In the previous post, we have seen how iterators and generators can be used in Python to implement coroutines. With this approach, a coroutine is simply a function that contains a yield statement somewhere. This is nice, but makes the code hard to read, as the function signature does not immediately give you a hint whether it is a generator function or not. Newer Python releases introduce a way to natively designate functions as asynchronous functions that behave similar to coroutines and can be waited for using the new async and await syntax.
Native coroutines in Python
We have seen that coroutines can be implemented in Python based on generators. A coroutine, then, is a generator function which runs until it is suspended using yield. At a later point in time, it can be resumed using send. If you know Javascript, this will sound familiar – in fact, with ES6, Javascript has introduced a new syntax to declare generator functions. However, most programmers will probably be more acquainted with the concepts of an asynchronous functions in Javascript and the corresponding await and async keyword.
Apparently partially motivated by this example and by the increasing popularity of asynchronous programming models, Python now has a similar concept that was added to the language with PEP-492 which introduces the same keywords into Python as well (as a side note: I find it interesting to see how these two languages have influenced each other over the last couple of years).
In this approach, a coroutine is a function marked with the async keyword. Similar to a generator-based coroutine which runs up to the next yield statement and then suspends, a native coroutine will run up to the next await statement and then suspend execution.
The argument to the await statement needs to be an awaitable object, i.e. one of the following three types:
- another native coroutine
- a wrapped generator-based coroutine
- an object implementing the __await__ method
Let us look at each of these three options in a bit more detail
Waiting for native coroutines
The easiest option is to use a native coroutine as target for the await statement. Similar to a yield from, this coroutine will then resume execution and run until it hits upon an await statement itself. An example for such a coroutine is asyncio.sleep(), which sleeps for the specified number of seconds. You can define your own native coroutine and await the sleep coroutine to suspend your coroutine until a certain time has passed.
async def coroutine():
await asyncio.sleep(3)
Similar to yield from, this builds a chain of coroutines that hand over control to each other. A coroutine that has been “awaited” in this way can hand over execution to a second coroutine, which in turn waits for a third coroutine and so forth. Thus await statements in a typical asynchronous flow form a chain.
Now we have seen that a chain of yield from statements typically ends with a yield statement, returning a value or None. Based on that analogy, one might think that the end of a chain of await statements is an await statement with no argument. This, however, is not allowed and would also not appear to make sense, after all you wait “for something”. But if that does not work, where does the chain end?
Time to look at the source code of the sleep function that we have used in our example above. Here we need to distinguish two different cases. When the argument is zero, we immediately delegate to __sleep0, which is actually very short (we will look at the more general case later).
@types.coroutine
def __sleep0():
yield
So this is a generator function as we have seen it in the last post, with an additional annotation, which turns it into a generator-based coroutine.
Generator-based coroutines
PEP-492 emphasizes that native coroutines are different from generator-based coroutines, and also enforces this separation. It is, for instance, an error to execute a yield inside a native coroutine. However, there is some interoperability between these two worlds, provided by the the decorator *types.coroutine that we have seen in action above.
When we decorate a generator-based coroutine with this decorator, it becomes a native coroutine, which can be awaited. The behaviour is very similar to yield from, i.e. if a native coroutine A awaits a generator-based coroutine B and is run via send, then
- if B yields a value, this value is directly returned to the caller of A.send() as the result of the send invocation
- at this point, B suspends
- if we call A.send again, this will resume B (!), and the yield inside B will evaluate to the argument of the send call
- if B returns or raises a StopIteration, the return value respectively the value of the StopIteration will be visible inside A as the value of the await statement
Thus in the example of asyncio.sleep(0), generator-based coroutines are the answer to our chicken-and-egg issue and provide the end point for the chain of await statements. If you go back to the code of sleep, however, and look at the more general case, you will find that this case is slightly more difficult, and we will only be able to understand it in the next post once we have discussed the event loop. What you can see, however, is that eventually, we wait for something called a future, so time to talk about this in a bit more detail.
Iterators as future-like objects
Going back to our list of things which can be waited for, we see that by now, we have touched on the first two – native coroutines and generator-based coroutines. A future (and the way it is implemented in Python) is a good example for the third case – objects that implement __await__.
Following the terminology used in PEP-492, any object that has an __await__ method is called a future-like object, and any such object can be the target of an await statement. Note that both a native coroutine as well as a generator-based coroutine have an __await__ method and are therefore future-like objects. The __await__ method is supposed to return an iterator, and when we wait for an object implementing __await__, this iterator will be run until it yields or returns.
To make this more tangible, let us see how we can use this mechanism to implement a simple future. Recall that a future is an object that is a placeholder for a value still to be determined by an asynchronous operation (if you have ever worked with Javascript, you might have heard of promises, which is a very similar concept). Suppose, for instance, we are building a HTTP library which has a method like fetch to asynchronously fetch some data from a server. This method should return immediately without blocking, even though the request is still ongoing. So it cannot yet return the result of the request. Instead, it can return a future. This future serves as a placeholder for the result which is still to come. A coroutine could use await to wait until the future is resolved, i.e. the result becomes available.
