You are using Github to manage your open source projects and want a CI/CD pipeline, but do not have access to a permanently available private infrastructure? Then you might want to take a look at hosted CI/CD platforms like Bitbucket pipelines, Gitlab, CircleCI – or Travis CI
When I was looking for a cloud-based integration platform for my own projects, I decided to give Travis CI a try. Travis offers builds in virtual machines, which makes it much easier to spin up local Kubernetes clusters with e.g. kind for integration testing, offers unlimited free builds for open source projects, is fully integrated with Github and makes setting up standard builds very easy – of course more sophisticated builds require more work. In this post, I will briefly describe the general usage of Travis CI, while a later post will be devoted to the design and implementation of a sample pipeline integrating Kubernetes, Travis and Helm.
Introduction to Travis CI
Getting started with Travis is easy, assuming that you already have a Github account. Simply navigate to the Travis CI homepage, sign up with your Github account and grant the required authorizations to Travis. You can then activate Travis for your Github repositories individually. Once Travis has been enabled for a repository, Travis will create a webhook so that every commit in the repository triggers a build.
For each build, Travis will spin up a virtual machine. The configuration of this machine and the subsequent build steps are defined in a file in YAML format called .travis.yml that needs to be present in the root directory of the repository.
Let us look at a very simple example to see how this works. As a playground, I have created a simple sample repository that contains a “Hello World” implementation in Go and a corresponding unit test. In the root directory of the repository, I have placed a file .travis.yml with the following content.
language: go dist: xenial go: - 1.10.8 script: - go build - go test -v -count=1
This is file in YAML syntax, defining an associative array, i.e. key/value pairs. Here, we see four keys: language, dist, go and script. While the first three keys define settings (the language to use, the base image for the virtual machine that Travis will create and the Go version), the fourth key is a build phase and defines a list of commands which will be executed during the build phase. Each of these commands can be an ordinary command as you would place it in a shell script, in particular you can invoke any program or shell script you need.
To see this in action, we can now trigger a test build in Travis. There are several options to achieve this, I usually place a meaningless text file somewhere in the repository, change this file, commit and push to trigger a build. When you do this and wait for a few minutes, you will see a new build in your Travis dashboard. Clicking on this build takes you to the build log, which is displayed on a screen similar to the following screenshot.
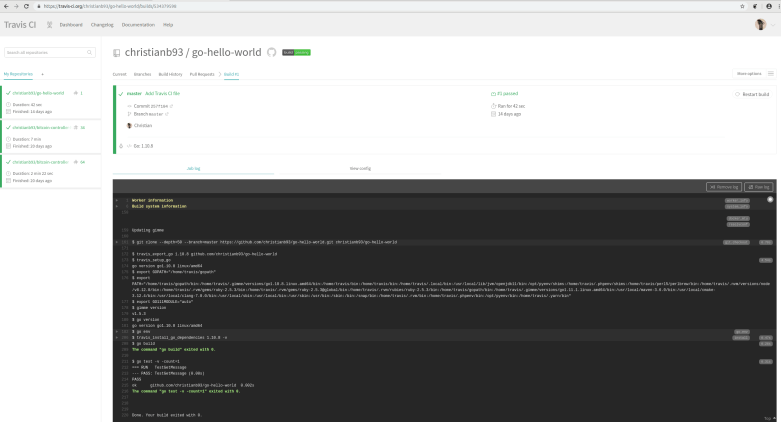
Working your way through this logfile, it becomes pretty transparent what Travis is doing. First, it will create a virtual machine for the build, using Ubuntu Xenial (16.04) as a base system (which I did select using the dist key in the Travis CI file). If you browse the system information, you will see some indications that behind the scenes, Travis is using Googles Cloud Platform GCP to provision the machine. Then, a Go language environment is set up, using Go 1.10.8 (again due to the corresponding setting in the Travis CI file), and the repository that triggered the build is cloned.
Once these steps have been completed, the Travis engine processes the job in several phases according to the Travis lifecycle model. Not all phases need to be present in the Travis CI file, if a phase is not specified, default actions are taken. In our case, the install phase is not defined in the file, so Travis executes a default script which depends on the programming language and in our case simply invokes go get.
