The storage types that we have discussed so far realize ephemeral storage, i.e. storage tied to the lifecycle of the Pod on a specific node. Of course, there are many use cases like databases or other stateful applications that require storage that is persistent and has a lifecycle independent of the Pod. In this post, we look at different ways to realize this in Kubernetes.
Using cloud provider specific storage directly
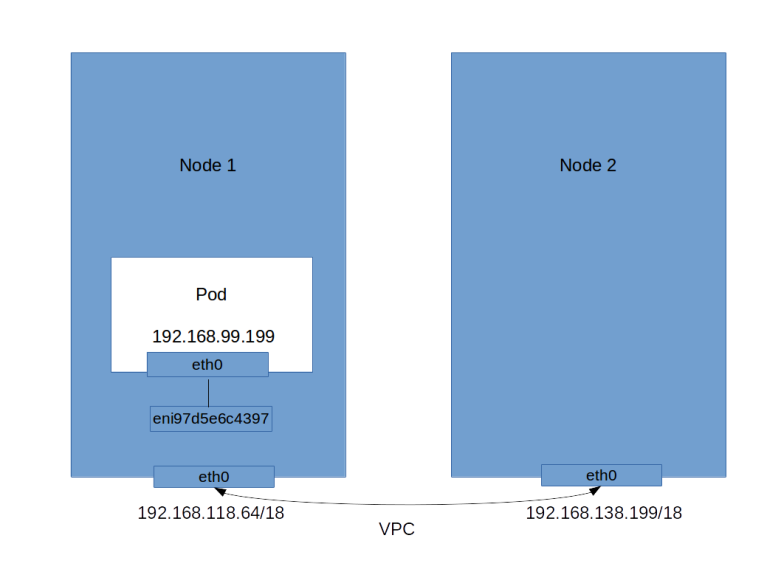
The easiest – and historically first – way to do this is to directly refer to an existing piece of persistent storage provided by the underlying cloud platform. Recall that when you define and use volumes, you define the volume as part of Pod specification, assign a name and tell Kubernetes which type of volume it should allocate – like emptyDir or hostPath. If you check the list of supported volumes, you will find some volumes that are specific to a cloud provider, for instance awsElasticBlockStore. This allows you to mount a pre-existing AWS Elastic Block Store volume into your Pod. As EBS volumes can only be attached to one instance at a time, you can only connect to this volume from one Pod.
To try this out, we of course have to generate an EBS volume first (as always, be aware of the charges and make sure to delete the volume if it is no longer needed). EBS volumes need to be created within an availability zone (which you can figure out using aws ec2 describe-availability-zones). In my example, I will use the availability zone eu-central-1a. The following command creates a 16 GiB GP2 (SSD) drive in this availability zone.
$ aws ec2 create-volume --availability-zone=eu-central-1a\
--size=16 --volume-type=gp2
If you now run aws ec2 describe-volumes --output json to list all volumes, you will see several volumes that have the status “in-use” (these are the root volumes of your nodes) and one new volume that has the status “available”. We will need the volume ID of this volume, in my case this is vol-0eb2505d4b7d035cb. Let us try to attach this to a Pod using the following manifest file.
apiVersion: v1
kind: Pod
metadata:
name: ebs-demo
namespace: default
spec:
containers:
- name: ebs-demo-ctr
image: httpd:alpine
volumeMounts:
- mountPath: /test
name: test-volume
volumes:
- name: test-volume
awsElasticBlockStore:
volumeID: vol-0eb2505d4b7d035cb
Sometimes you learn most from your mistakes. If you apply this manifest file chances are that your Pod will never be fully established, but will remain in the state “ContainerCreating” forever. What is going wrong?
To find the answer, use the AWS CLI or the AWS Web console to look at the availability zones of the instance on which the Pod is scheduled and the volume. In my example, Kubernetes did schedule the Pod on a node running in eu-central-1c, whereas the volume was created in eu-central-1a. Unfortunately, EBS volumes cannot be attached across availability zones, and the creation of the Pod fails.
