So far, we have used Ansible inventories more or less as a simple list of nodes. But there is much more you can do with inventories – you can assign hosts to groups, build hierarchies of groups, use dynamic inventories and assign variables. In this post, we will look at some of these options.
Groups in inventories
Recall that our simple inventory file (when using the Vagrant setup demonstrated in an earlier post) looks as follows (say this is saved as hosts.ini in the current working directory)
[servers] 192.168.33.10 192.168.33.11
We have two servers and one group called servers. Of course, we could have more than one group. Suppose, for instance, that we change our file as follows.
[web] 192.168.33.10 [db] 192.168.33.11
When running Ansible, we can now specify either the group web or db, for instance
export ANSIBLE_HOST_KEY_CHECKING=False
ansible -u vagrant \
-i hosts.ini \
--private-key ~/vagrant/vagrant_key \
-m ping web
then Ansible will only operate on the hosts in the group web. If you want to run Ansible for all hosts, you can still use the group “all”.
Hosts can be in more than one group. For instance, when we change the file as follows
[web] 192.168.33.10 [db] 192.168.33.10 192.168.33.11
then the host 192.168.33.10 will be on both groups, db and web. If you run Ansible for the db group, it will operate on both hosts, if you run it for the web group, it will operate only on 192.168.33.10. Of course, if you use the pseudo-group all, then Ansible will touch this host only once, even though it appears twice in the configuration file.
It is also possible to define groups as the union of other groups. To create a group that contains all servers, we could for instance do something like
[web] 192.168.33.10 [db] 192.168.33.11 192.168.33.10 [servers:children] db web
Finally, as we have seen in the last post, we can define variables directly in the inventory file. We have already seen this on the level of individual hosts, but it is also possible on the level of groups. Let us take a look at the following example.
[web] 192.168.33.10 [db] 192.168.33.11 192.168.33.10 [servers:children] db web [db:vars] a=5 [servers:vars] b=10
Here we define two variables, a and b. The first variable is defined for all servers in the db group. The second variable is defined for all servers in the servers group. We can print out the values of these variables using the debug Ansible module
ansible -i hosts.ini \
--private-key ~/vagrant/vagrant_key \
-u vagrant -m debug -a "var=a,b" all
which will give us the following output
192.168.33.11 | SUCCESS => {
"a,b": "(5, 10)"
}
192.168.33.10 | SUCCESS => {
"a,b": "(5, 10)"
}
To better understand the structure of an inventory file, it is often useful to create a YAML representation of the file, which is better suited to visualize the hierarchical structure. For that purpose, we can use the ansible-inventory command line tool. The command
ansible-inventory -i hosts.ini --list -y
will create the following YAML representation of our inventory.
all:
children:
servers:
children:
db:
hosts:
192.168.33.10:
a: 5
b: 10
192.168.33.11:
a: 5
b: 10
web:
hosts:
192.168.33.10: {}
ungrouped: {}
which nicely demonstrates that we have effectively built a tree, with the implicit group all at the top, the group servers as the only descendant and the groups db and web as children of this group. In addition, there is a group ungrouped which lists all hosts which are not explicitly assigned to a group. If you omit the -y flag, you will get a JSON representation which lists the variables in a separate dictionary _meta.
Group and host variables in separate files
Ansible also offers you the option to maintain group and host variables in separate files, which can again be useful if you need to deal with different environments. By convention, Ansible will look for variables defined on group level in a directory group_vars that needs to be a subdirectory of the directory in which the inventory file is located. Thus, if your inventory file is called /home/user/somedir/hosts.ini, you would have to create a directory /home/user/somedir/group_vars. Inside this directory, place a YAML file containing a dictionary with key-value pairs which will then be used as variable definitions and whose name is that of the group. In our case, if we wanted to define a variable c for all hosts in the db group, we would create a file group_vars/db.yaml with the following content
--- c: 15
We can again check that this has worked by printing the variables a, b and c.
ansible -i hosts.ini \
--private-key ~/vagrant/vagrant_key \
-u vagrant -m debug -a "var=a,b,c" db
Similary, you could create a directory host_vars and place a file there to define variables for a specific host – again, the file name should match the host name. It is also possible to merge several files – see the corresponding page in the documentation for all the details.
