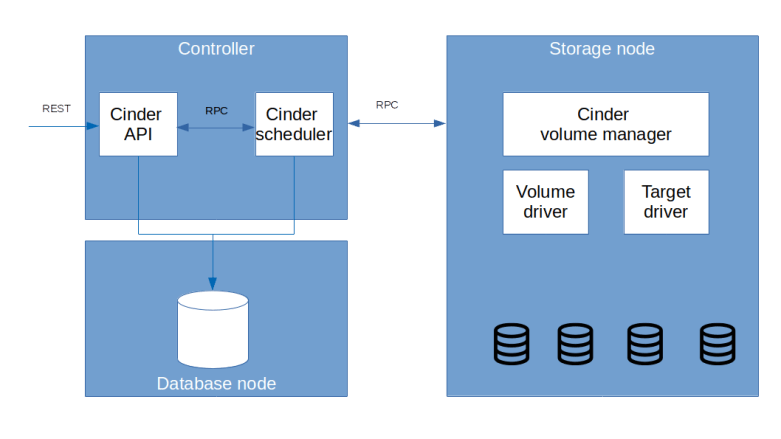
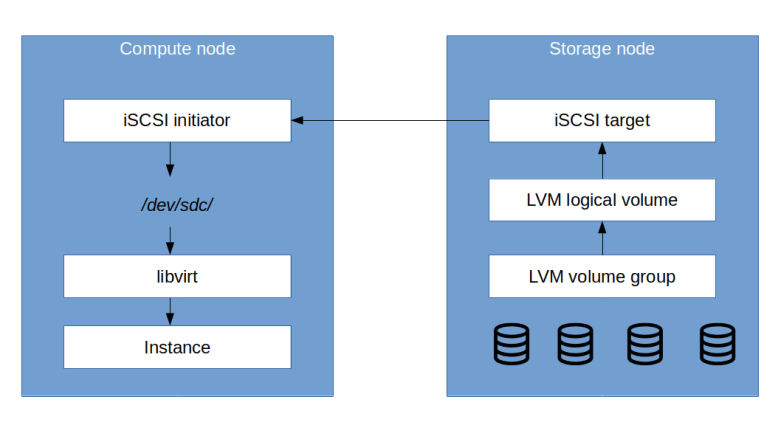
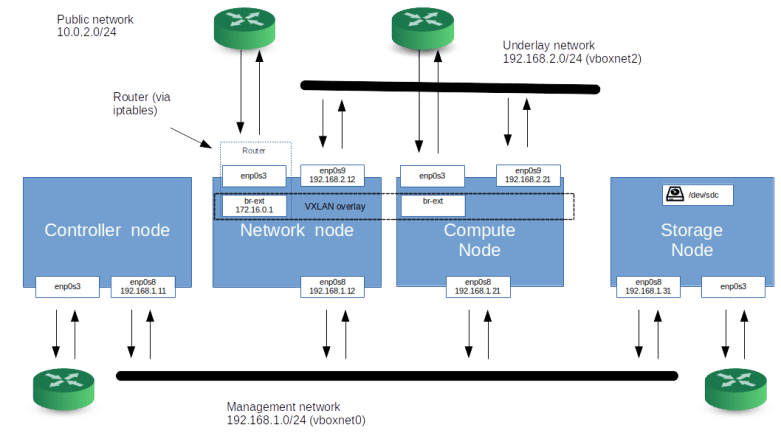
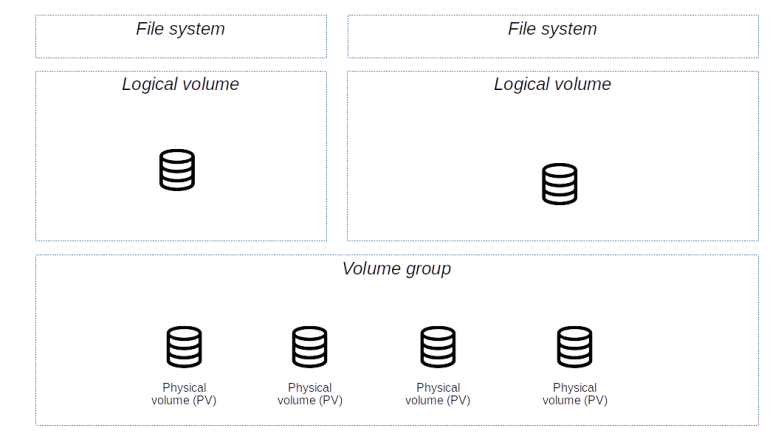
To understand Cinder, the block device component of OpenStack, you will need to be familiar with some terms that originate from the world of data center networks like SCSI, SAN, LUN and so forth. In this post, we will take a short look at these topics to be prepared for our upcoming installation and configuration of Cinder.