Fortunately, there is a way out. Note that EKS will attach a label to the nodes which capture there availability zone. This label is called failure-domain.beta.kubernetes.io/zone. Now, Kubernetes has a general mechanism called node selector. This allows you to instruct the Kubernetes scheduler to move Pods only on specific nodes, matching certain selection criteria. These criteria are provided in the section nodeSelector of the Pod specification. So the following updated manifest file makes sure that the node will be scheduled in the availability zone in which we did create the volume.
apiVersion: v1
kind: Pod
metadata:
name: ebs-demo
namespace: default
spec:
containers:
- name: ebs-demo-ctr
image: httpd:alpine
volumeMounts:
- mountPath: /test
name: test-volume
volumes:
- name: test-volume
awsElasticBlockStore:
volumeID: vol-0eb2505d4b7d035cb
nodeSelector:
failure-domain.beta.kubernetes.io/zone: eu-central-1a
If you apply this manifest file and wait for some time, you will see that the Pod comes up. If you again run aws ec2 describe-volumes, you will find that the volumes status has changed to “in-use” and that EKS has automatically attached it to the node on which the Pod is scheduled (provided, of course, that you have a node running in eu-central-1a, which is not a given if you only use two nodes as we do it – in this case you will have to create the volume in one of the availability zones in which you have a node). You can also attach to the Pod and run mount to verify that a device has been mounted on /test. Combining the output of docker inspect and mount on the node will tell you that the following has happened.
- Kubernetes has asked AWS to attach our volume as /dev/xvdba to the node
- Then Kubernetes did create a directory specific to the Pod
- The volume was mounted into this directory
- Finally, Kubernetes did create a Docker bind mount to hook up this directory on the node with the directory /test in the container file system
This example nicely demonstrates that using existing persistent storage in the underlying cloud platform is possible, but comes with some drawbacks. An administrator will have to manage these volumes manually, using whatever tools your cloud provider makes available. There are limitations if your cluster is spanning multiple availability zones, and of course you tie all your manifest files directly to a specific cloud provider. In addition, Kubernetes tries to follow the idea of “run everywhere”, which does not combine well with an approach where each individual cloud provider needs to be hardcoded into the core Kubernetes code base. As so often in computer science, this situation almost cries for an additional abstraction layer between Pod volumes and the underlying storage. This abstraction layer exists and is the topic of the next section.
Persistent volume claims
In the previous section, we have defined volumes as part of a Pod specification. These volumes – which we should actually call Pod volumes – are linked to the lifecycle of an individual Pod. We have seen that these volumes can refer to existing storage within your cloud layer, but that this comes with some drawbacks and requires manual provisioning outside of the Kubernetes world.
To change this, Kubernetes defines an additional abstraction layer between the storage as provided by the cloud platform and the Pod volumes. The most important objects we need to discuss in order to understand this are persistent volumes (PV) and persistent volume claims (PVC).
Let us start with persistent volumes. Essentially, a persistent volume is a Kubernetes object that represents a piece of storage in the underlying cloud platform. Typically, volumes are created dynamically, but we will see in the next post in this series that they can also be managed manually. The important thing is that volumes are first-class Kubernetes citizens and have a lifecycle independent of that of Pods.
Volumes represent the supply side of storage on your cluster. The demand side is represented by volume claims. A persistent volume claim is an object that a user creates to let Kubernetes know that a certain amount of storage is required. If the cluster is set up for it, Kubernetes will then automatically try to fulfill the claim, i.e. to either find an existing, unused volume that matches the claim or to provision a volume dynamically, using a so-called provisioner. A persistent volume claim can then be referenced in a Pod volume which in turn can be mounted into a container.
