major ingredient to the theoretical power of quantum computing – entanglement. Suppose we are given a two-qubit system. We have seen that certain states can be obtained by taking the tensor product of single qubit states. Can every state in the tensor product be obtained in this way?
Let us try this out. If we take the tensor product of two arbitrary single qubit states 

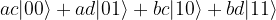
Now let us consider the state
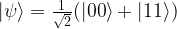
To decompose this state as a product, we would need ad = 0 and ac = 1, which is only possible if d = 0. However, then bd = 0 as well, and we get the wrong coefficient for 
The state above is often called a Bell state and it is worth mentioning that states like this and entanglement features in one of the most famous though experiments in the history of quantum mechanics, the so called Einstein-Podolsky-Rosen paradox or ERP paradox – a broad topic that we will not even try to cover here. We note, however, that it is entanglement that is responsible for the fact that the dimension of the state space grows exponentially with the number of qubits, and most quantum algorithms use entangled states somehow, so entanglement does seem to play a vital role in explaining why quantum computing seems to be superior to classical computing, see for instance section 13.9 of “Quantum computing – a gentle introduction” for a more in-depth discussion of the role of entanglement in quantum algorithms.
Visualizing quantum states
Before closing this post and turning to quantum gates in the next post in this series, let us quickly describe a way how to visualize a multi-qubit quantum state. Our starting point is the expression
for the most general superposition in an n-qubit system. To visualize that state, we could use a bar char as in the diagram below.
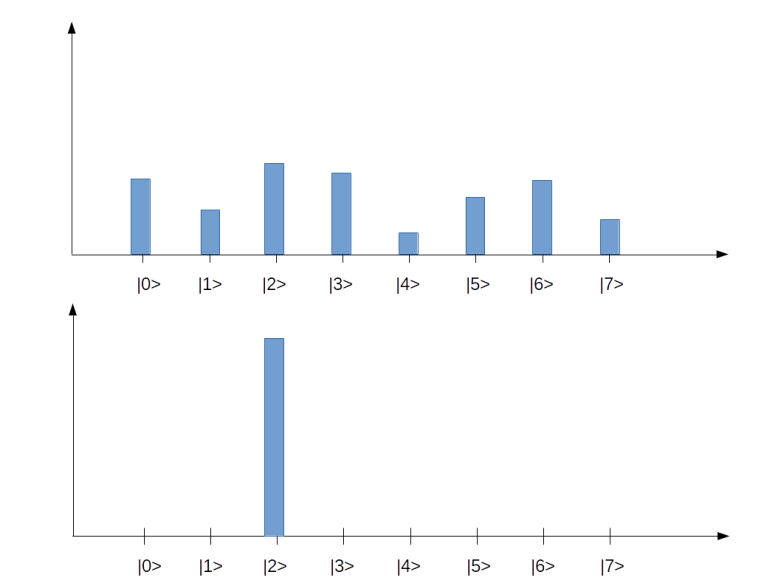
Each tick on the horizontal axis represents one of the basis states 
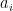

Qubits are nice, but in order to perform computations, we have to manipulate them somehow. This is done using quantum gates which I will discuss in my next post.