Storage networks
In the early days of computing, when persistent mass storage was introduced, storage devices where typically directly attached to a server, similar to the hard disk in your PC or laptop computer which is sitting in same enclosure as your motherboard and directly connected to it. In order to communicate with such a storage device, there would usually be some sort of controller on the motherboard which would use some low-level protocol to talk to a controller on the storage device.
A protocol to achieve this which is (still) very popular in the world of Intel PCs is the SATA protocol, but this is by far not the only one. In most enterprise storage solutions, another protocol called SCSI (small computer system interface) is still dominating, which was originally also used in the consumer market by companies like Apple. Let us quickly summarize some terms that are relevant when dealing with SCSI based devices.
First, every device on a SCSI bus has a SCSI ID. As a typical SCSI storage device may expose more than one disk, these disks are represented by logical unit numbers (LUNs). Generally speaking, every object that can receive a SCSI command is a logical unit (there are also logical units that do not represent actuals disks, but controllers). Each SCSI device can encompass more than one LUN. A SCSI device could, for instance, be a RAID array that exposes two logical disks, and each of these disks would then be addressable as a separate LUN.
When devices communicate over the SCSI bus, one of them acts as initiator and one of them acts as target. If, for instance, a host controller wants to read data from a SCSI hard disk, the host controller is the initiator, and the controller of the hard disk is the target. The initiator can send commands like “read a block” to the target, and the target will reply with data and / or a status code.
Now imagine a data center in which there is a large number of servers, each of which being equipped with a direct attached storage device.
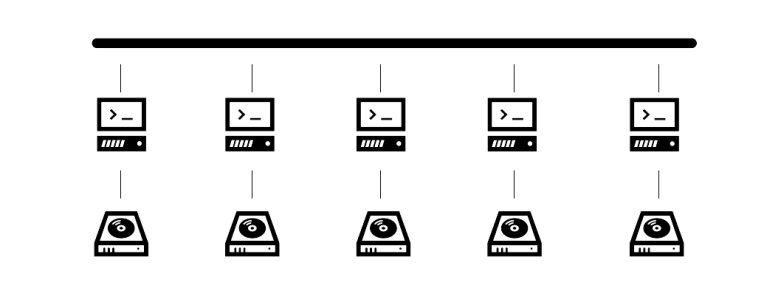
The servers might be connected by a network, but each disk (or other storage device like tape or a removable media drive) is only connected to one server. This setup is simple, but has a couple of drawbacks. First, if there is some space available on a disk, it cannot easily be made available for other servers, so that the overall utilization is low. Second, topics like availability, redundancy, backups, proper cooling and so forth have to be done individually for each server. And, last but not least, physical maintenance can be difficult if the servers are distributed over several locations.
For those reasons, an alternative architecture has evolved over time, in which storage capacity is centralized. Instead of having one disk attached to each server, most of the storage capacity is moved into a central storage appliance. This appliance is then connected to each server via a (typically dedicated) network, hence the term SAN – storage attached network that describes this sort of architecture (often, each server would still have a small disk as a primary partition for the operating system and booting, but not even this is actually required).
