
While playing with the IBM Q experience in some of my recent posts, we have seen that real qubits are subject to geometric restrictions – two-qubit gates cannot involve arbitrary qubits, but only qubits that are in some sense neighbors. This suggests that efficient error correction codes need to tie to the geometry of the quantum device. Toric codes are an example of these codes that create interesting connections between topology and quantum computing.
The stabilizer group of a toric code
In their original form introduced by A. Kitaev in 1997 (see e.g. [1]), toric codes are designed to operate on quantum circuits arranged on a torus. Specifically, we consider a 2-dimensional discrete lattice L with periodic boundary conditions. On each edge of this lattice, we place exactly one qubit.
In algebraic topology, one can associate with such a lattice an abelian group called the group of one-chains of the lattice and denoted by 
This sounds a bit daunting and formal, so time to look at a picture and a few examples.
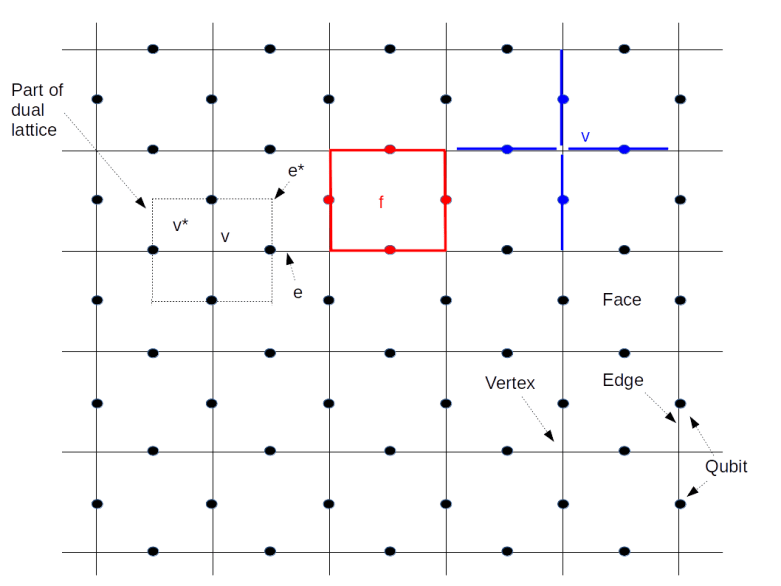
This diagram shows a graphical representation of our lattice L. The solid lines represent the edges of the lattice, their intersections are the vertices, see the labels at the lower right corner of the image. Cornered by four vertices and surrounded by four edges, there are the faces of the lattice. The black dots in the diagram indicate the qubits on the lattice.
Now let us look at the face marked in red and labeled by f at the top of the diagram. This face is surrounded by four edges colored red as well whose union is called the boundary of the face. This boundary is formalized as a one-chain denoted by 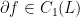
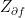
On the right of the face, we have – in blue – marked a single vertex v. This vertex again defines a chain, namely the subset of all edges – marked in blue – that touch the vertex. Again, we can associate an operator to this chain, this time we choose the product of the Pauli X operators acting on the qubits on the blue edges. This operator is called the vertex operator for the vertex v and denoted by Xv.
Our lattice has many faces and many vertices. For each face, we have a face operator and for each vertex, we have a vertex operator. It is not difficult to check that all these operators do in fact commute (note that a vertex touches every boundary twice). Therefore the group S generated by all these operators is an abelian group.
Now recall from one of my previous posts that the stabilizer formalism can be used to associate to every abelian subgroup of the Pauli group a code. The code obtained from the group S generated by all face and vertex operators is called the toric code.