Dynamic inventories
So far, our inventories have been static, i.e. we prepare them before we run Ansible, and they are unchanged while the playbook is running. This is nice in a classical setup where you have a certain set of machines you need to manage, and make changes only if a new machine is physically added to the data center or removed. In a cloud environment, however, the setup tends to be much more dynamic. To deal with this situation, Ansible offers different approaches to manage dynamic inventories that change at runtime.
The first approach is to use inventory scripts. An inventory script is simply a script (an executable, which can be written in any programming language) that creates an inventory in JSON format, similarly to what ansible-inventory does. When you provide such an executable using the -i switch, Ansible will invoke the inventory script and use the output as inventory.
Inventory scripts are invoked by Ansible in two modes. When Ansible needs a full list of all hosts and groups, it will add the switch –list. When Ansible needs details on a specific host, it will pass the switch –host and, in addition, the hostname as an argument.
Let us take a look at an example to see how this works. Ansible comes bundled with a large number of inventory scripts. Let us play with the script for Vagrant. After downloading the script to your working directory and installing the required module paramiko using pip, you can run the script as follows.
python3 vagrant.py --list
This will give you an output similar to the following (I have piped this through jq to improve readability)
{
"vagrant": [
"boxA",
"boxB"
],
"_meta": {
"hostvars": {
"boxA": {
"ansible_user": "vagrant",
"ansible_host": "127.0.0.1",
"ansible_ssh_private_key_file": "/home/chr/vagrant/vagrant_key",
"ansible_port": "2222"
},
"boxB": {
"ansible_user": "vagrant",
"ansible_host": "127.0.0.1",
"ansible_ssh_private_key_file": "/home/chr/vagrant/vagrant_key",
"ansible_port": "2200"
}
}
}
}
We see that the script has created a group vagrant with two hosts, using the names in your Vagrantfile. For each host, it has, in addition, declared some variables, like the private key file, the SSH user and the IP address and port to use for SSH.
To use this dynamically created inventory with ansible, we first have to make the Python script executable, using chmod 700 vagrant.py. Then, we can simply invoke Ansible pointing to the script with the -i switch.
export ANSIBLE_HOST_KEY_CHECKING=False ansible -i vagrant.py -m ping all
Note that we do not have to use the switches –private-key and -u as this information is already present in the inventory.
It is instructive to look at the (rather short) script. Doing this, you will see that behind the scenes, the script simply invokes vagrant status and vagrant ssh-config. This implies, however, that the script will only detect your running instances properly if you execute it – and thus Ansible – in the directory in which your Vagrantfile is living and in which you issued vagrant up to bring up the machines!.
In practice, dynamic inventories are mostly used with public cloud providers. Ansible comes with inventory scripts for virtually every cloud provider you can imagine. As an example, let us try out the script for EC2.
First, there is some setup required. Download the inventory script ec2.py and, placing it in the same directory, the configuration file ec2.ini. Then, make the script executable.
A short look at the script will show you that it uses the Boto library to access the AWS API. So you need Boto installed, and you need to make sure that Boto has access to your AWS credentials, for instance because you have a working AWS CLI configuration (see my previous post on using Python with AWS for more details on this). As explained in the comments in the script, you can also use environment variables to provide your AWS credentials (which are stored in ~/.aws/credentials when you have set up the AWS CLI).
Next, bring up some instances on EC2 and then run the script using
./ec2.py --list
Note that the script uses a cache to avoid having to repeat time-consuming API calls. The expiration time is provided as a parameter in the ec2.ini file. The default is 5 minutes, which can be a bit too long when playing around, so I recommend to change this to e.g. 30 seconds.