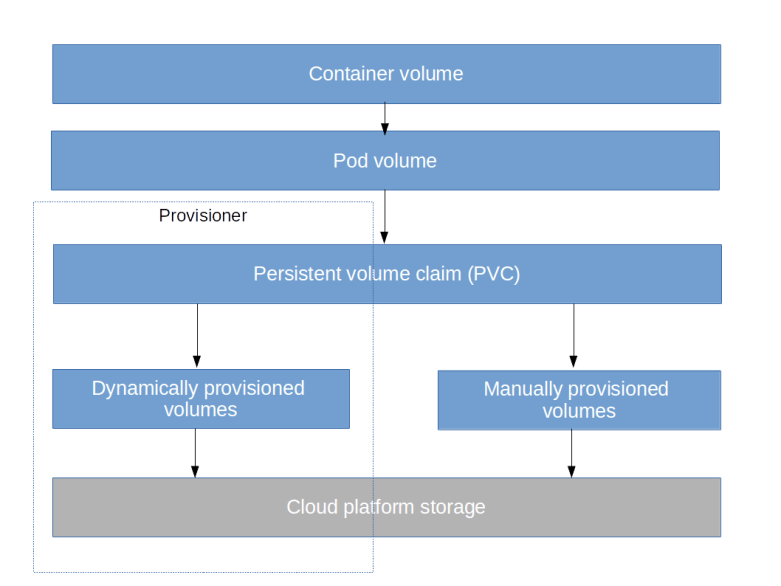
To get an idea what this means, let us again consider an example. The following manifest file describes a persistent volume claim.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ebs-pvc
namespace: default
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 4Gi
In addition to the standard fields, we have a specification that consists of two sections. The first section specifies the access mode. Here we use ReadWriteOnce, which states that we want a volume which can be accessed by one Pod at a time, reading and writing. In the second section, we specify the resources, i.e. the amount of storage that we need, in our case 4 Gigabytes of storage. This example already demonstrates one nice feature of a PVC – it does not refer at all to a specific type of volume or a specific cloud platform (it does so indirectly, via the mechanism of storage classes, which we will investigate in the next post).
When we apply this manifest file and wait for a few seconds, we can look at the objects that have been created. First, run kubectl get pvc to get a list of all persistent volume claims.
$ kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE ebs-pvc Bound pvc-63521bd7-4e51-11e9-8e51-0af6f9d0ca50 4Gi RWO gp2 7m
So as expected, we have a new persistent volume claim that has been generated. The status of this PVC is “bound”, telling us that the provisioner working behind the scenes was able to find a matching volume. We also find a reference to the volume in the output. So let us list this volume.
$ kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-63521bd7-4e51-11e9-8e51-0af6f9d0ca50 4Gi RWO Delete Bound default/ebs-pvc gp2
As stated above, this volume exists as an independent entity that we can refer to by its name and that has some properties. When we append --output json to get all the details, we see a few interesting things.
First, the volume has a field claimRef which tells us to which claim this volume is bound. This is only one field, not an array. Similarly, the PVC has a field volumeName referring to the underlying volume, which is again not an array. So the relation between a PV and a PVC is one-to-one. As mentioned in the documentation, this can lead to overprovisioning. If, for instance, you request 4 Gi, and there is a free volume with 8 Gi, the provisioner might decide to bind the PVC to this volume, even though only 4 Gi were requested.
Another interesting information that we get from the JSON output is that a volume has a label that tells us in which availability zone the volume (or, more precisely, the underlying EBS volume) is located. And, finally, the spec section contains a field that lets us locate the underlying EBS storage. You can use the following statements to extract this information and use the AWS CLI to print out some details of this volume.
$ fullVolumeID=$(kubectl get pv\
--output=jsonpath='{.items[0].spec.awsElasticBlockStore.volumeID}')
$ volumeID=$(echo $fullVolumeID | sed 's/aws:\/\/.*\///')
$ aws ec2 describe-volumes --volume-id=$volumeID --output json
Let us now actually use this volume, i.e. attach it to a Pod. Here is a manifest file which will bring up a Pod mounting this volume.
apiVersion: v1
kind: Pod
metadata:
name: pv-demo
namespace: default
spec:
containers:
- name: pv-demo-ctr
image: httpd:alpine
volumeMounts:
- mountPath: /test
name: test-volume
volumes:
- name: test-volume
persistentVolumeClaim:
claimName: ebs-pvc
We see that at the point in the file were we did previously refer directly to an EBS volume, we now refer to the PVC. So again, there is no EBS or EKS specific data in this manifest file, and we can theoretically use the same manifest file on any cloud platform.
