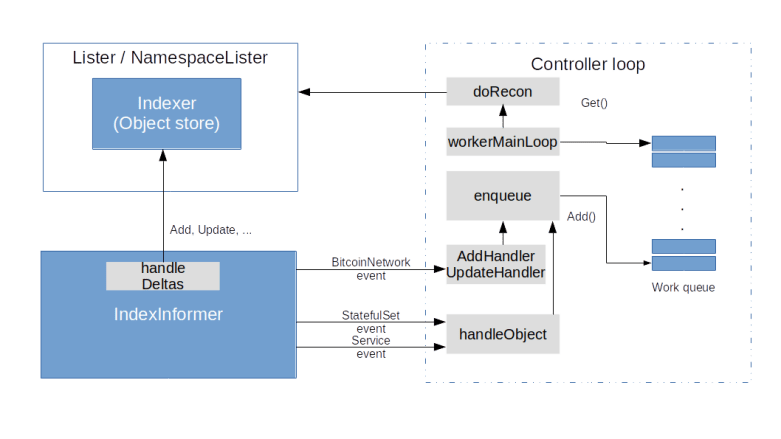
Our bitcoin controller now has the basic functionality that we expect – it can synchronize the to-be state and the as-is state and update status information. However, to be really useful, a few things are still missing. Most importantly, we want our nodes to form a real network and need to establish a mechanism to make them known to each other. Specifically, we will use RPC calls to exchange IP addresses between the nodes in our network so that they can connect.
Step 10: talking to the bitcoin daemon
To talk to the bitcoin daemon, we will use its JSON RPC interface. We thus need to be able to send and receive HTTP POST requests and to serialize and de-serialize JSON. Of course there are some libraries out there that could do this for us, but it is much more fun to implement our own bitcoin client in Go. For that purpose, we will use the packages HTTP and JSON.
While developing this client, it is extremely useful to have a locally running bitcoind. As we already have a docker image, this is very easy – simply run
$ docker run -d -p 18332:18332 christianb93/bitcoind
on your local machine (assuming you have Docker installed). This will open port 18332 which you can access using for instance curl, like
$ curl --user 'user:password' --data '{"jsonrpc":"1.0","id":"0","method":"getnetworkinfo","params":[]}' -H 'content-type:text/plain;' http://localhost:18332
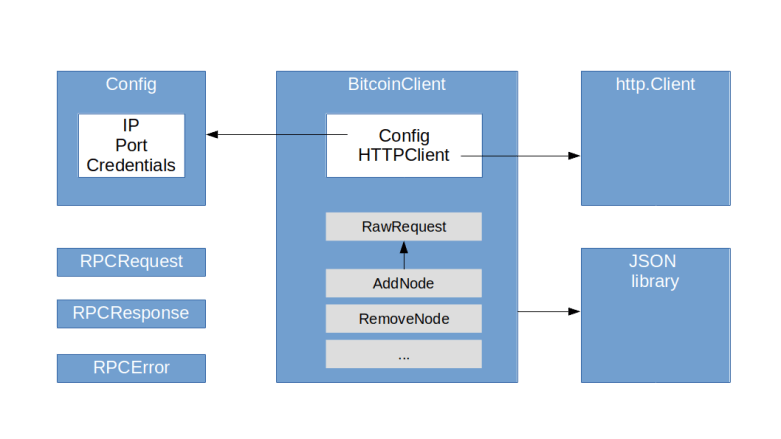
Our client will be very simple. Essentially, it consists of the following two objects.
- A Config represents the configuration data needed to access an RPC server (IP, port, credentials)
- A BitcoinClient which is the actual interface to the bitcoin daemon and executes RPC calls
A bitcoin client holds a reference to a configuration which is used as default if no other configuration is supplied, and a HTTP client. Its main method is RawRequest which creates an RPC request, adds credentials and parses the response. No error handling to e.g. deal with timeouts is currently in place (this should not be a real restriction in practice, as we have the option to re-queue our processing anyway). In addition to this generic function which can invoke any RPC method, there are specific functions like AddNode, RemoveNode and GetAddedNodeList that accept and return Go structures instead of JSON objects. In addition, there are some structures to model RPC request, RPC responses and errors.
Node that our controller now needs to run inside the cluster, as it needs to access the bitcoind RPC servers (there might be ways around this, for instance by adding a route on the host similar to what minikube tunnel is doing for services, but I found that this is easily leads to IP range conflicts with e.g. Docker).
Step 11: adding new nodes to our network
When we bring up a network of bitcoin nodes, each node starts individually, but is not connected to any other node in the network – in fact, if we bring up three nodes, we maintain three isolated blockchains. For most use cases, this is of course not what we want. So let us now try to connect the nodes to each other.
To do this, we will manipulate the addnode list that each bitcoind maintains. This list is like a database of known nodes to which the bitcoind will try to connect. Before we automate this process, let us first try this out manually. Bring up the network and enter
$ ip1=$(kubectl get bitcoinnetwork my-network -o json | jq -r ".status.nodes[1].ip") $ kubectl exec my-network-sts-0 -- /usr/local/bin/bitcoin-cli -regtest -conf=/bitcoin.conf addnode $ip1 add
This will find out the (node) IP address of the second node using our recently implemented status information and invoke the JSON-RPC method addnode on the first node to connect the first and the second node. We can now verify that the IP address of node 1 has been added to the addnode list of node 0 and that node 1 has been added to the peer list of node 0, but also node 0 has been added to the peer list of node 1.