Even if you have only one or two machines running, the output that the script produces is significantly more complex than the output of the Vagrant dynamic inventory script. The reason for this is that, instead of just listing the hosts, the EC2 script will group the hosts according to certain criteria (that again can be selected in ec2.ini), for instance availability zone, region, AMI, platform, VPC and so forth. This allows you to target for instance all Linux boxes, all machines running in a specific data center and so forth. If you tag your machines, you will also find that the script groups the hosts by tags. This is very useful and allows you to differentiate between different types of machines (e.g. database servers, web servers), or different stages. The script also attaches certain characteristics as variables to each host.
In addition to inventory scripts, there is a second mechanism to dynamically change an inventory – there is actually an Ansible module which maintains the copy of the inventory that Ansible builds in memory at startup (and thus makes changes that are only valid for this run), the add_host module. This is mostly used when we use Ansible to actually bring up hosts.
To demonstrate this, we will use a slightly different setup as we have used so far. Recall that Ansible can work with any host on which Python is installed and which can be accessed via SSH. Thus, instead of spinning up a virtual machine, we can as well bring up a container and use that to simulate a host. To spin up a container, we can use the Ansible module docker_container that we execute on the control machine, i.e. with the pseudo-group localhost, which is present even if the inventory is empty. After we have created the container, we add the container dynamically to the inventory and can then use it for the remainder of the playbook.
To realize this setup, the first thing which we need is a container image with a running SSH daemon. As base image, we can use the latest version of the official Ubuntu image for Ubuntu bionic. I have created a Dockerfile which, based on the Ubuntu image, installs the OpenSSH server and sudo, creates a user ansible, adds the user to the sudoer group and imports a key pair which is assumed to exist in the directory.
Once this image has been built, we can use the following playbook to bring up a container, dynamically add it to the inventory and run ping on it to test that the setup has worked. Note that this requires that the docker Python module is installed on the control host.
---
# This is our first play - it will bring up a new Docker container and register it with
# the inventory
- name: Bring up a Docker container that we will use as our host and build a dynamic inventory
hosts: localhost
tasks:
# We first use the docker_container module to start our container. This of course assumes that you
# have built the image node:latest according to the Dockerfile which is distributed along with
# this script. We use bridge networking, but do not expose port 22
- name: Run Docker container
docker_container:
auto_remove: yes
detach: yes
name: myTestNode
image: node:latest
network_mode: bridge
state: started
register: dockerData
# As we have chosen not to export the SSH port, we will have to figure out the IP of the container just created. We can
# extract this from the return value of the docker run command
- name: Extract IP address from docker dockerData
set_fact:
ipAddress: "{{ dockerData['ansible_facts']['docker_container']['NetworkSettings']['IPAddress'] }}"
# Now we add the new host to the inventory, as part of a new group docker_nodes
# This inventory is then valid for the remainder of the playbook execution
- name: Add new host to inventory
add_host:
hostname: myTestNode
ansible_ssh_host: "{{ ipAddress }}"
ansible_ssh_user: ansible
ansible_ssh_private_key_file: "./ansible"
groups: docker_nodes
#
# Our second play. We now ping our host using the newly created inventory
#
- name: Ping host
hosts: docker_nodes
become: yes
tasks:
- name: Ping host
ping:
If you want to run this example, you can download all the required files from my GitHub repository, build the required Docker image, generate the key and run the example as follows.
pip install docker git clone https://www.github.com/christianb93/ansible-samples cd ansible-samples/partV ./buildContainer export ANSIBLE_HOST_KEY_CHECKING=False ansible-playbook docker.yaml
This is nice, and you might want to play with this to create additional containers for more advanced test setups. When you do this, however, you will soon realize that it would be very beneficial to be able to execute one task several times, i.e. to use loops. Time to look at control structures in Ansible, which we do in the next post.