When you apply this manifest file, you will notice that it takes significantly longer for the containers to come up, this is because behind the scenes, Kubernetes needs to attach the EBS volume to the node on which the Pod is scheduled, which takes some time.
We can now again analyze the structure of the file systems in the container and on the node. If we do this, we will find a very similar picture as above. The container has a bind mount into a directory managed by Kubernetes. This directory in turn is a mount point for the device /dev/xvdbu. If we look at the output of aws ec2 describe-volumes, we find that this is the device to which AWS has attached the EBS volume behind the PVC. So the outcome of the entire exercise is the same as before, with the difference that no manual provisioning of the volume as necessary.
In addition, Kubernetes is smart enough to place our Pod in a the same availability zone in which the volume is located. In fact, as explained in the documentation on multi-zone capabilities, the Kubernetes scheduler will make sure that a Pod that requires a PV located in a given availability zone will only be placed on a node running in that zone. It can, however, happen that a volume is created in an availability zone where there is no node at all, rendering it unusable (see this GitHub issue for a discussion).
Let us now investigat the lifecycle of this storage. To do this, let us create a file in our newly mounted directory, kill the pod, bring it up again and list the contents of the volume (this assumes that you have saved the manifest file for the Pod in a file called pvUsage.yaml).
$ kubectl exec -it pv-demo touch /test/hello $ kubectl delete pod pv-demo pod "pv-demo" deleted $ kubectl apply -f pvUsage.yaml pod/pv-demo created $ # Wait for container to be ready $ kubectl exec -it pv-demo ls /test hello lost+found
So, as expected, the volume and its content have survived the restart of the Pod. If a persistent volume claim is deleted, however, Kubernetes will automatically delete the underlying volume and delete the corresponding storage in the cloud platform layer. When you shutdown a cluster, make sure to delete all PVCs first, otherwise orphaned block storage volumes not controlled by Kubernetes any more could result.
We have now covered the basics of persistent storage in Kubernetes – but of course there is much more that we have still left open. How is storage actually provisioned? How does the platform know which type of storage we need when we issue a PVC? And how can we manually create storage? These are the topics that we will discuss in the next post in this series.




 is a state localized around the left minimum of the potential and
is a state localized around the left minimum of the potential and 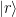 is a state centered around the right minimum, whereas the first excited state is a linear combination proportional to
is a state centered around the right minimum, whereas the first excited state is a linear combination proportional to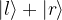
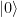 in an interpretation as a qubit – and our first excited state
in an interpretation as a qubit – and our first excited state 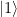 are superpositions of these two states.
are superpositions of these two states.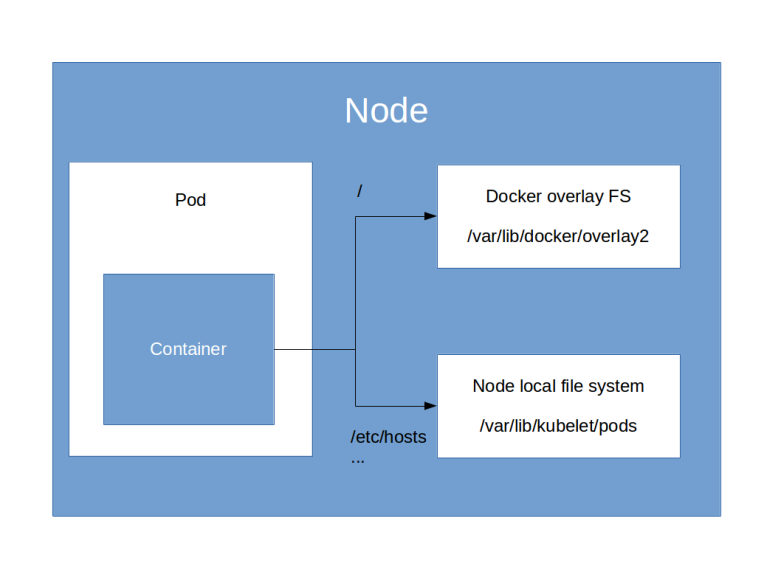






 .
