
In the previous post in my networking series, we have looked in detail at the Ethernet protocol. We now understand how two machines can communicate via Ethernet frames. We have also seen that an Ethernet frame consists of an Ethernet header and some payload which can be used to transmit data using higher level protocols.
So the road to implementing the IP protocol appears to be well-paved. We will probably need some IP header that contains metadata like source and destination, combine this header with the actual IP payload to form an Ethernet payload and happily hand this over to the Ethernet layer of our networking stack to do the real work.
Is is really that easy? Well, almost – but before looking into the subtleties, let us again take a look at a real world example which will show us that our simple approach is not so far off as you might think.
Structure of an IP packet
We will use the same example that we did already examine in the post in this series that did cover the Ethernet protocol. In this post, we used the ping command to create a network packet. Ping is using a protocol called ICMP that actually travels on top of IP, so the packet generated was in fact an IP packet. The output that we did obtain using tcpdump was
21:28:18.410185 IP your.host > your.router: ICMP echo request, id 6182, seq 1, length 64 0x0000: 0896 d775 7e80 1c6f 65c0 c985 0800 4500 0x0010: 0054 e6a3 4000 4001 6e97 c0a8 b21b c0a8 0x0020: b201 0800 4135 1826 0001 d233 de5a 0000 0x0030: 0000 2942 0600 0000 0000 1011 1213 1415 0x0040: 1617 1819 1a1b 1c1d 1e1f 2021 2223 2425 0x0050: 2627 2829 2a2b 2c2d 2e2f 3031 3233 3435 0x0060: 3637
We have already seen that the first few bytes form the Ethernet header. The last two bytes (0x0800) of the Ethernet header are called the Ethertype and indicate that the payload is to be interpreted as an IP packet. As expected, this packet again starts with a header.
The IP header can vary in length, but is at least 20 bytes long. Its exact layout is specified in RFC 791. We will now go through the individual fields in detail, but can already note that there are some interesting similarities between the Ethernet header and the IP header. Both contain a source and target address for the respective layer – the Ethernet header contains the source and target Ethernet (MAC) address, the IP header contains the source and target IP address. Also, both headers contain a field (the Ethertype for the Ethernet header and the protocol field for the IP header) that defines the type of the payload and thus establishes the link to the next layer of the protocol stack. And there are checksums – the Ethernet checksum (FCS) being located at the end of the packet while the IP checksum is part of the header.
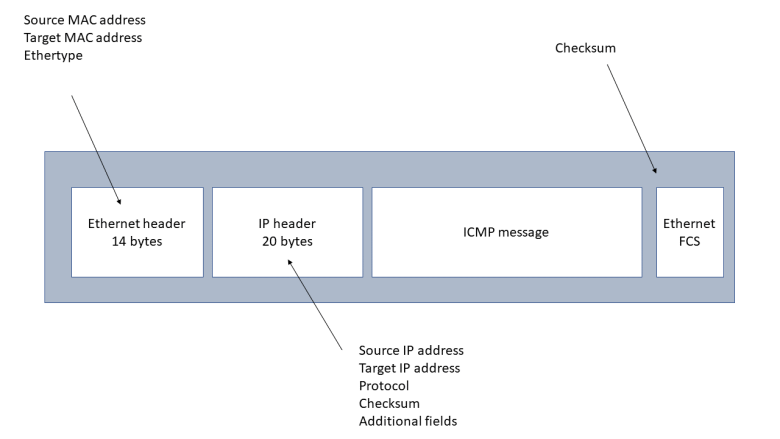
The first byte (0x45) of the IP header is in fact a combination of two fields. The first part (0x4) is the IP protocol version. The value 0x4 indicates IPv4, which is more and more replaced by IPv6. The second nibble (0x5) is the length of the header in units of 32 bit words, i.e. 20 bytes in this case.
The next byte (0x00 in our case) is called type of service and not used in our example. This field has been redefined several times in the history of the IP protocol but never been widely used – see the short article on Wikipedia for a summary.
The two bytes after the type of service are the total length of the packet, and are followed by two bytes called identification that are related to fragmentation that we will discuss further below. The same applies to
the next two bytes (0x4000 in hexadecimal notation or 0100000000000000 in binary notation).