Let us try to better understand the code space TS. Suppose that our lattice has E edges, V vertices and F faces. Then there are E qubits, i.e. the Hilbert space of physical qubits has dimension 2E. The stabilizer group is generated by the V vertex operators and the F face operators, i.e. by V + F elements. However, these elements are not independent – there are relations imposed by the toric geometry. In fact, the product of all vertex operators is one and the product of all face operators is one (this is easiest seen with a bit of background in algebraic topology – for those readers who have that background, I refer to my notes on quantum error correction for the mathematical details behind this and some other statements in this post). Thus there are in fact V + F – 2 generators. As each generator introduces a constraint on the code space that cuts the Hilbert space dimension down by a factor two, the dimension of the code space is
2E – (V+F – 2) = 22 – (V + F – E)
Now the number V + F – E is known as the Euler number of the torus in algebraic topology, and it also known that the Euler number of the torus is zero. Therefore the dimension of the code space is 22 = 4, i.e. the code space encodes two logical qubits (this will change if we later move on to a planar geometry).
Let us now try to understand the logical gates acting on these two logical qubits. By the general theory of stabilizer codes, we know that the logical operators are those operators that commute will all elements in the stabilizer. What does this mean geometrically? To see this, consider the following diagram.
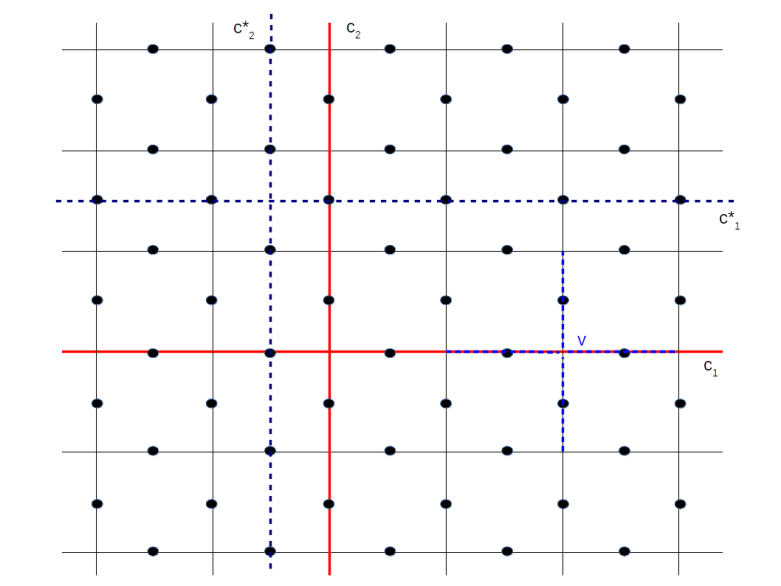
Consider the vertical red line in the diagram, labeled by c1. This line is a subset of edges, i.e. a one chain. To this chain, we can associate a Z operator Zc1, which is the product of all Pauli Z operators acting on the qubits touched by the red line. Being a Z operator, this operator commutes with all face operators. What about the vertex operators?
Close to the right border of the lattice, we have indicated the vertex operator Xv associated with the vertex v. This vertex operator acts on four qubits, indicated by the edges marked with the blue dashed line. Two of these edges also appear in the chain c1. Therefore, when we commute Xv and Zc1, we pick up two signs that cancel and the operators commute. Thus Zc1 commutes with all vertex and face operators and is in the normalizer. The same is true for the operator associated with the second red line. These two Z operators therefore act on the logical qubit. By convention, we can define the logical state 
It is interesting to note that the vertex operator Xv commutes with Zc1 because the chain c1 crosses the vertex v and therefore contains both edges touching v. If however, a chain c ends at v, then we will only pick up one sign when commuting the X past the Z operators. Geometrically, a vertex operator Xv anti-commutes with a Z-operator Zc associated with a chain c if and only if the vertex v is in the boundary of c, otherwise it commutes. The red line in our diagram is distinguished by the fact that its boundary is empty – it is a closed circle or a cycle in the language of algebraic topology that goes around the torus once. It therefore commutes with all vertex operators and thus is an element of the stabilizer.