The same holds for the build phase. Here, we have overwritten the default action for the build phase using the script tag in the Travis CI file. This tag is a YAML formatted list of commands which will be executed step by step during the build phase. Each of these commands can indicate failure by returning a non-zero exit code, but still, all commands will be executed even if one of the previous commands has failed – this is important to understand when designing your build phase. Alternatively, you could of course place your commands in a shell script and use for instance set -e to make sure that the script fails if one individual step fails.
A more complex job will usually have additional phases after the build phase, like a deploy phase. The commands in the deploy phase are only executed once your build phase completes successfully and are typically used to deploy a “green” build into the next stage.
Environment variables and secrets
During your build, you will typically need some additional information on the build context. Travis offers a couple of mechanisms to get access to that information.
First, there are of course environment variables that Travis will set for you. It is instructive to study the source code of the Travis build system to see where these variables are defined – like builtin.rb or several bash scripts like travis_export_go or travis_setup_env. Here is a list of the most important environment variables that are available.
- TRAVIS_TMPDIR is pointing to a temporary directory that your scripts can use
- TRAVIS_HOME is set to the home directory of the travis user which is used for running the build
- TRAVIS_TAG is set only if the current build is for a git tag, if this is the case, it will contain the tag name
- TRAVIS_COMMIT is the full git commit hash of the current build
- TRAVIS_BUILD_DIR is the absolute path name to the directory where the Git checkout has been done to and where the build is executed
In addition to these built-in variables, users have several options to declare environment variables on top. First, environment variables can be declared using the env tag in the Travis CI file. Note that Travis will trigger a build for each individual item in this list, with the environment variables set to the values specified in this line. Thus if you want to avoid additional builds, specify all environment variables in one line like this.
env: - FOO=foo BAR=bar
Now suppose that during your build, you want to push a Docker image into your public repository, or you want to publish an artifact on your GitHub page. You will then need access to the respective credentials. Storing these credentials as environment variables in the Travis CI file is a bad idea, as anybody with read access to your Github repository (i.e. the world) can read your credentials. To handle this use case, Travis offers a different option. You can specify environment variables on the repository level in the Travis CI web interface, which are then available to every build for this repository. These variables are stored in encrypted form and – assuming that you trust Travis – appear to be reasonably safe (when you use Travis, you have to grant them privileged access to your GitHub repository anyway, so if you do not trust them, you might want to think about a privately hosted CI solution).
Testing a build configuration locally
One of the nice things with Travis is that the source code of the build system is publicly available on GitHub, along with instructions on how to use it. This is very useful if you are composing a Travis CI file and run into errors which you might want to debug locally.
As recommended in the README of the repository, it is a good idea to do this in a container. I have turned the build instructions on this page into a Dockerfile that is available as a gist. Let us use this and the Travis CI file from my example repository to dive a little bit into the inner workings of Travis.
For that purpose, let us first create an empty directory, download the Docker file and build it.
$ mkdir ~/travis-test $ cd ~/travis-test $ wget https://gist.githubusercontent.com/christianb93/e14252a122d081a219b84a905a40543f/raw/1525fec3b26c7dc4eab71e7838c02f8637e40675/Dockerfile.travis-build $ docker build --tag travis-build --file Dockerfile.travis-build .
Next, clone my test repository and run the container, mounting the current directory as a bind mount on /travis-test
$ git clone --depth=1 https://github.com/christianb93/go-hello-world $ docker run -it -v $(pwd):/travis-test travis-build
You should now see a shell prompt within the container, with a working directory containing a clone of the travis build repository. Let us grab our Travis CI file and copy it to the working directory.
# cp /travis-test/go-hello-world/.travis.yml .
When Travis starts a build, it internally converts the Travis CI file into a shell script. Let us do this for our sample file and take quick look a the resulting shell script. Within the container, run
# bin/travis compile > /travis-test/script
The compile command will create the shell script and print it to standard output. Here, we redirect this back into the bind mount to have it on the host where you can inspect it using your favorite code editor. If you open this script, you will see that it is in fact a bash script that first defines some of the environment variables that we have discussed earlier. It then defines and executes a function called travis_preamble and then prints a very long string containing some function definitions into a file called job_stages which is then sourced, so that these functions are available. A similar process is then repeated several times, until finally, at the end of the script, a collection of these functions is executed.
