In the last post, we have seen how structures, methods and interfaces in Go are used by the Kubernetes client API to model object oriented behavior. Today, we will continue our walk through to our first example program.
Arrays and slices
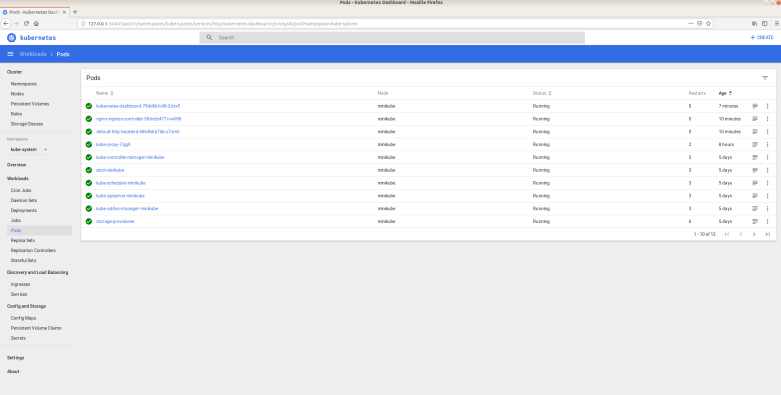
Recall that in the last point, we got to the point that we were able to get a list of all nodes in our cluster using
nodeList, err := coreClient.Nodes().List(metav1.ListOptions{})
Let us now try to better understand what nodeList actually is. If we look up the signature of the List method, we find that it is
List(opts metav1.ListOptions) (*v1.NodeList, error)
So we get a pointer to a NodeList. This in turns has a field Items which is defined as
Items []Node
We can access the field Items using either an explicit dereferencing of the pointer as items := (*nodeList).Items or the shorthand notation items := nodeList.Items.
Now looking at the definition above, it seems that Items is some sort of array whose elements are of type Node, but which does not have a fixed length. So time to learn more about arrays in Go
At the first glance, arrays in Go are very much like in many other languages. A declaration like
var a [5]int
declares an array called a of five integers. Arrays, like in C, cannot be resized. Other than in C, however, an assignment of arrays does not create two pointers that point to the same location in memory, but creates a copy. Thus if you do something like
b := a
you create a second array b which initially is identical to a, but if you modify b, a remains unchanged. This is especially important when you pass arrays to functions – you will pass a copy, and especially for large arrays, this is probably not what you want.
So why not passing pointers to arrays? Well, there is a little problem with that approach. In Go, the length of an array is part of an arrays type, so [5]int and [6]int are different types, which makes it difficult to write functions that accept an array of arbitrary length. For that purpose, Go offers slices which are essentially pointers to arrays.
Arrays are created either by declaring them or by using the new keyword. Slices are created either by slicing an existing array or by using the make keyword. As in Python, slices can refer to a part of an array and we can take slices of an existing slice. When slices are assigned, they refer to the same underlying array, and if a slice is passed as a parameter, no copy of the underlying array is created. So slices are effectively pointers to parts of arrays (with a bit more features, for instance the possibility to extend them by appending data).
How do you loop over a slice? For an array, you know its length and can build an ordinary loop. For a slice, you have two options. First, you can use the built-in function len to get the length of a slice and use that to construct a loop. Or you can use the for statement with range clause which also works for other data structures like strings, maps and channels. So we can iterate over the nodes in the list and print some basic information on them as follows.
items := nodeList.Items
for _, item := range items {
fmt.Printf("%-20s %-10s %s\n", item.Name,
item.Status.NodeInfo.Architecture,
item.Status.NodeInfo.OSImage)
}
Standard types in the Kubernetes API
The elements of the list we are cycling through above are instances of the struct Node, which is declared in the file k8s.io/api/core/v1/types.go. It is instructive to look at this definition for a moment.
type Node struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty" protobuf:"bytes,1,opt,name=metadata"`
Spec NodeSpec `json:"spec,omitempty" protobuf:"bytes,2,opt,name=spec"`
Status NodeStatus `json:"status,omitempty" protobuf:"bytes,3,opt,name=status"`
}
First, we see that the first and second line are examples of embedded fields. It is worth noting that we can address these fields in two different ways. The second field, for instance, is ObjectMeta which has itself a field Name. To access this field when node is of type Node, we could either write node.ObjectMeta.Name or node.Name. This mechanism is called field promotion.
The second thing that is interesting in this definition are the strings like ‘json:”inline”‘ added after some field names. These string literals are called tags. They are mostly ignored, but can be inspected using the reflection API of Go and are, for instance, used by the json marshaller and unmarshaller.