Similarly, the dotted blue lines represent X operators, given by the product of the Pauli X operators acting on those qubits intersected by the blue line. A similar argument shows that, as these lines also go once around the torus, the X operators associated with them are in the normalizer of S as well. Thus we obtain two X operators that act as logical Pauli X operators on our code space. Given the logical X and Z operators, we can therefore implement all single qubit gates on our code space. It turns out that multi-qubit gates can be implemented by braid operations, but we will leave this to a later post when we study planar codes.
The particle interpretation of the toric code and anyons
Let us now turn to the particle interpretation of error correction in these codes, that will bring the famous anyons and ideas from topological quantum computing into play. For that purpose, consider the operator

which is the sum of all face and vertex operators. Clearly, this operator is hermitian, and can therefore be thought of as the operator of a physical system. Does this system have a particle interpretation?
To see this, let us try to determine the eigenstates of the Hamiltonian, i.e. the energy levels of our system. As the Xv and the Zf all commute, we can find a simultaneous basis of eigenstates that will diagonalize the Hamiltonian. Let us call this basis 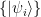
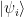

This is minimal if and only if all the xvi and zfi are equal to one, which is the case if
Now let us introduce an error into our system. One way to do this is to pick a chain c, i.e. a path on the lattice, and apply the Zc operator to one of the ground states 
As all Z operators commute, the state is clearly still in the +1 eigenspace of all the face operators Zf. If Xv is a vertex operator, the state will be in the -1 eigenspace if and only if Zc anti-commutes with Xv. But we have already seen that this happens if and only if v is in the boundary of c, i.e. v is one of the two vertices where the path c starts and ends! Thus the error syndrome is localized at those two vertices – if we imagine the vertex operator measurements as being signaled by green (outcome plus one) and red (outcome minus one) lights attached to the respective vertex, the error would be represented two red lights sitting at these vertices.
If we now expand the state 
So far we have associated an error operator Zc and therefore a particle with every chain, i.e. a path that runs along the edges. We can also consider a path that runs perpendicular to all the edges – in algebraic topology, this would be called a chain in the dual lattice or a co-chain. To every such path, we can associate an X operator, and this X operator acting on a ground state will create another excitation. The particles associated with a chain is called an electric charge e by Kitaev, and the particle created by a co-chain is called an magnetic vortex m.
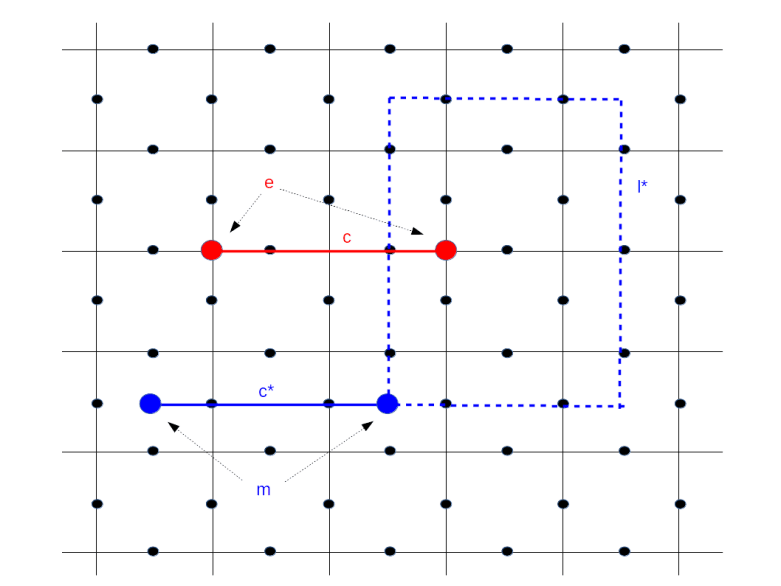
As indicated in the diagram above, electric charges come in pairs, are located on vertices of the lattice and manifest themselves as -1 eigenvalues of the corresponding vertex operators, whereas magnetic particles live on pairs of faces of the vertex and appear as -1 eigenvalues of face operators. In this diagram, the solid red line creates a pair of electric particles, and the solid blue line creates a pair of magnetic particles.