Of course we will not write a HTTP client today, but still, we can implement a simple future-like object which is initially pending and yields control if invoked. We can then set a value on this future (in reality, this would be done by a callback that triggers when the actual HTTP response arrives), and a waiting coroutine could then continue to run to retrieve the value. Here is the code
class Future:
def __await__(self):
if not self._done:
yield
else:
return self._result
def __init__(self):
self._done = False
def done(self, result):
self._result = result
self._done = True
When we initially create such an object, its status will be pending, i.e. the attribute _done will be set to false. Awaiting a future in that state will run the coroutine inside the __await__ method which will immediately yield, so that the control goes back to the caller. If now some other asynchronous task or callback calls done, the result is set and the status is updated. When the coroutine is now resumed, it will return the result.
To trigger this behaviour, we need to create an instance of our Future class and call await on it. Now using await is only possible from within a native coroutine, so let us write one.
async def waiting_coroutine(future):
data = None
while data is None:
data = await future
return data
Finally, we need to run the whole thing. Similar as for generator-based coroutines, we can use send to advance the coroutine to the next suspension point. So we could something like this.
future=Future()
coro = waiting_coroutine(future)
# Trigger a first iteration - this will suspend in await
assert(None == coro.send(None))
# Mark the future as done
future.done(25)
# Now the second iteration should complete the coroutine
try:
coro.send(None)
except StopIteration as e:
print("Got StopIteration with value %d" % e.value)
Let us see what is happening behind the scenes when this code runs. First, we create the future which will initially be pending. We then make a call to our waiting_coroutine. This will not yet start the process, but just build and return a native coroutine, which we store as coro.
Next, we call send on this coroutine. As for a generator-based coroutine, this will run the coroutine. We reach the point where our coroutine waits for the future. Here, control will be handed over to the coroutine declared in the __await__ method of the future, i.e. this coroutine will be created and run. As _done is not yet set, it will yield control, and our send statement returns with None as result.
Next, we change the state of the future and provide a value, i.e we resolve the future. When we now call send once more, the coroutine is resumed. It picks up where it left, i.e. in the loop, and calls await again on the future. This time, this returns a value (25). This value is returned, and thus the coroutine runs to completion. We therefore get a StopIteration which we catch and from which we can retrieve the value.
The event loop
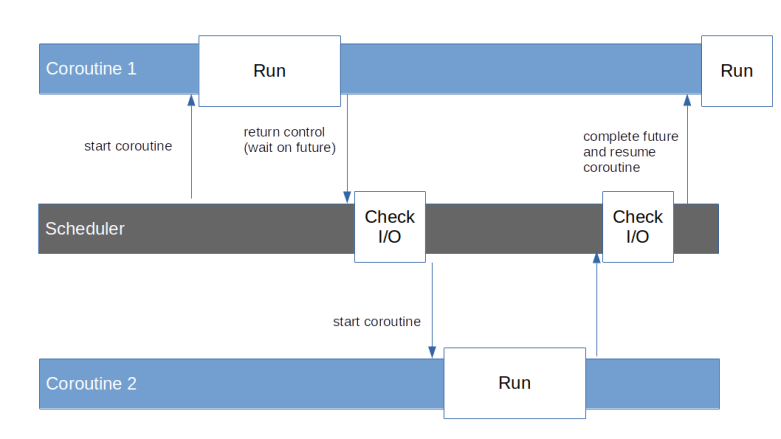
So far, we have seen a few examples of coroutines, but always needed some synchronous code that uses send to advance the coroutine to the next yield. In a real application, we would probably have an entire collection of coroutines, representing various tasks that run asynchronously. We would then need a piece of logic that acts as a scheduler and periodically goes through all coroutines, calls send on them to advance them to the point at which they return control by yielding, and look at the result of the call to determine when the next attempt to resume the coroutine should be made.
To make this useful in a scenario where we wait for other asynchronous operations, like network traffic or other types of I/O operations, this scheduler would also need to check for pending I/O and to understand which coroutine is waiting for the result of a pending I/O operation. Again, if you know Javascript, this concept will sound familiar – this is more or less what the event loop built into every browser or the JS engine running in Node.js is doing. Python, however, does not come with a built-in event loop. Instead, you have to select one of the available libraries that implement such a loop, for instance the asyncio library which is distributed with CPython. Using this library, you define tasks which wrap native coroutines, schedule them for execution by the event loop and allow them to wait for e.g. the result of a network request represented by a future. In a nutshell, the asyncio event loop is doing exactly this

In the next post, we will dig a bit deeper into the asyncio library and the implementation of the event loop.