
Having installed Neutron in my last post, we will now analyze flat networks and VLAN networks in detail and see how Neutron actually realizes virtual Ethernet networks. This will also provide the basic understanding that we need for more complex network types in future posts.
Setup
To follow this post, I recommend to repeat the setup from the previous post, so that we have two virtual machines running which are connected by a flat virtual network. Instead of going through the setup again manually, you can also use the Ansible scripts for Lab5 and combine them with the demo playbook from Lab6.
git clone https://github.com/christianb93/openstack-labs cd openstack-labs/Lab5 vagrant up ansible-playbook -i hosts.ini site.yaml ansible-playbook -i hosts.ini ../Lab6/demo.yaml
This will install a demo project and a demo user, import an SSH key pair, create a flavor and a flat network and bring up two instances connected to this network, one on each compute node.
Analyzing the virtual devices
Once all instances are running, let us SSH into the first compute node and list all network interfaces present on the node.
vagrant ssh compute1 ifconfig -a
The output is long and a bit daunting. Here is the output from my setup, where I have marked the most relevant sections in red.
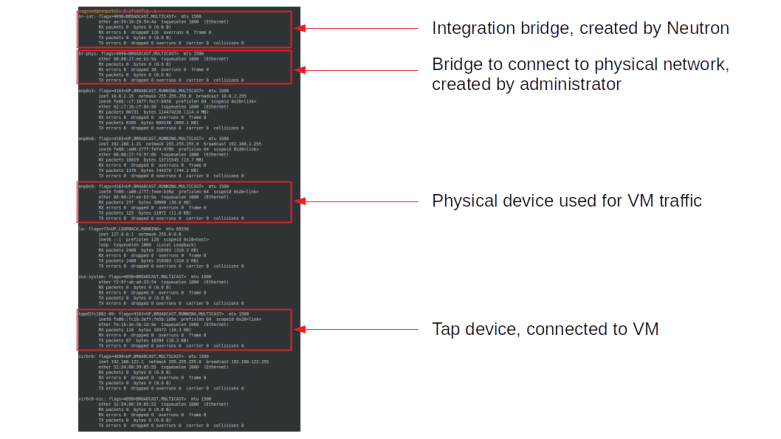
The first interface that we see at the top is the integration bridge br-int which is created automatically by Neutron (in fact, by the Neutron OVS agent). The second bridge is the bridge that we have created during the installation process and that is used to connect the integration bridge to the physical network infrastructure – in our case to the interface enp0s9 which we use for VM traffic. The name of the physical bridge is known to Neutron from our configuration file, more precisely from the mapping of logical network names (physnet in our case) to bridge devices.
The full output also contains two devices (virbr0 and virbr0-nic) that are created by the libvirt daemon but not used.
We also see a tap device, tapd5fc1881-09 in our case. This tap device is realizing the port of our demo instance. To see this, source the credentials of the demo user and run openstack port list to see all ports. You will see two ports, one corresponding to each instance. The second part of the name of the tap device matches the first part of the UUID of the corresponding port (and we can use ethtool -i to get the driver managing this interface and see that it is really a tap device).
The virtual machine is listening on the tap device and using it to provide the virtual NIC to its guest. To verify that QEMU is really listening on this tap device, you can use the following commands (run this and all following commands as root).
# Figure out the PID of QEMU
pid=$(ps --no-headers \
-C qemu-system-x86_64 \
| awk '{ print $1}')
# Search file descriptors in /proc/*/fdinfo
grep "tap" /proc/$pid/fdinfo/*
This should show you that one of the file descriptors is connected to the tap device. Let us now see how this tap device is attached to the integration bridge by running ovs-vsctl show. The output should look similar to the following sample output.
4629e2ce-b4d9-40b1-a362-5a1ba7f79e12
Manager "ptcp:6640:127.0.0.1"
is_connected: true
Bridge br-phys
Controller "tcp:127.0.0.1:6633"
is_connected: true
fail_mode: secure
Port phy-br-phys
Interface phy-br-phys
type: patch
options: {peer=int-br-phys}
Port "enp0s9"
Interface "enp0s9"
Port br-phys
Interface br-phys
type: internal
Bridge br-int
Controller "tcp:127.0.0.1:6633"
is_connected: true
fail_mode: secure
Port "tapd5fc1881-09"
tag: 1
Interface "tapd5fc1881-09"
Port int-br-phys
Interface int-br-phys
type: patch
options: {peer=phy-br-phys}
Port br-int
Interface br-int
type: internal
ovs_version: "2.11.0"
Here we see that both OVS bridges are connected to a controller listening on port 6633, which is actually the Neutron OVS agent (the manager in the second line is the OVSDB server). The integration bridge has three ports. First, there is a port connected to the tap device, which is an access port with VLAN tag 1. This tagging is used to separate traffic on the integration bridge belonging to two different virtual networks. The VLAN ID here is called the local VLAN ID and is only valid per node. Then, there is a patch port connecting the integration bridge to the physical bridge, and there is the usual internal port.