How do these particles relate to the composition of chains? Suppose that we are given a chain c12 running from vertex 1 to vertex 2 and a second chain c23 running from vertex 2 to vertex 3. Then there are two ways to create the particle sitting at the vertices 1 and 3 – we can either first act with the Z operator associated with the chain c12 and then let the operator associated with the chain c23 act, or we can form the sum c13 of the chains which now runs from 1 to 3 and let the operator associated with this chain act. Of course, the result will be the same. Thus we can interpret the act of applying the operator given by the chain c23 to an excited state as moving one of the particles from vertex 2 to vertex 3. The same applies to magnetic particles.
Now let us again consider the image above. Look at the blue dashed loop. According to what we have just said, we can start with the particle pair created by the solid blue line and then move one of the particles around that closed loop. The result will be a particle pair living at the same location as the original pair. You might think that the new state is in fact identical to the old state, but this is not true – the state picks up a phase factor minus one. This is the reason why Kitaev calls our quasi-particles anyons, a term generally used in particle physics to characterize particles with non-trivial statistics (in our case, mutual statistics)
Exchanging particles by moving them around each other can be described as an action of the pure braid group, i.e. as an action of the group of braids that return each particle to its original position (this subgroup, the kernel of the natural homomorphism from the braid group to the permutation group, is sometimes called the group of colored braids). If we perturb a braid slightly, the action will remain unchanged, so the unitary operators which are given by that action are by construction rather stable in the presence of noise. In [1], Kitaev developed the idea to use braid group representations to implement quantum gates. Unfortunately, the set of operators that we can obtain in this way using the toric code is not sufficient to implement a universal quantum computer – we will get back to this point in a later post when we look at the actual procedures used to perform computations in a toric or surface code. Therefore Kitaev goes on to describe certain hypothetical particles called non-abelian anyons which, if they can be physically realized, provide sufficiently rich unitary operations. This approach is called topological quantum computation. We will not go into further details but refer to the original work [1].
Measurement and error correction for toric codes