.
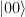









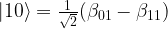

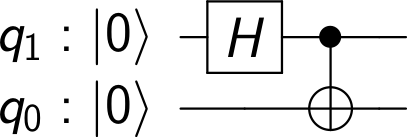
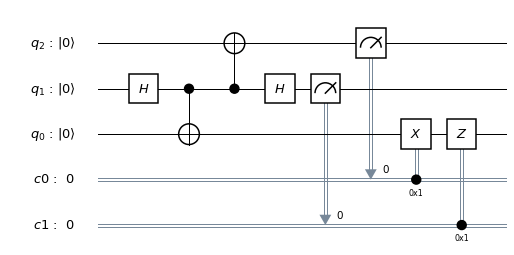
 , stored in some sort of quantum device, which could be a superconducting qubit, a trapped ion, a polarized photon or any other physical implementation of a qubit. Bob is operating a similar device. The task is to create a quantum state in Bob’s device which is identical to the state stored in Alice device.
, stored in some sort of quantum device, which could be a superconducting qubit, a trapped ion, a polarized photon or any other physical implementation of a qubit. Bob is operating a similar device. The task is to create a quantum state in Bob’s device which is identical to the state stored in Alice device. . In fact, this common state does not depend at all on
. In fact, this common state does not depend at all on  (we use the lower index to denote the qubit in which the state lives). We also assume that Alice is able to perform arbitrary measurements and operations on A and C, and that B similarly controls qubit B.
(we use the lower index to denote the qubit in which the state lives). We also assume that Alice is able to perform arbitrary measurements and operations on A and C, and that B similarly controls qubit B.![|\beta_{00}^{AB} \rangle = \frac{1}{\sqrt{2}} \big[ |0\rangle _A |0 \rangle _B+ |1\rangle_A |1 \rangle_B) \big]](https://s0.wp.com/latex.php?latex=%7C%5Cbeta_%7B00%7D%5E%7BAB%7D+%5Crangle+%3D+%5Cfrac%7B1%7D%7B%5Csqrt%7B2%7D%7D+%5Cbig%5B+%7C0%5Crangle+_A+%7C0+%5Crangle+_B%2B+%7C1%5Crangle_A+%7C1+%5Crangle_B%29+%5Cbig%5D++&bg=FFFFFF&fg=000&s=1&c=20201002)
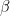 indicates the two qubits in which the Bell state vector lives. This is the common state mentioned above, and it can obviously be prepared upfront, without having the state
indicates the two qubits in which the Bell state vector lives. This is the common state mentioned above, and it can obviously be prepared upfront, without having the state ![|\beta_{00}^{AB} \rangle |\psi\rangle_C = \frac{1}{\sqrt{2}} \big[ a |000 \rangle + a |110 \rangle + b |001\rangle + b |111 \rangle \big]](https://s0.wp.com/latex.php?latex=%7C%5Cbeta_%7B00%7D%5E%7BAB%7D+%5Crangle+%7C%5Cpsi%5Crangle_C+%3D+%5Cfrac%7B1%7D%7B%5Csqrt%7B2%7D%7D+%5Cbig%5B+a+%7C000+%5Crangle+%2B+a+%7C110+%5Crangle+%2B+b+%7C001%5Crangle+%2B+b+%7C111+%5Crangle+%5Cbig%5D++&bg=FFFFFF&fg=000&s=1&c=20201002)
![\frac{1}{\sqrt{2}} \big[ a |000 \rangle + a |101 \rangle + b |010\rangle + b |111 \rangle \big]](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B%5Csqrt%7B2%7D%7D+%5Cbig%5B+a+%7C000+%5Crangle+%2B+a+%7C101+%5Crangle+%2B+b+%7C010%5Crangle+%2B+b+%7C111+%5Crangle+%5Cbig%5D++&bg=FFFFFF&fg=000&s=1&c=20201002)
 . Using the table above, we can express our state in this basis. This will give us four terms that contain a and four terms that contain b. The terms that contain a are