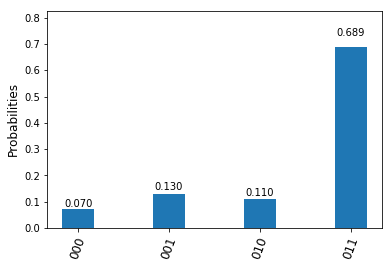
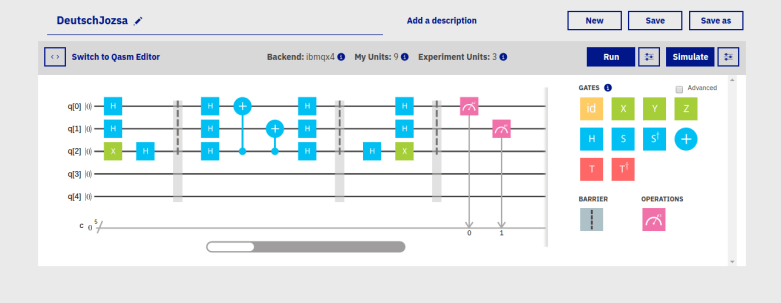
 .
.
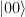









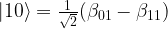

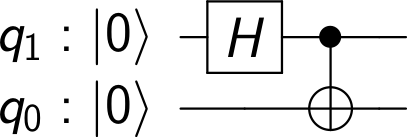
 , stored in some sort of quantum device, which could be a superconducting qubit, a trapped ion, a polarized photon or any other physical implementation of a qubit. Bob is operating a similar device. The task is to create a quantum state in Bob’s device which is identical to the state stored in Alice device.
, stored in some sort of quantum device, which could be a superconducting qubit, a trapped ion, a polarized photon or any other physical implementation of a qubit. Bob is operating a similar device. The task is to create a quantum state in Bob’s device which is identical to the state stored in Alice device. . In fact, this common state does not depend at all on
. In fact, this common state does not depend at all on  (we use the lower index to denote the qubit in which the state lives). We also assume that Alice is able to perform arbitrary measurements and operations on A and C, and that B similarly controls qubit B.
(we use the lower index to denote the qubit in which the state lives). We also assume that Alice is able to perform arbitrary measurements and operations on A and C, and that B similarly controls qubit B.![|\beta_{00}^{AB} \rangle = \frac{1}{\sqrt{2}} \big[ |0\rangle _A |0 \rangle _B+ |1\rangle_A |1 \rangle_B) \big]](https://s0.wp.com/latex.php?latex=%7C%5Cbeta_%7B00%7D%5E%7BAB%7D+%5Crangle+%3D+%5Cfrac%7B1%7D%7B%5Csqrt%7B2%7D%7D+%5Cbig%5B+%7C0%5Crangle+_A+%7C0+%5Crangle+_B%2B+%7C1%5Crangle_A+%7C1+%5Crangle_B%29+%5Cbig%5D++&bg=FFFFFF&fg=000&s=1&c=20201002)
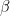 indicates the two qubits in which the Bell state vector lives. This is the common state mentioned above, and it can obviously be prepared upfront, without having the state
indicates the two qubits in which the Bell state vector lives. This is the common state mentioned above, and it can obviously be prepared upfront, without having the state ![|\beta_{00}^{AB} \rangle |\psi\rangle_C = \frac{1}{\sqrt{2}} \big[ a |000 \rangle + a |110 \rangle + b |001\rangle + b |111 \rangle \big]](https://s0.wp.com/latex.php?latex=%7C%5Cbeta_%7B00%7D%5E%7BAB%7D+%5Crangle+%7C%5Cpsi%5Crangle_C+%3D+%5Cfrac%7B1%7D%7B%5Csqrt%7B2%7D%7D+%5Cbig%5B+a+%7C000+%5Crangle+%2B+a+%7C110+%5Crangle+%2B+b+%7C001%5Crangle+%2B+b+%7C111+%5Crangle+%5Cbig%5D++&bg=FFFFFF&fg=000&s=1&c=20201002)