Let us quickly summarize what we have found so far. The code space of a toric code can be thought of as the ground state of a physical system, describing a collection of two-state systems located on the edges of a lattice. Errors correspond to fundamental excitations, i.e. quasi-particles, that come in pairs and sit on vertices and faces of the lattice. These errors can be detected by measuring face and vertex operators.
How can we perform these measurements in practice? To understand this, let us first recall a general approach for measuring eigenvalues. Suppose that U is an operator that is hermitian and at the same time unitary. Consider the following circuit which is a combination of two Hadamard gates with a controlled-U operation.
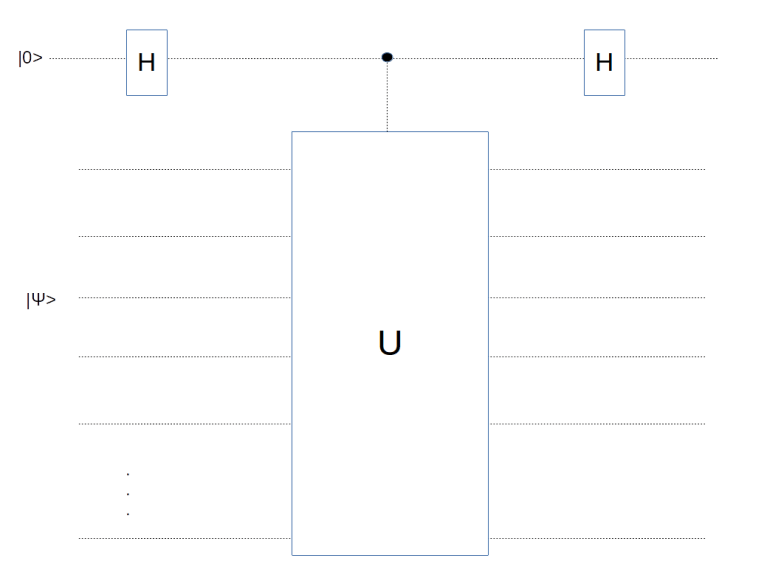
Let us calculate the state after applying this circuit. The initial state is

After applying the Hadamard gate to the first qubit, we obtain
![\frac{1}{\sqrt{2}} \big[ |0 \rangle |\psi \rangle + |1 \rangle |\psi \rangle \big]](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B%5Csqrt%7B2%7D%7D+%5Cbig%5B+%7C0+%5Crangle+%7C%5Cpsi+%5Crangle++%2B+%7C1+%5Crangle+%7C%5Cpsi+%5Crangle+++%5Cbig%5D++&bg=FFFFFF&fg=000&s=1&c=20201002)
which the controlled U operation turns into
![\frac{1}{\sqrt{2}} \big[ |0 \rangle \otimes |\psi \rangle + |1 \rangle \otimes U |\psi \rangle \big]](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B%5Csqrt%7B2%7D%7D+%5Cbig%5B+%7C0+%5Crangle+%5Cotimes+%7C%5Cpsi+%5Crangle++%2B++%7C1+%5Crangle+%5Cotimes+U+%7C%5Cpsi+%5Crangle++%5Cbig%5D++&bg=FFFFFF&fg=000&s=1&c=20201002)
Now U is unitary, and therefore its eigenvalues are plus and minus one. So we can decompose our state 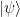
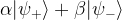
where 

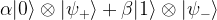
If we now apply a measurement to the control qubit, which serves as an ancilla here, the state is projected onto either 
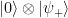
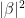

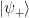
Let us now apply this idea to the problem of measuring one of the operators Xv. This operator is a tensor product of four 
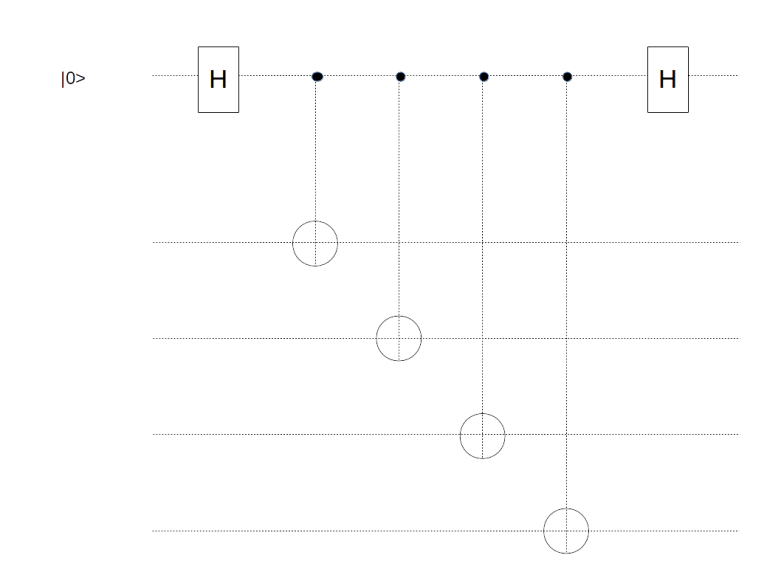
Here the four qubits at the bottom correspond to the four edges meeting the vertex v. So we need one ancilla qubit for doing the measurement, and we need to be able to combine it in gates with all the four qubits sitting on the edges meeting v. For the physical implementation, the easiest approach is to place this additional qubit called measurement qubit in the vertex itself, in contrast to the data qubits that we have already placed on the edges. So we add one data qubit to each vertex.
