In the previous posts, we have already used the Python client to implement Kafka consumers. Today, we will take a closer look at the components that make up a consumer and discuss their inner workings and how they communicate with the Kafka cluster.
High level overview of the consumer
Our discussion will be based on the Kafka Python library, which seems to be loosely modeled after the Java consumer which is part of the official Apache Kafka project, so that the underlying principles are the same. These notes are based on version 2.0.1 of the library, the design might of course change in future versions (and has already changed substantially in the past).
Looking at the code, we see that roughly speaking, the consumer consists of three parts – the actual consumer in the package kafka.consumer, the coordinator which is responsible for talking to the group coordinator and assign partitions in the package kafka.coordinator and the network client in the top-level package which is used by other parts of the library as well. Broken down to the level of modules and classes, the following diagram shows the most important components of the consumer and their relations.

Let us start our discussion with the class on the left hand side of the diagram, the subscription state. This class is used to manage the topics and partitions a consumer has subscribed to as well as the positions of the consumer within these partitions. Note that these positions are not the committed offsets, but are the positions maintained locally (and in-memory) by the consumer that are used to determine the offset that the next fetch will use. Initially, there is no valid position for a newly assigned partition, and the partition is considered fetchable only once a position has been determined.
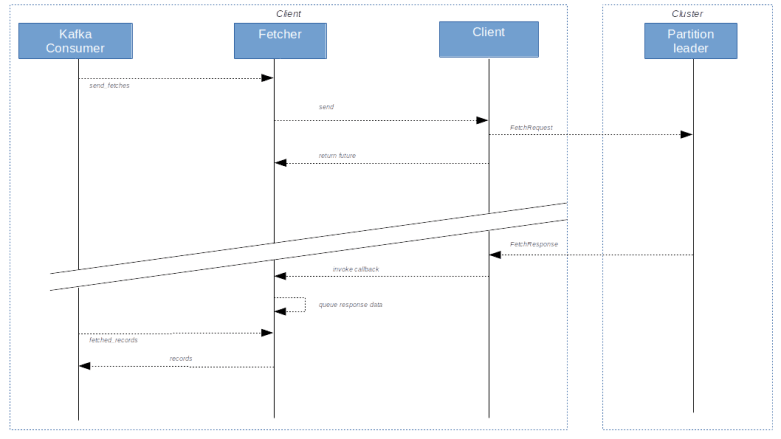
The second class which is used by the consumer is the fetcher. As the name suggests, this class is in charge for actually fetching data and offsets from the leader of a partition (here, offsets does not refer to committed offsets, but to the valid offsets, i.e. the first and last offset of a partition).
Fetching records from the partition leader typically works asynchronously. As an example, let us consider the method send_fetches. As indicated above, a partition is called fetchable if there is a valid position for it, the partition has not been paused and there are no unfetched records already present in the cache. After creating a list of all fetchable partitions, the send_fetches method then figures out the partition leader and assembles a fetch request. These requests are then sent to the respective partition leader using the client object. This operation returns a future, i.e. a handle which can be used to asynchronously track the progress of the fetch operation. Attached to this future, there is a callback operation. When the records are sent from the partition leader to the consumer, the client object will invoke this callback which will then add the returned records to a queue maintained by the fetcher. From there, it is retrieved when a consumer calls the method fetched_records.
It is in this function where the positions are actually updated, so that the position really reflects the records that have been consumed, not those which have been received by the fetcher but are still in the queue. Note that records are skipped if a partition has become unfetchable in the meantime or if the offset does not match the expected value in the original request.
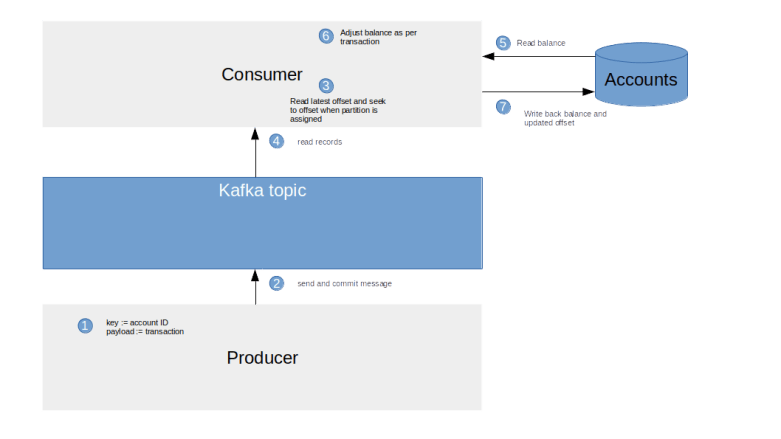
The following diagram shows a simplified view of how records are fetched (some important details are skipped, for instance the deserialization that takes place when fetched records are removed from the queue and handed over to the consumer).
Coordinating group membership and partition assignments
Apart from fetching records, a core responsibility of the consumer is to manage the membership in a consumer group and to handle assigned partitions. This is done by the coordinator. The coordinator communicates with the group coordinator (which is one dedicated broker per consumer group) to trigger the addition and removal of group members and to balance partitions between group members. In addition, the coordinator is responsible for managing committed offsets.
Looking at the source code of the coordinator, we can see how the process of adding members to the group and assigning partitions works. This process, commonly referred to as rebalancing, typically starts when a consumer invokes the poll method of the coordinator. When this happens, the coordinator will first check whether it needs to join (or rejoin) the group, for instance because the consumer was just started. If yes, the processing in ensure_active_group will first prepare the join process, for instance by committing all offsets if auto-commit is enabled and calling the revoke method of all registered rebalance listeners (conceptually, when a rebalancing starts, all existing members will loose ownership of previously handled partitions and consequently stop processing records so that the group coordinator can reassign partitions freely – there is an ongoing effort known as cooperative rebalancing with the objective to change this).
We then wait until there are no more in-flight requests to the coordinator, and then send a JoinGroupRequest to the group coordinator. The group coordinator (broker) will wait until all members have handed in their requests (see below for more on the timeline) and then determine one member to be the group leader. As part of the JoinGroupResponse, every consumer will be informed about the newly elected leader. The group leader will then perform the actual assignment of partitions to group members (using a configurable assignor). Then, all group members send another request to the group coordinator, called the SyncGroupRequest. In this request, the group leader will inform the group coordinator about the defined partition assignments, and in the response to this message, the partition assignments will be distributed to all group members.
Once the SyncGroupResponse has been received, the method ensure_active_group will invoke _on_join_complete which will in turn trigger a call of the on_partitions_assigned method of all registered rebalance listeners. Note that at this point, all exceptions raised by the listener are swallowed, so exceptions should be caught and handled inside the listener.
This is all nice if our own consumer joins a group, but what happens if another consumer joins? This is where the heartbeat thread comes into play. This is a thread which is running in the background and periodically sending heartbeat messages to the group coordinator (with a frequency determined by the parameter heartbeat_interval_ms). If a rebalancing has been initiated by another member joining or leaving, the heartbeat response will have an error flag set, so that the consumer learns about the start of the rebalancing process. It then sets a flag, which will be evaluated during the next call of the coordinators poll method, which is in turn invoked from the consumers poll loop. If this flag is set, the coordinator will rejoin the group following the process outlined above.
At this point, timing is vital. If a consumer does not call the poll method for a long period of time, it might miss a rebalancing and will forcefully be removed from the group. This again will lead to errors when the consumer tries to commit offsets, which are difficult to handle and almost inevitably lead to duplicate processing. In general, a consumer should invoke the poll method on a regular basis, and there is again a parameter (max_poll_interval_ms) which determines the maximum allowed time between two subsequent invocations of this method.
Indirectly, this parameter also determines how long the group coordinator will wait for members to join the group (it is sent to the group coordinator as part of the join group request). The following diagram shows the typical sequence of events when a new member joins a group and triggers a rebalancing.