$ kubectl exec my-network-sts-0 -- /usr/local/bin/bitcoin-cli -regtest -conf=/bitcoin.conf getaddednodeinfo $ kubectl exec my-network-sts-0 -- /usr/local/bin/bitcoin-cli -regtest -conf=/bitcoin.conf getpeerinfo $ kubectl exec my-network-sts-1 -- /usr/local/bin/bitcoin-cli -regtest -conf=/bitcoin.conf getpeerinfo
We can now repeat this process with the third node – we again make the node known to node 0 and then get the list of nodes each nodes knows about.
$ ip2=$(kubectl get bitcoinnetwork my-network -o json | jq -r ".status.nodes[2].ip") $ kubectl exec my-network-sts-0 -- /usr/local/bin/bitcoin-cli -regtest -conf=/bitcoin.conf addnode $ip2 add $ kubectl exec my-network-sts-0 -- /usr/local/bin/bitcoin-cli -regtest -conf=/bitcoin.conf getpeerinfo $ kubectl exec my-network-sts-1 -- /usr/local/bin/bitcoin-cli -regtest -conf=/bitcoin.conf getpeerinfo $ kubectl exec my-network-sts-2 -- /usr/local/bin/bitcoin-cli -regtest -conf=/bitcoin.conf getpeerinfo
We see that
- Node 0 knows both node 1 and node 2
- Node 1 knows only node 0
- Node 2 knows only node 1
So in contrast to my previous understanding, the nodes do not automatically connect to each other when there is a node that is known to all of them. After some research, I suspect that this is because bitcoind puts addresses into buckets and only connects to one IP address in the bucket. As IP addresses in the same subnet go into the same bucket, only one connection will be made by default. To avoid an artificial dependency on node 0, we therefore explicitly connect each node to any other node in the network.
To do this, we create an additional function syncNodes which is called during the reconciliation if we detect a change in the node list. Within this function, we then simply loop over all nodes that are ready and, for each node:
- Submit the RPC call addednodeinfo to get a list of all nodes that have previously been added
- For each node that is not in the list, add it using the RPC call addnode with command add
- For each node that is in the list, but is no longer ready, use the same RPC call with command remove to remove it from the list
As there might be another worker thread working on the same network, we ignore, for instance, errors that a bitcoind returns when we try to add a node that has already been added before, similarly for deletions.
Time again to run some tests. First, let us run the controller and bring up a bitcoin network called my-network (assuming that you have cloned my repository)
$ kubectl apply -f deployments/controller.yaml $ kubectl apply -f deployments/testNetwork.yaml
Wait for some time – somewhere between 30 and 45 seconds – to allow all nodes to come up. Then, inspect the log file of the controller
$ kubectl logs bitcoin-controller -n bitcoin-controller
You should now see a few messages indicating that the controller has determined that nodes need to be added to the network. To verify that this worked, we can print all added node lists for all three instances.
$ for i in {0..2};
do
ip=$(kubectl get pod my-network-sts-$i -o json | jq -r ".status.podIP")
echo "Connectivity information for node $i (IP $ip):"
kubectl exec my-network-sts-$i -- /usr/local/bin/bitcoin-cli -regtest -conf=/bitcoin.conf getaddednodeinfo | jq -r ".[].addednode"
done
This should show you that in fact, all nodes are connected to each other – each node is connected to all other nodes. Now let us connect to one node, say node 0, and mine a few blocks.
$ kubectl exec my-network-sts-0 -- /usr/local/bin/bitcoin-cli -regtest -conf=/bitcoin.conf generate 101
After a few seconds, we can verify that all nodes have synchronized the chain.
$ for i in {0..2};
do
ip=$(kubectl get pod my-network-sts-$i -o json | jq -r ".status.podIP")
blocks=$(kubectl exec my-network-sts-$i -- /usr/local/bin/bitcoin-cli -regtest -conf=/bitcoin.conf getblockchaininfo | jq -r ".blocks")
echo "Node $i (IP $ip) has $blocks blocks"
done
This should show you that all three nodes have 101 blocks in their respective chain. What happens if we bring down a node? Let us delete, for instance, pod 0.
$ kubectl delete pod my-network-sts-0
After a few seconds, the stateful set controller will have brought up a replacement. If you wait for a few more seconds and repeat the command above, you will see that the new node has been integrated into the network and synchronized the blockchain. In the logfiles of the controller, you will also see that two things have happened (depending a bit on timing). First, the controller has realized that the node is no longer ready and uses RPC calls to remove it from the added node lists of the other nodes. Second, when the replacement node comes up, it will add this node to the remaining nodes and vice versa, so that the synchronization can take place.
Similarly, we can scale our deployment. To do this, enter
$ kubectl edit bitcoinnetwork my-network
Then change the number of replicas to four and save the file. After a few seconds, we can inspect the state of the blockchain on the new node and find that is also has 101 blocks.
$ kubectl exec my-network-sts-3 -- /usr/local/bin/bitcoin-cli -regtest -conf=/bitcoin.conf getblockchaininfo
Again, the log files of the controller tell us that the controller has detected the new node and added it to all other nodes. Similarly, if we use the same procedure to scale down again, the nodes that are removed from the stateful set will also be removed from the added node lists of the remaining nodes.
We now have the core functionality of our controller in place. As in the previous posts, I have pushed the code into a new tag on GitHub. I have also pushed the latest image to Docker Hub so that you can repeat the tests described above without building the image yourself. In the next post, we will start to add some more meat to our controller and to implement some obvious improvements – proper handling of secrets, for instance.