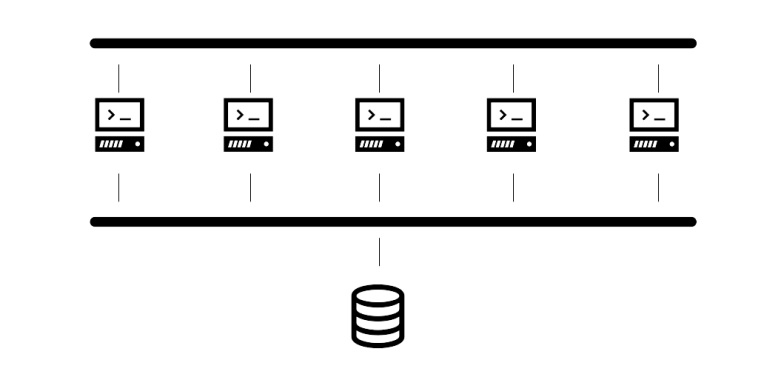
Of course, the storage in such a scenario is typically not just an ordinary disk, but an entire array of disks, combined into a RAID array for better performance and redundancy, and often equipped with some additional capabilities like de-duplication, instant copy, a management interface and so forth.
Very often, storage networks are not based on Ethernet and IP, but on the FibreChannel network protocol stack. However, there is also a protocol called iSCSI which can be used to run SCSI on top of TCP/IP, so that a SAN can be leveraging existing IP-based networks and technologies – more on this in the next section.
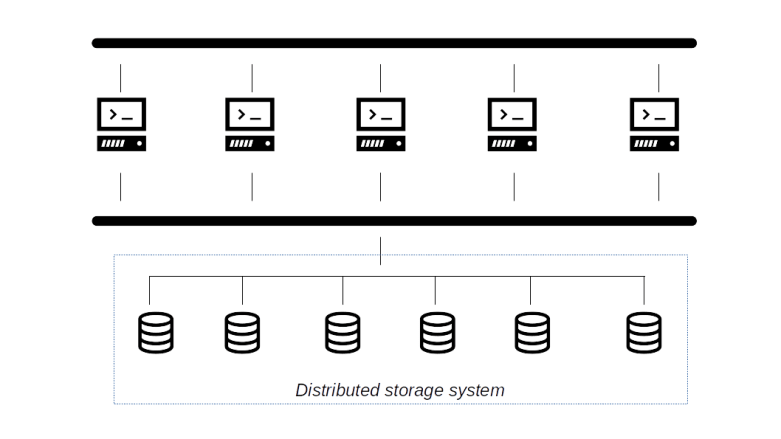
Finally, there is a third possible architecture (which we do not discuss in detail in this post), which is becoming increasingly popular in the context of cloud and container platforms – distributed storage systems. With this approach, storage is still separated from the compute capacity and connected using a network, but instead of having a small number of large storage appliances that pool the available storage capacity, these solutions take a comparatively large number of smaller nodes, often commodity hardware, which distribute and replicate data to form a large, highly available virtual storage system. Examples for this type of solutions are the HDFS file system used by Hadoop, Ceph or GlusterFS.
The iSCSI protocol
Let us now take a closer look at the iSCSI protocol. This protocol, standardized in RFC 7143 (which is replacing earlier RFCs), is a transport protocol for SCSI which can be used to build storage networks utilizing SCSI capable devices based on an underlying IP network.
In an iSCSI setup, an iSCSI initiator talks to an iSCSI target using one or more TCP/IP connections. The combination of all active sessions between an initiator and a target is called a session, and is roughly equivalent to what is known as I_T nexus (initiator – target nexus) in the SCSI protocol. Each session is identified by a session ID, and each connection within a session has a connection ID. Logically, a session describes an ongoing communication between an initiator and a target, but the traffic can be spread across several TCP/IP connections to support redundancy and failover.