The physical bridge has also three ports – the other side of the patch port connecting it to the integration bridge, the internal port and finally the physical network interface enp0s9. Thus the following picture emerges.
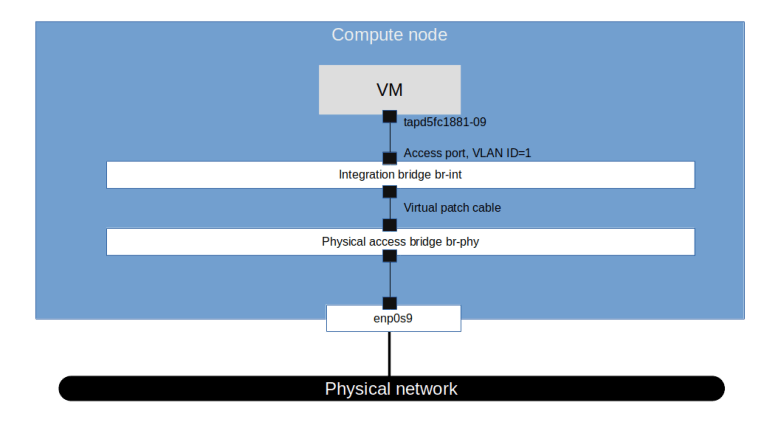
So we get a first idea of how traffic flows. When the guest sends a packet to the virtual interface in the VM, it shows up on the tap device and goes to the integration bridge. It is then forwarded to the physical bridge and from there to the physical interface. The packet travels across the physical network connecting the two compute nodes and there again hits the physical bridge, travels along the virtual patch cable to the integration bridge and finally arrives at the tap interface.
At this point, it is important that the physical network interface enp0s9 is in promiscuous mode. In fact, it needs to pick up traffic directed to the MAC address of the virtual instance, not to its own MAC address. Effectively this interface itself is not visible and only part of a virtual Ethernet cable connecting the two physical bridges.
OpenFlow rules on the bridges
We now have a rough understanding of the flow, but there is still a bit of a twist – the VLAN tagging. Recall that the port to which the tap interface is connected is an access port, so traffic arriving there will receive a VLAN tag. If you run tcpdump on the physical interface, however, you will see that the traffic is untagged. So at some point, the VLAN tag is stripped of.
To figure out where this happens, we need to inspect the OpenFlow rules on the bridges. To simplify this process, we will first remove the security groups (i.e. disable firewall rules) and turn off port security for the attached port to get rid off the rules realizing this. For simplicity, we do this for all ports (needless to say that this is not a good idea in a production environment).
source /home/vagrant/admin-openrc
ports=$(openstack port list \
| grep "ACTIVE" \
| awk '{print $2}')
for port in $ports; do
openstack port set --no-security-group $port
openstack port set --disable-port-security $port
done
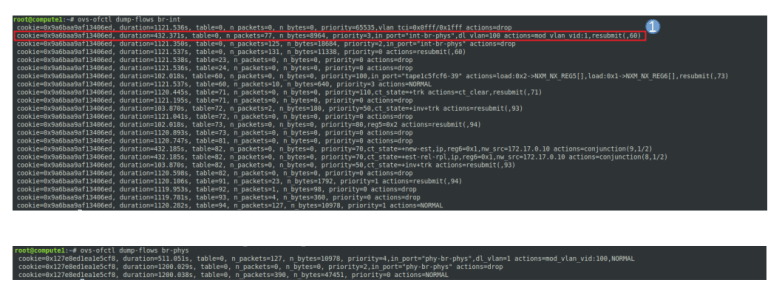
Now let us dump the flows on the integration bridge using ovs-ofctl dump-flows br-int. In the following image, I have marked those rules that are relevant for traffic coming from the instance.
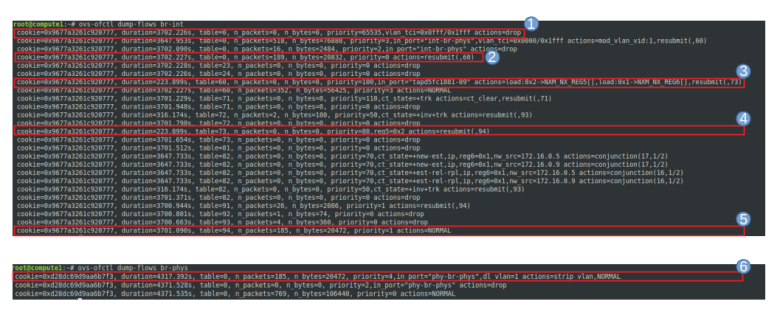
The first rule drops all traffic for which the VLAN TCI, masked with 0x1fff (i.e. the last 13 bits) is equal to 0x0fff, i.e. for which the VLAN ID is the reserved value 0xfff. These packets are assumed to be irregular and are dropped. The second rule directs all traffic coming from the tap device, i.e. from the virtual machine, to table 60.