A circuit along the same lines can be constructed to measure Zf for a face f. Using that 
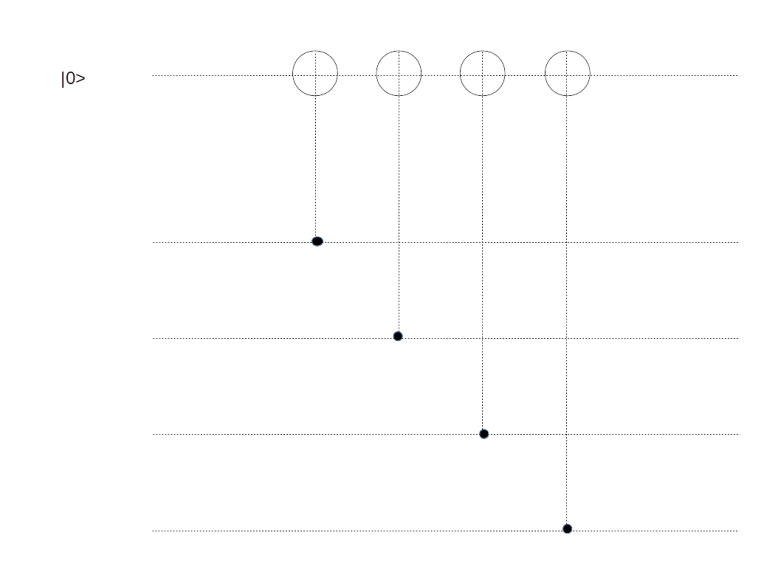
Again, for each face f, we need an ancilla qubit to measure Zf. This qubit will have to interact with all data qubits on the edges bounding this face, so it is easiest to position it in the center of that face.
Overall, we have now added F + V measurement qubits to our original E data qubits. Now the Euler characteristic of the torus is zero, and therefore F + V = E, showing that this procedure actually doubles the number of physical qubits.
We have now arrived at a description of the toric code (and its cousin the surface code) that one can often find as a definition in the literature but which somehow obscures the relation to the surface topology a bit.
- We start with a lattice L with E edges and identify opposite borders
- On each vertex, we place a data qubit
- On each face, we place a measurement qubit called a Z-qubit
- On each vertex, we place a measurement qubit called an X-qubit
- To each X-qubit, we associate the operator that acts as a bit flip on the four data qubits next to the measurement qubit
- To each Z-qubit, we associate the operator that acts a a phase flip on the four data qubits next to the measurement qubit
Thus every data qubit is acted on by four operators, the two Z-operators corresponding to the adjacent faces and the two X-operators corresponding to the adjacent vertices. The additional measurement qubits – indicated by white circles in contrast to the dark circles being the data qubits – are shown below.
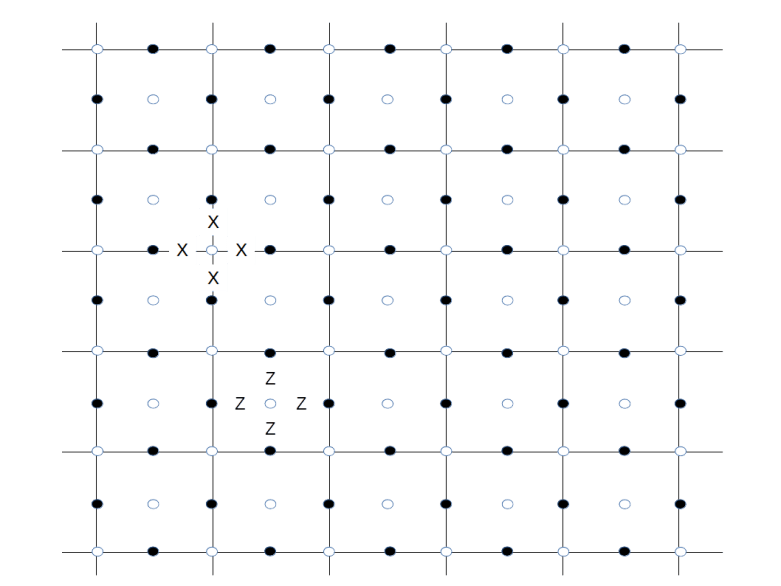
For one face and one vertex, we have indicated the associated operators Xv and Zf by adding letters X and Z to show how these operators act on the nearby data qubits. This is the graphical representation typically used in the literature (like [3]). Note that some authors use different conventions and associate Z-operators with faces and X-operators with vertices, but this is of course completely equivalent due to the duality relations between a lattice and a dual lattice.