. Using the table above, we can express our state in this basis. This will give us four terms that contain a and four terms that contain b. The terms that contain a are![\frac{a}{2} \big[ |\beta^{AC}_{00}\rangle |0 \rangle + |\beta^{AC}_{10}\rangle |0 \rangle + |\beta^{AC}_{01}\rangle |1 \rangle - |\beta^{AC}_{11} \rangle |1 \rangle \big]](https://s0.wp.com/latex.php?latex=%5Cfrac%7Ba%7D%7B2%7D+%5Cbig%5B+%7C%5Cbeta%5E%7BAC%7D_%7B00%7D%5Crangle+%7C0+%5Crangle+%2B+%7C%5Cbeta%5E%7BAC%7D_%7B10%7D%5Crangle+%7C0+%5Crangle+%2B+%7C%5Cbeta%5E%7BAC%7D_%7B01%7D%5Crangle+%7C1+%5Crangle+-+%7C%5Cbeta%5E%7BAC%7D_%7B11%7D+%5Crangle+%7C1+%5Crangle+%5Cbig%5D++&bg=FFFFFF&fg=000&s=1&c=20201002)
![\frac{b}{2} \big[ |\beta^{AC}_{01}\rangle |0 \rangle + |\beta^{AC}_{11}\rangle |0 \rangle + |\beta^{AC}_{00}\rangle |1 \rangle - |\beta^{AC}_{10} \rangle |1 \rangle \big]](https://s0.wp.com/latex.php?latex=%5Cfrac%7Bb%7D%7B2%7D+%5Cbig%5B+%7C%5Cbeta%5E%7BAC%7D_%7B01%7D%5Crangle+%7C0+%5Crangle+%2B+%7C%5Cbeta%5E%7BAC%7D_%7B11%7D%5Crangle+%7C0+%5Crangle+%2B+%7C%5Cbeta%5E%7BAC%7D_%7B00%7D%5Crangle+%7C1+%5Crangle+-+%7C%5Cbeta%5E%7BAC%7D_%7B10%7D+%5Crangle+%7C1+%5Crangle+%5Cbig%5D++&bg=FFFFFF&fg=000&s=1&c=20201002)
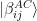 . Thus there are four different possible outcomes of this measurement, which we can read off from the expansion in terms of the Bell basis above.
. Thus there are four different possible outcomes of this measurement, which we can read off from the expansion in terms of the Bell basis above.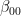
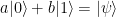
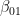
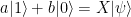


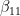




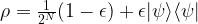
 – of them are in a pure state. The second term in this expression is often called the deviation and denoted by
– of them are in a pure state. The second term in this expression is often called the deviation and denoted by  .
.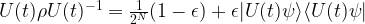
 . Similarly, one can show that if A is an observable, described by a hermitian matrix (which, for technical reasons, we assume to be traceless), then the expectation value of A evaluated on
. Similarly, one can show that if A is an observable, described by a hermitian matrix (which, for technical reasons, we assume to be traceless), then the expectation value of A evaluated on 
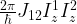


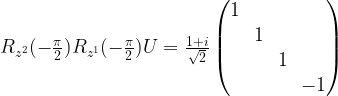
 . The matrix on the right hand side of this equation represents a two-qubit transformation known as the controlled phase gate. This gate corresponds to applying a phase gate to the second qubit, conditional on the state of the first qubit.
. The matrix on the right hand side of this equation represents a two-qubit transformation known as the controlled phase gate. This gate corresponds to applying a phase gate to the second qubit, conditional on the state of the first qubit.