Both, the initiator and the target, are identified by a unique name. The RFC defines several ways to build iSCSI names. One approach is to use a combination of
- The qualifier iqn to mark the name as an iSCSI qualified name
- a (reversed) domain name which is supposed to be owned by whoever assigns the name so that the resulting name will be unique
- a date (yyyy-mm) between the leading iqn and the domain name which is a date at which the domain ownership was valid (to be able to deal with changing domain name ownerships)
- A colon followed by a postfix to make the name unique within the domain
As I own the domain leftasexercise.com since 2018, an example for a iSCSI name that I could use would be
iqn.2018-12.com.leftasexercise:foo
To establish a session, an initiator has to perform a login operation on the iSCSI target. During login, features are negotiated and authentication is performed. The standard allows for the use of Kerberos, CHAP and Secure remote password (SRP), but the only protocol that all implementations must support is CHAP (more on this below when we actually try this out). Once a login has completed, the session enters the full feature phase. A session can also be a discovery session in which only the functionality to discover valid target names is available to the initiator.
Note that the iSCSI protocol decouples the iSCSI node name from the network name. The node names that we have discussed above do typically not resolve to an IP address under which a target would be reachable. Instead, the network connection layer is modeled by the concept of a network portal. For a server, the network portal is the combination of an IP address and a port number (which defaults to 3260). On the client side, a network portal is simply the IP address. Thus there is an n-m relation between portals and nodes (targets and initiators).
Suppose, for example, that we are running a software (some sort of daemon) that can emulate one or more iSCSI targets (as we will do it below). Suppose further that this daemon is listening on two different IP addresses on the server on which it is running. Then, each IP address would be one portal. Our daemon could manage an unlimited number of targets, each of which in turn offers one or more LUNs to initiators. Depending on the configuration, each target could be reachable via each IP address, i.e. portal. So our setup would be as follows.
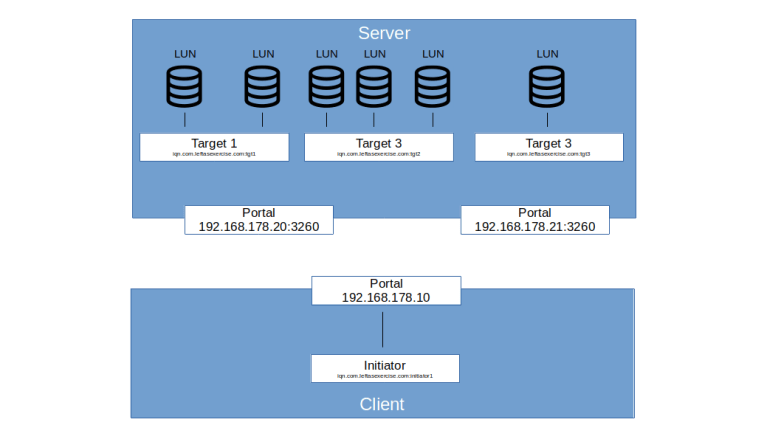
Portals can also be combined into portal groups, so that different connections within one session can be run across different portals in the same group.
Lab11: implementing iSCSI nodes on Linux
Of course, Linux is able to act as an iSCSI initiator or target, and there are several implementations for the required functionality available.
One tool which we will use in this lab is Open-iSCSI, which is an iSCSI initiator consisting of several kernel drivers and a user-space part. To run an iSCSI target, Linux also offers several options like the LIO iSCSI target or the Linux SCSI target framework TGT. As it is also used by Cinder, we will play with TGT today.
As usual, we will run our lab on virtual machines managed by Vagrant. To start the environment, enter the following commands from a terminal on your lab PC.
git clone https://github.com/christianb93/openstack-labs
cd openstack-labs/Lab11
vagrant up
This will bring up two virtual machines called client and server. Both machines will be connected to a virtual network, with the client IP address being 192.168.1.12 and the server IP address being 192.168.1.11. On the server, our Vagrantfile attaches an additional disk to the virtual SCSI controller of the VirtualBox instance, which is visible from the OS level as /dev/sdc. You can use lsscsi, lsblk -O or blockdev --report to get a list of the SCSI devices attached to both client and server.