This completes our short introduction to toric codes. In the next post in my series on quantum error correction, we will pass on to a planar geometry which turns the toric code into a surface code.
References
1 A. Kitaev, Fault-tolerant quantum computation by anyons, arXiv:quant-ph/9707021
2. H. Bombin, An introduction to topological quantum codes, in Quantum error correction, edited by D.A. Lidar and T.A. Brun, Cambridge University Press, New York, 2013, available as arXiv:quant-ph/1311.0277
3. A.G. Fowler, M. Mariantoni, J.M. Martinis, A.N. Cleland, Surface codes: Towards practical large-scale quantum computation, arXiv:1208.0928v2



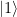 and to which we apply a sequence of controlled multiplications by powers of a, and a working register, in which we do a quantum Fourier transform in the second step. The primary register needs to hold M=15, so we need four qubits there. For the working register, we use three qubits, which is the smallest possible choice, to keep the number of gates small.
and to which we apply a sequence of controlled multiplications by powers of a, and a working register, in which we do a quantum Fourier transform in the second step. The primary register needs to hold M=15, so we need four qubits there. For the working register, we use three qubits, which is the smallest possible choice, to keep the number of gates small. . Thus we only need to implement a unitary transformation which conditionally maps the state
. Thus we only need to implement a unitary transformation which conditionally maps the state 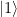 to the state
to the state  . In binary notation, eleven is 1011, and we therefore simply need to conditionally flip qubits 3 and 1. We also need a Pauli X gate in the primary register to build the initial state
. In binary notation, eleven is 1011, and we therefore simply need to conditionally flip qubits 3 and 1. We also need a Pauli X gate in the primary register to build the initial state 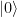 and Hadamard gates in the working register to create the initial superposition. Thus the first part of our circuit looks as follows.