In table 60, the traffic coming from the tap device, i.e. egress traffic, is marked by loading the registers 5 and 6, and resubmitted to table 73, where it is again resubmitted to table 94. In table 94, the packet is handed over to the ordinary switch processing using the NORMAL target.
When we dump the rules on the physical bridge br-phys, the result is much shorter and displayed in the lower part of the image above. Here, the first rule will pick up the traffic, strip off the VLAN tag (as expected) and hand it over to normal processing, so that the untagged package is forwarded to the physical network.
Let us now turn to the analysis of ingress traffic. If a packet arrives at br-phys, it is simply forwarded to br-int. Here, it is picked up by the second rule (unless it has a reserved VLAN ID) which adds a VLAN tag with ID 1 and resubmits to table 60. In this table, NORMAL processing is applied and the packet is forwarded to all ports. As the port connected to the tap device is an access port for VLAN 1, the packet is accepted by this port, the VLAN tag is stripped off again and the packet appears in the tap device and therefore in the virtual interface in the instance.
All this is a bit confusing but becomes clearer when we study the meaning of the various tables in the Neutron source code. The relevant source files are br_int.py and br_phys.py. Here is an extract of the relevant tables for the integration bridge from the code.
| Table | Name |
|---|---|
| 0 | Local switching table |
| 23 | Canary table |
| 24 | ARP spoofing table |
| 25 | MAC spoofing table |
| 60 | Transient table |
| 71,72 | Firewall for egress traffic |
| 73,81,82 | Firewall for accepted and ingress traffic |
| 91 | Accepted egress traffic |
| 92 | Accepted ingress traffic |
| 93 | Dropped traffic |
| 94 | Normal processing |
Let us go through the meaning of some of these tables. The canary table (23) is simply used to verify that OVS is up and running (whence the name). The MAC spoofing and ARP spoofing tables (24, 25) are not populated in our example as we have disabled the port protection feature. Similarly, the firewall tables (71 , 72, 73, 81, 82) only contain a minimal setup. Table 91 (accepted egress traffic) simply routes to table 94 (normal processing), tables 92 and 93 are not used and table 94 simply hands over the packets to normal processing.
In our setup, the local switching table (table 0) and the transient table (table 60) are actually the most relevant tables. Together, these two tables realize the local VLANs on the compute node. We will see later that on each node, a local VLAN is built for each global virtual network. The method provision_local_vlan installs a rule into the local switching table for each local VLAN which adds the corresponding VLAN ID to ingress traffic coming from the corresponding global virtual and then resubmits to the transient table.
Here is the corresponding table for the physical bridge.
| Table | Name |
|---|---|
| 0 | Local switching table |
| 2 | Local VLAN translation |
In our setup, only the local switching table is used which simply strips off the local VLAN tags for egress traffic.
You might ask yourself how we can reach the instances from the compute node. The answer is that a ping (or an SSH connection) to the instance running on the compute node actually travels via the default gateway, as there is no direct route to 172.16.0.0 on the compute node. In our setup, the gateway is 10.0.2.2 on the enp0s3 device which is the NAT-network provided by Virtualbox. From there, the connection travels via the lab host where we have configured the virtual network device vboxnet1 as a gateway for 172.16.0.0, so that the traffic enters the virtual network again via this gateway and eventually reaches enp0s9 from there.
We could now turn on port protection and security groups again and study the resulting rules, but this would go far beyond the scope of this post (and far beyond my understanding of OpenFlow rules). If you want to get into this, I recommend this summary of the firewall rules. Instead, we move on to a more complex setup using VLANs to separate virtual networks.
Adding a VLAN network
Let us now adjust our configuration so that we are able to provision a VLAN based virtual network. To do this, there are two configuration items that we have to change and that both appear in the configuration of the ML2 plugin.
The first item is type_drivers. Here, we need to add vlan as an additional value so that the VLAN type driver is loaded.
When starting up, this plugin loads the second parameter that we need to change – network_vlan_ranges. Here, we need to specify a list of physical network labels that can be used for VLAN based networks. In our case, we set this to physnet to use our only physical network that is connected via the br-phys bridge.