The following two 8-bit fields are called time to live and the protocol. The time to live (TTL), 0x40 or 64 decimal in our case, specifies the time a packet will survive while being transmitted through the internet network. Whenever an IP packet is routed by a host in the network, the field will be reduced by one. When the value of the field reaches zero, the packet will be dropped. The idea of this is to avoid that a packet which cannot be delivered to its final destination circulates in the network forever. We will learn more about the process of routing in one of the following posts in this series.
The protocol field (0x1 in our case) is the equivalent of the ethertype in the Ethernet header. It indicates which protocol the payload belongs to. The valid values are specified in RFC790. Looking up the value 0x1 there, we find that it stands for ICMP as expected.
After the following two bytes which are the header checksum, we find the source address and destination address. Both addresses are encoded as 32 bit values, to be read as a sequence of four 8 bit values. The source address, for instance, is
c0 a8 b2 1b
If we translate each byte into a decimal value, this becomes
192 168 178 27
which corresponds to the usual notation 192.168.178.27 of the IP address of the PC on which the packet was generated. Similarly, the target address is 192.168.178.1.
In our case, the IP header is 20 bytes long, with the target address being the last field. The general layout allows for some additional options to be added to the header which we will not discuss here. Instead, we will now look at a more subtle point of the protocol – fragmentation.
Fragmentation
What is the underlying problem that fragmentation tries to solve? When looking at how the Ethernet protocol works, we have seen that the basic idea is to enable several stations to share a common medium. This only works because each station occupies the medium for a limited time, i.e. because an Ethernet frame has a limited size. Traditionally, an Ethernet frame is not allowed to be longer than 1518 bytes, where 18 bytes are reserved for the header and the checksum. Thus, the actual payload that one frame can carry is limited to 1500 bytes.
This number is called the maximum tranmission unit (MTU) of the medium. Other media like PPP or WLAN have different MTUs, but the size of a packet is also limited there.
Now suppose that a host on the internet wishes to assemble an IP packet with a certain payload. If the payload is so small that the payload including the header fit into the MTU of all network segments that the packet has to cross until it reaches its final destination, there is no issue. If, however, the total size of the packet exceeds the smallest MTU of all the network segments that the packet will visit (called the path MTU), we need a way to split the packet into pieces.
This is exactly what fragmentation is doing. Fragmentation refers to the process of splitting an IP packet into smaller pieces that are then reassembled by the receiver. This process involves the fields in the IP header that we have not described so far – the identification field and the two bytes immediately following it which consist of a 3 bit flags field and a 13 bit fragment offset field.
When a host needs to fragment an IP packet, it will split the payload into pieces that are small enough to pass all segments without further fragmentation (the host will typically use ICMP to determine the path MTU to the destination as we will see below). Each fragment receives its own IP header, with all fragments sharing the same values for the source IP address, target IP address, identification and protocol. The flags field is used to indicate whether a given fragment is the last one or is followed by additional fragments, and the fragment offset field indicates where the fragment belongs to in the overall message.
When a host receives fragments, it will reassemble them, using again the four fields identification, source address, target address and protocol. It can use the fragment offset to see where the fragment at hand belongs in the overall message to be assembled and the flags field to see whether a given fragment is the last one – so that the processing of the message can start – or further fragments need to be waited for. Note that the host cannot assume that the fragments arrive in the correct order, as they might travel along different network paths.
Note that the flags field also contains a bit which, if set, instructs all hosts not to fragment this datagram. Thus if the datagram exceeds one of the MTUs, it will be dropped and the sender will be informed by a so specific ICMP message. This process can be used by a sender to determine the path MTU on the way to the destination and is called path MTU discovery.
Packets can be dropped, of course, for other reasons as well. IP is inherently not establishing any guarantees that a message arrives at the destination, there are no handshakes, connections or acknowledgements. This is the purpose of the higher layer protocols like TCP that we will look at in a later post.
So far, we have ignored one point. When a host assembles an IP packet, it needs to determine the physical network interface to use for the transmission and the Ethernet address of the destination. And what if the target host is not even part of the same network? These decisions are part of a process called routing that we will discuss in the next post in this series.


 Both networks are connected by a third network, indicated by the dashed line. This network can use any other link layer technology. Each network contains a dedicated host called the gateway that connects the network to this third network.
Both networks are connected by a third network, indicated by the dashed line. This network can use any other link layer technology. Each network contains a dedicated host called the gateway that connects the network to this third network.