When we take a further look at the file types.go in which these definitions are located and look at its location in our Go workspace and the layout of the various Kubernetes GitHub repositories, we see that (verify this in the output of go list -json k8s.io/client-go/kubernetes) this file is part of the Go package k8s.io/api/core/v1 which is part of the Kubernetes API GitHub repository. As explained here, the Swagger API specification is generated from this file. If you take a look at the resulting API specification, you will see that the comments in the source file appear in the documentation and that the json tags determine the field names that are used in the API.
To further practice navigating the source code and the API documentation, let us try to use the API to create a (naked) pod. The documentation tells us that a pod belongs to the API group core, so that the core client is probably again what we need. So the first few lines of our code will be as before.
home := homedir.HomeDir()
kubeconfig := filepath.Join(home, ".kube", "config")
config, err := clientcmd.BuildConfigFromFlags("", kubeconfig)
if err != nil {
panic(err)
}
clientset, err := kubernetes.NewForConfig(config)
if err != nil {
panic(err)
}
coreClient := clientset.CoreV1()
Next we have to create a Pod. To understand what we need to do, we can again look at the definition of a Pod in types.go which looks as follows.
type Pod struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty" protobuf:"bytes,1,opt,name=metadata"`
Spec PodSpec `json:"spec,omitempty" protobuf:"bytes,2,opt,name=spec"`
Status PodStatus `json:"status,omitempty" protobuf:"bytes,3,opt,name=status"`
As in a YAML manifest file, we will not provide the Status field. The first field that we need is the TypeMeta field. If we locate its definition in the source code, we see that this is again a structure. To create an instance, we can use the following code
metav1.TypeMeta{
Kind: "Pod",
APIVersion: "v1",
}
This will create an unnamed instance of this structure with the specified fields – if you have trouble reading this code, you might want to consult the corresponding section of a Tour in Go. Similarly, we can create an instance of the ObjectMeta structure.
The PodSpec structure is a bit more interesting. The key field that we need to provide is the field Containers which is a slice. To create a slice consisting of one container only, we can use the following syntax
[]v1.Container{
v1.Container{
Name: "my-ctr",
Image: "httpd:alpine",
}
Here the code starting in the second line creates a single instance of the Container structure. Surrounding this by braces gives us an array with one element. We then use this array to initialize our slice.
We could use temporary variables to store all these fields and then assemble our Pod structure step by step. However, in most examples, you will see a coding style avoiding this which heavily uses anonymous structures. So our final result could be
pod := &v1.Pod{
TypeMeta: metav1.TypeMeta{
Kind: "Pod",
APIVersion: "v1",
},
ObjectMeta: metav1.ObjectMeta{
Name: "my-pod",
},
Spec: v1.PodSpec{
Containers: []v1.Container{
v1.Container{
Name: "my-ctr",
Image: "httpd:alpine",
},
},
},
}
It takes some time to get used to expressions like this one, but once you have seen and understood a few of them, they start to be surprisingly readable, as all declarations are in one place. Also note that this gives us a pointer to a Pod, as we use the deferencing & in front of our structure. This pointer can then be used as input for the Create() method of a PodInterface, which finally creates the actual Pod. You can find the full source code here, including all the boilerplate code.
At this point, you should be able to read and (at least roughly) understand most of the source code in the Kubernetes client package. In the next post, we will be digging deeper into this code and trace an API request through the library, starting in your Go program and ending at the communication with the Kubernetes API server.