Actually running this script inside the container will fail (the script expects some environment that is not present in our container, it will for instance probe a specific URL to connect to the Travis build system), but at least the script job_stages will be created and can be inspected. Towards the end of the script, there is one function for each of the phases of a Travis build job, and starting with these functions, we could now theoretically dive into the script and debug our work.
Caching with Travis CI
Travis runs each job in a new, dedicated virtual machine. This is very useful, at it gives you a completely reproducable and clean build environment, but also implies that it is difficult to cache results during builds. Go, for instance, maintains a build cache that significantly reduces build times and that is not present by default during a build on Travis. Dependencies are also not cached, meaning that they have to be downloaded over and over again with each new build.
To enable caching, a Travis CI file can contain a cache directive. In addition to a few language specific options, this allows you to specify a list of directories which are cached between builds. Behind the scenes, Travis uses a caching utility which will store the content of the specified directories in a cloud object store (judging from the code, this is either AWS S3 or Google’s GCS). At the end of a build, the cached directories are scanned and if the content has changed, a new archive is created and uploaded to the cloud storage. Conversely, when a job is started, the archive is downloaded and unzipped to create the cached directories. Thus we learn that
- The cached content still needs to be fetched via the network, so that caching for instance a Docker image is not necessarily faster than pulling the image from the Docker Hub
- Whenever something in the cached directories changes, the entire cache is rebuilt and uploaded to the cloud storage
These characteristics imply that caching just to avoid network traffic will usually not work – you should cache data to avoid repeated processing of the same data. In my experience, for instance, caching the Go build cache is really useful to speed up builds, but caching Docker images (by exporting them into an archive which is then placed in a cached directory) can actually be slower than downloading the images again for each build.
Using the API to inspect your build results
So far, we have operated Travis through the web interface. However, to support full automation, Travis does of course also offer an API.
To use the API, you will first have to navigate to your profile and retrieve an API token. For the remainder of this section, I will assume that you have done this and defined an environment variable travisToken that contains this token. The token needs to be present in the authorization header of each HTTPS request that goes to the API.
To test the API and the token, let us first get some data on our user using curl. So in a terminal window (in which you have exported the token) enter
$ curl -s\ -H "Travis-API-Version: 3"\ -H "Authorization: token $travisToken" \ https://api.travis-ci.org/user | jq
As a result, you should see a JSON formatted output that I do not reproduce here for privacy reasons. Among other fields, you should be able to see your user ID, both as a string and an integer, as well as your Github user ID, demonstrating that the token works and is associated with your credentials.
As a different and more realistic example, let us suppose that you wanted to retrieve the state of the latest build for the sample repository go-hello-world. You would then navigate from the repository, identified by its slug (i.e. the combination of Github user name and repository), to its builds, sort the builds by start date and use jq to retrieve the status of the first entry in the list.
$ curl -s\
-H "Travis-API-Version: 3"\
-H "Authorization: token $travisToken" \
"https://api.travis-ci.org/repo/christianb93%2Fgo-hello-world/builds?limit=5&sort_by=started_at:desc" \
| jq -r '.builds[0].state'
Note that we need to properly format the backslash which is part of the URL and need to include the entire URL in double quotes so that the shell does not interpret the ampersand & as an instruction to spawn curl in the background.
There is of course much more that you can do with the API – you can activate and deactivate repositories, trigger and cancel builds, retrieve environment variables, change repository settings and so forth. Instead of using the API directly with curl, you could also use the official Travis client which is written in Ruby, and it would probably not be very difficult to create a simple library accessing that API in any other programming language.
We have reached the end of this short introduction to Travis CI. In one of the next posts, I will show you how to actually put this into action. We will build a CI pipeline for my bitcoin controller which fully automates unit and integration tests using Helm and kind to spin up a local Kubernetes cluster. I hope you enjoyed this post and come back to read more soon.