You can of course make these changes yourself (do not forget to restart the Neutron server) or you can use the Ansible scripts of lab 7. The demo script that is part of this lab will also create a virtual network based on VLAN ID 100 and attach two instances to it.
git clone https://github.com/christianb93/openstack-labs cd openstack-labs/Lab7 vagrant up ansible-playbook -i hosts.ini site.yaml ansible-playbook -i hosts.ini demo.yaml
Once the instances are up, log again into the compute node and, as above, turn off port security for all ports. We can now go through the exercise above again and see what has changed.
First, ifconfig -a shows that the basic setup is the same as before. We have still our integration bridge connected to the tap device and connected to the physical bridge. Again, the port to which the tap device is attached is an access port, tagged with the VLAN ID 1. This is the local VLAN corresponding to our virtual network.
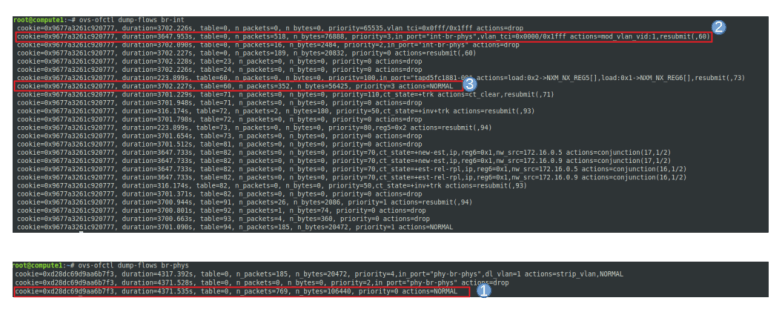
When we analyze the OpenFlow rules in the two bridges, however, a difference to our flat network is visible. Let us start again with egress traffic.
In the integration bridge, the flow is the same as before. As the port to which the VM is attached is an access port, traffic originating from the VM is tagged with VLAN ID 1, processed by the various tables and eventually forwarded via the virtual patch cable to br-phys.
Here, however, the handling is different. The first rule for this bridge matches, and the VLAN ID 1 is rewritten to become VLAN ID 100. Then, normal processing takes over, and the packet leaves the bridge and travels via enp0s9 to the physical network. Thus, traffic which the VLAN ID on the integration bridge shows up with VLAN ID 100 on the physical network. This is the mapping between local VLAN ID (which represents a virtual network on the node) and global VLAN ID (which represents a virtual VLAN network on the physical network infrastructure connecting the nodes).
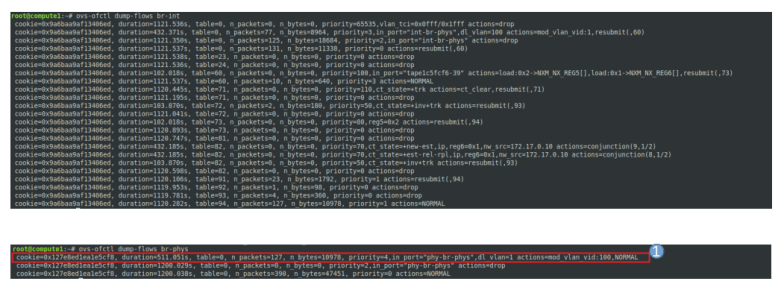
For ingress traffic, the reverse mapping applies. A packet travels from the physical bridge to the integration bridge. Here, the second rule for table 0 matches for packets that are tagged with VLAN 100, the global VLAN ID of our virtual network, and rewrites the VLAN ID to 1, the local VLAN ID. This packet is then processed as before and eventually reaches the access port connecting the bridge with the tap device. There, the VLAN tagging is stripped off and the untagged traffic reaches the VM.
The diagram below summarizes our findings. We see that on the same physical infrastructure, two virtual networks are realized. There is still the flat network corresponding to untagged traffic, and the newly created virtual network corresponding to VLAN ID 100.

It is interesting to note how the OpenFlow rules change if we bring up an additional instance on this compute node which is attached to the flat network. Then, an additional local VLAN ID (2 in our case) will appear corresponding to the flat network. On the physical bridge, the VLAN tag will be stripped off for egress traffic with this local VLAN ID, so that it appears untagged on the physical network. Similarly, on the integration bridge, untagged ingress traffic will no longer be dropped but will receive VLAN ID 2.
Note that this setup implies that we can no longer easily reach the machines connected to a VLAN network via SSH from the lab host or the compute node itself. In fact, even if we would set up a route to the vboxnet1 interface on the lab host, our traffic would come in untagged and would not reach the virtual machine. This is the reason why our lab 7 comes with a fully installed Horizon GUI which allows you to use the noVNC console to log into our instances.
This is very similar to a physical setup where a machine is connected to a switch via an access port, but the connection to the external network is on a different VLAN or on the untagged, native VLAN. In this situation, one would typically use a router to connect the two networks. Of course, Neutron offers virtual routers to connect two virtual networks. In the next post, we will see how this works and re-establish SSH connectivity to our instances.

2 Comments