Now let us start the configuration of TGT on the server. There are two ways to do this. We will use the tool tgtadm to submit our commands one by one. Alternatively, there is also tgt-admin which is a Perl script that translates a configuration (typically stored in /etc/tgt/target.conf) into calls to tgtadm which makes it easier to re-create a configuration at boot time.
The target daemon itself is started by systemctl at boot time and is both listening on port 3260 on all interfaces and on a Unix domain socket in /var/run/tgt/. This socket is called the control port and used by the tgtadm tool to talk to the daemon.
TGT is able to use different drivers to send and receive SCSI commands. In addition to iSCSI, the second protocol currently supported is iSER which is a transport protocol for SCSI using remote direct memory access (RDMA). So most tgtadm commands start with the switch –lld iscsi to select the iSCSI driver. Next, there is typically a switch that indicates the type of object that the command operates on, plus some operation like new, delete and so forth. To see this in action, let us first create a new target and then list all existing targets on the server.
vagrant ssh server
sudo tgtadm \
--lld iscsi \
--mode target \
--op new \
--tid 1 \
--targetname iqn.2018-12.com.leftasexercise:tgt1
sudo tgtadm \
--lld iscsi \
--mode target \
--op show
Here the target name is the iSCSI node name that our target will receive, and the target ID (tid) is the TGT internal ID under which the target will be managed. From the output of the last command, we see that the target is existing and ready, but there is no active session (I_T nexus) yet and there is only one LUN, which is a default LUN added by TGT automatically (in fact, the SCSI-3 standard mandates that there is always a LUN 0 and that (SCSI Architecture model, section 4.9.2), All SCSI devices shall accept LUN 0 as a valid address. For SCSI devices that support the hierarchical addressing model the LUN 0 shall be the logical unit that an application client addresses to determine information about the SCSI target device and the logical units contained within the SCSI target device.
Now let us create an actual logical unit and add it to our target. The tgt daemon is able to expose either an entire device as a SCSI LUN or a flat file. We will create two LUNs, to try out both alternatives. We start by adding our raw block device /dev/sdc to the newly created target.
sudo tgtadm \
--lld iscsi \
--mode logicalunit \
--op new \
--tid 1 \
--lun 1 \
--backing-store /dev/sdc
Next, we create a disk image with a size of 512 MB and add that disk image as LUN 2 to our target.
tgtimg \
--op new \
--device-type disk \
--size=512 \
--type=disk \
--file=/home/vagrant/disk.img
sudo tgtadm \
--lld iscsi \
--mode logicalunit \
--op new \
--tid 1 \
--lun 2 \
--backing-store /home/vagrant/disk.img
Note that the backing store needs to be an absolute path name, otherwise the request will fail (which makes sense, as it needs to be evaluated by the target daemon).
When we now display our target once more, we see that two LUNs have been added, LUN 1 corresponding to /dev/sdc and LUN 2 corresponding to our flat file. To make this target usable for a client, however, one last step is missing – we need to populate the access control list (ACL) of the target, which determines which initiators are permitted to access the target. We can specify either an IP address range (CIDR range), an individual IP address or the keyword ALL. Alternatively, we could also allow access for a specific initiator, identified by its iSCSI name. Here we allow access from our private subnet.
sudo tgtadm \
--lld iscsi \
--mode target \
--op bind \
--tid 1 \
-I 192.168.1.0/24
Now we are ready to connect a client to our iSCSI target. For that purpose, open a second terminal window and enter the following commands.
vagrant ssh client
sudo iscsiadm \
-m discovery \
-t sendtargets \
-p 192.168.1.11:3260
Here we SSH into the client and use the Open-iSCSI command line client to run a discovery session against the portal 192.168.1.11:3260, asking the server to provide a list of all targets available on that portal. The output will be a list of all targets (only one in our case), i.e. in our case we expect
192.168.1.11:3260,1 iqn.2018-12.com.leftasexercise:tgt1
We see the portal (IP address and portal), the portal group, and the fully qualified name of the target. We can now login to this target, which will actually start a session and make our LUNs available on the client.