and Hadamard gates in the working register to create the initial superposition. Thus the first part of our circuit looks as follows.


 , and we can again implement this by two conditional bit flips, i.e. two CNOT gates.
, and we can again implement this by two conditional bit flips, i.e. two CNOT gates.





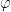 between zero and one. The quantum phase estimation is designed to determine (or at least approximate) the number
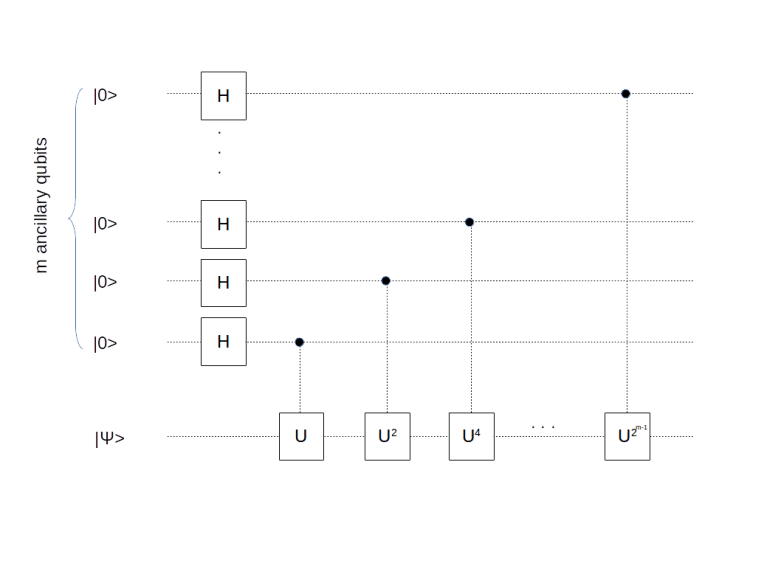
between zero and one. The quantum phase estimation is designed to determine (or at least approximate) the number 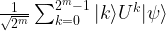
 , with binary digits ki, we can of course write Uk as
, with binary digits ki, we can of course write Uk as![U^k = \prod_i \big[ U^{2^i} \big]^{k_i}](https://s0.wp.com/latex.php?latex=U%5Ek+%3D+%5Cprod_i+%5Cbig%5B+U%5E%7B2%5Ei%7D+%5Cbig%5D%5E%7Bk_i%7D++&bg=FFFFFF&fg=000&s=1&c=20201002)
![\frac{1}{\sqrt{2^m}} \sum_{k=0}^{2^m - 1} |k \rangle U^k |\psi \rangle = \frac{1}{\sqrt{2^m}} \big[\sum_{k=0}^{2^m - 1} e^{2\pi i \varphi k} |k \rangle \big] \otimes |\psi \rangle](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B%5Csqrt%7B2%5Em%7D%7D+%5Csum_%7Bk%3D0%7D%5E%7B2%5Em+-+1%7D+%7Ck+%5Crangle+U%5Ek+%7C%5Cpsi+%5Crangle+%3D++%5Cfrac%7B1%7D%7B%5Csqrt%7B2%5Em%7D%7D+%5Cbig%5B%5Csum_%7Bk%3D0%7D%5E%7B2%5Em+-+1%7D+e%5E%7B2%5Cpi+i+%5Cvarphi+k%7D+%7Ck+%5Crangle+%5Cbig%5D+%5Cotimes++%7C%5Cpsi+%5Crangle++&bg=FFFFFF&fg=000&s=1&c=20201002)
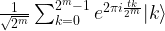
 ! So we can obtain t and therefore
! So we can obtain t and therefore 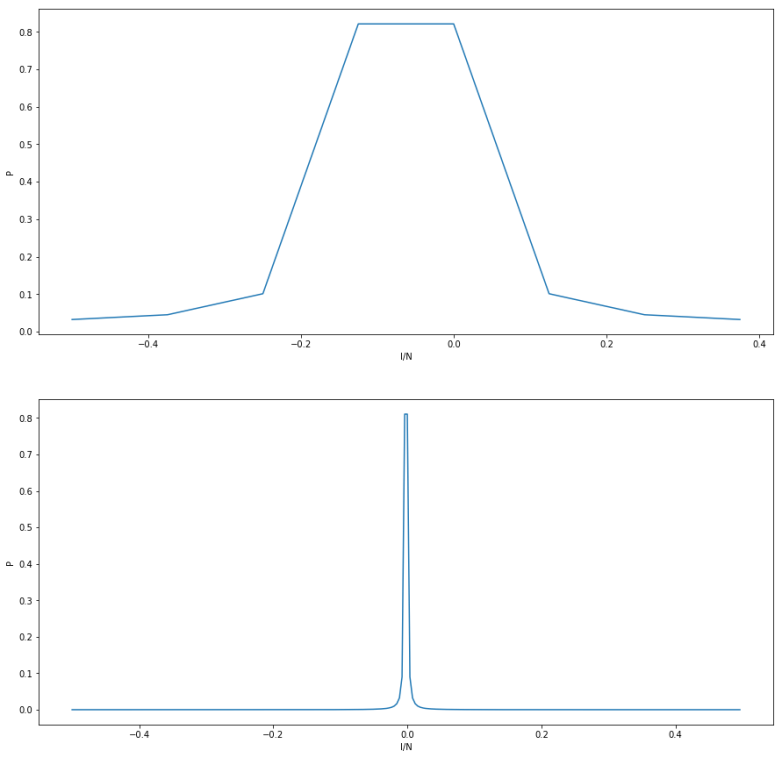
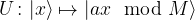
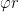 is an integer. We can therefore use the phase estimation algorithm to obtain the period r.
is an integer. We can therefore use the phase estimation algorithm to obtain the period r. 