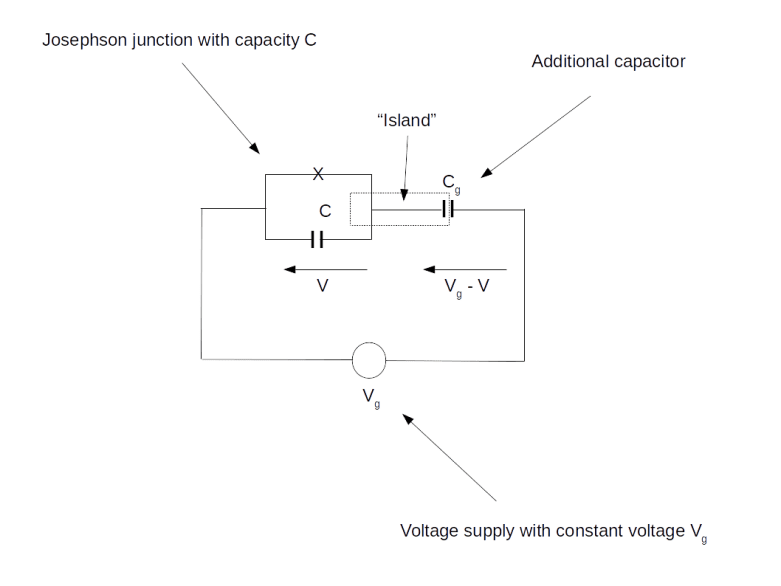
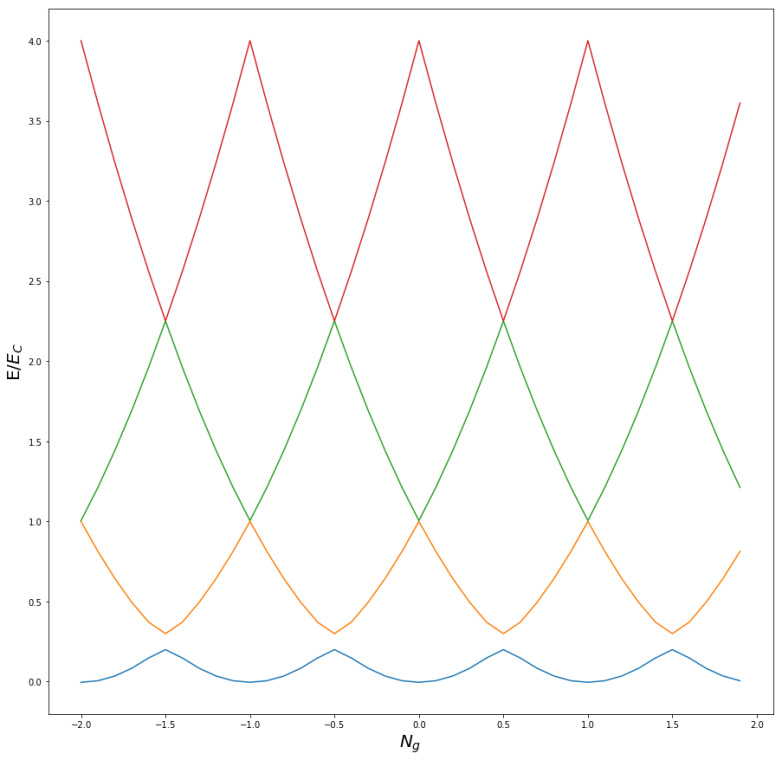
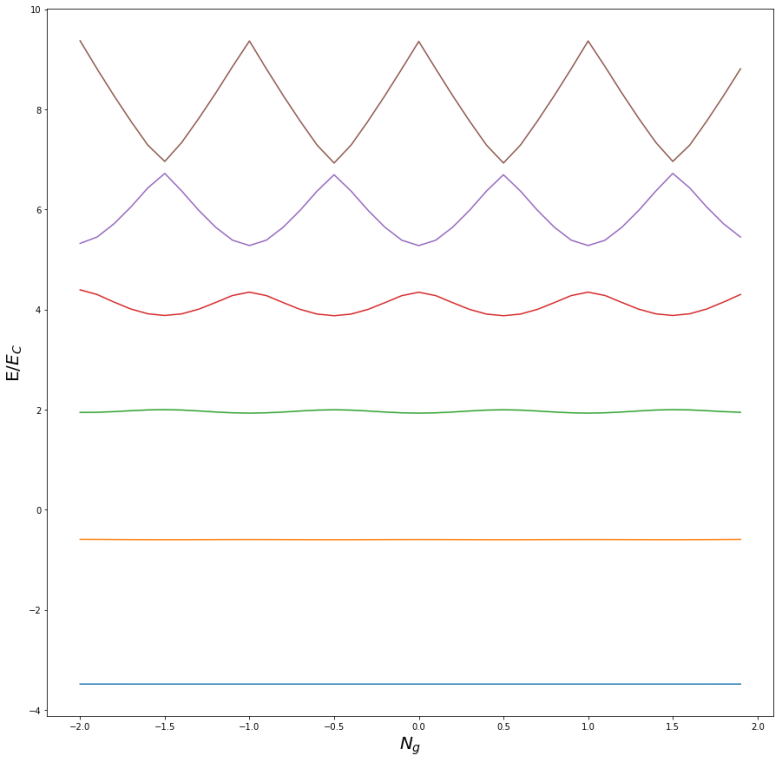
![H = E_C[N - N_g] - E_0 \cos \delta](https://s0.wp.com/latex.php?latex=H+%3D+E_C%5BN+-+N_g%5D+-+E_0+%5Ccos+%5Cdelta++&bg=FFFFFF&fg=000&s=1&c=20201002)
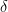 is (proportional to) the flux through the junction. Thus N and
is (proportional to) the flux through the junction. Thus N and