sudo iscsiadm \
-m node \
-T iqn.2018-12.com.leftasexercise:tgt1 \
--login
Note that Open-iSCSI uses the term node differently from the iSCSI RFC to refer to the actual server, not to an initiator or target. Let us now print some details on the active sessions and our block devices.
sudo iscsiadm \
-m session \
-P 3
lsblk
We find that the login has created two new block devices on our client machine, /dev/sdc and /dev/sdd. These two devices correspond to the two LUNs that we export. We can now handle these devices as any other block device. To try this out, let us partition /dev/sdc, add a file system (BE CAREFUL – if you accidentally run this on your PC instead of in the virtual machine, you know what the consequences will be – loss of all data on one of your hard drives!), mount it, add some test file and unmount again.
sudo fdisk /dev/sdc
# Enter n, p and confirm the defaults, then type w to write partition table
sudo mkfs -t ext4 /dev/sdc1
sudo mkdir -p /mnt/scsi
sudo mount /dev/sdc1 /mnt/scsi
echo "test" | sudo tee -a /mnt/scsi/test
sudo umount /mnt/scsi
Once this has been done, let us verify that the write operation did really go all the way to the server. We first close our session on the client again
sudo iscsiadm \
-m node \
-T iqn.2018-12.com.leftasexercise:tgt1 \
--logout
and then mount our block device on the server and see what is contains. To make the OS on the server aware of the changed partition table, you will have to run fdisk on /dev/sd once and exit immediately again.
vagrant ssh server
sudo fdisk /dev/sdc
# hit p to print table and exit
sudo mkdir -p /mnt/scsi
sudo mount /dev/sdc1 /mnt/scsi
You should now see the newly written file, demonstrating that we did really write to the disk attached to our server.
CHAP authentication with iSCSI
As mentioned above, the iSCSI standard mandates CHAP as the only authentication protocol that all implementations should understand. Let us now modify our setup and add authentication to our target. First, we need to create a user on the server. This is again done using tgtadm
sudo tgtadm \
--lld iscsi \
--mode account \
--op new \
--user christianb93 \
--password secret
Once this user has been created, it can now be bound to our target. This operation is similar to binding an IP address or initiator to the ACL.
sudo tgtadm \
--lld iscsi \
--mode account \
--op bind \
--tid 1 \
--user christianb93
If you now switch back to the client and try to login again, this will fail, as we did not yet provide any credentials. How do we tell Open-iSCSI to use credentials for this node?
It turns out that Open-iSCSI maintains a database of known nodes, which is stored as a hierarchy of flat files in /etc/iscsi/nodes. There is one file for each combination of portal and target, which also stores information on the authentication method required for a specific target. We could update these files manually, but we can also use the “update” functionality of iscsiadm to do this. For our target, we have to set three fields – the authentication method, the username and the password. Here are the commands to do this.
sudo iscsiadm \
-m node \
-T iqn.2018-12.com.leftasexercise:tgt1 \
-p 192.168.1.11,3060 \
--op=update \
--name=node.session.auth.authmethod \
--value=CHAP
sudo iscsiadm \
-m node \
-T iqn.2018-12.com.leftasexercise:tgt1 \
-p 192.168.1.11,3060 \
--op=update \
--name=node.session.auth.username \
--value=christianb93
sudo iscsiadm \
-m node \
-T iqn.2018-12.com.leftasexercise:tgt1 \
-p 192.168.1.11,3060 \
--op=update \
--name=node.session.auth.password \
--value=secret
If you repeat the login attempt now, the login should work again and the virtual block devices should again be visible.
There is much more that we could add – for instance, pass-through devices, removable media, virtual tapes, creating new portals and adding them to targets or using the iSNS naming protocol. However, this is not a series on storage technology, but a series on OpenStack. In the next post, we will therefore investigate another core technology used by OpenStack Cinder – the Linux logical volume manager LVM.