The consumers poll loop
After all these preparations, we are now ready to discuss the poll method of the Kafka consumer. In this method (or rather the private method _poll_once), we first use the coordinator and its poll method discussed above to verify that the consumer is part of a group and has partitions assigned and to trigger a rebalancing process if needed. Note that if a rebalancing is needed, this call will block so that it is made sure that we only reach the main part of the consumers poll method after the rebalancing is done.
Next, we will typically have to update all fetch positions. This happens in several steps.
- call the method reset_offsets_if_needed of the fetcher. This method will check a flag to see if any offsets need to be reset. If yes, it will retrieve the valid offsets and apply the chosen offset reset strategy
- if there are still partitions which do not have a valid position, we call the method refresh_committed_offsets_if_needed of the coordinator which will fetch the committed offsets from the group coordinator
- Then, the method update_fetch_positions of the fetcher is invoked which will set the fetch positions of the partitions in question to the committed value
Back in _poll_once, we then check whether the fetcher has any previously obtained records still in its queue. If yes, we immediately return this data (and at the same time initiate a pre-fetch of the next records). Recall that the process of getting these queued records also triggers the update of the position. Then, new fetches are sent, and we poll the client until we either time out or obtain new records which we then return.
Summarizing, the diagram below displays the (slightly simplified) flow of events in case a consumer calls poll (where some calls indicated in the diagram are not made every time, depending on available fetch positions and committed offsets).

From what we have said above, it is now clear that a rebalancing listener is always invoked from within the poll method – which also implies that you should not spend too much time in a rebalance listener and not make any blocking calls.
This completes our short summary of the processing inside the Kafka consumer. With this introduction and using the Java library and the rich comments inside the code, you should now be able to dig deeper into the bits and pieces if needed.