![\frac{1}{\sqrt{2}} \big[ a |000 \rangle + a |101 \rangle + b |010\rangle + b |111 \rangle \big]](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B%5Csqrt%7B2%7D%7D+%5Cbig%5B+a+%7C000+%5Crangle+%2B+a+%7C101+%5Crangle+%2B+b+%7C010%5Crangle+%2B+b+%7C111+%5Crangle+%5Cbig%5D++&bg=FFFFFF&fg=000&s=1&c=20201002)
 . Using the table above, we can express our state in this basis. This will give us four terms that contain a and four terms that contain b. The terms that contain a are
. Using the table above, we can express our state in this basis. This will give us four terms that contain a and four terms that contain b. The terms that contain a are![\frac{a}{2} \big[ |\beta^{AC}_{00}\rangle |0 \rangle + |\beta^{AC}_{10}\rangle |0 \rangle + |\beta^{AC}_{01}\rangle |1 \rangle - |\beta^{AC}_{11} \rangle |1 \rangle \big]](https://s0.wp.com/latex.php?latex=%5Cfrac%7Ba%7D%7B2%7D+%5Cbig%5B+%7C%5Cbeta%5E%7BAC%7D_%7B00%7D%5Crangle+%7C0+%5Crangle+%2B+%7C%5Cbeta%5E%7BAC%7D_%7B10%7D%5Crangle+%7C0+%5Crangle+%2B+%7C%5Cbeta%5E%7BAC%7D_%7B01%7D%5Crangle+%7C1+%5Crangle+-+%7C%5Cbeta%5E%7BAC%7D_%7B11%7D+%5Crangle+%7C1+%5Crangle+%5Cbig%5D++&bg=FFFFFF&fg=000&s=1&c=20201002)
![\frac{b}{2} \big[ |\beta^{AC}_{01}\rangle |0 \rangle + |\beta^{AC}_{11}\rangle |0 \rangle + |\beta^{AC}_{00}\rangle |1 \rangle - |\beta^{AC}_{10} \rangle |1 \rangle \big]](https://s0.wp.com/latex.php?latex=%5Cfrac%7Bb%7D%7B2%7D+%5Cbig%5B+%7C%5Cbeta%5E%7BAC%7D_%7B01%7D%5Crangle+%7C0+%5Crangle+%2B+%7C%5Cbeta%5E%7BAC%7D_%7B11%7D%5Crangle+%7C0+%5Crangle+%2B+%7C%5Cbeta%5E%7BAC%7D_%7B00%7D%5Crangle+%7C1+%5Crangle+-+%7C%5Cbeta%5E%7BAC%7D_%7B10%7D+%5Crangle+%7C1+%5Crangle+%5Cbig%5D++&bg=FFFFFF&fg=000&s=1&c=20201002)
 . Thus there are four different possible outcomes of this measurement, which we can read off from the expansion in terms of the Bell basis above.
. Thus there are four different possible outcomes of this measurement, which we can read off from the expansion in terms of the Bell basis above.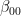
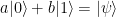
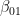
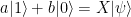


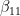

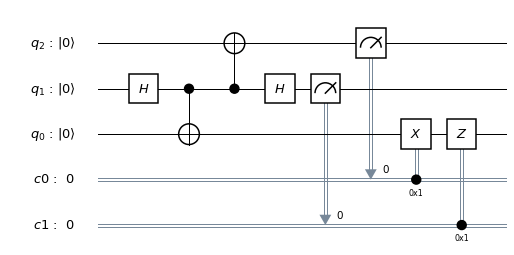
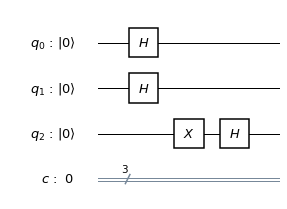
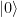 . Therefore, a measurement of this qubit will always yield zero. Thus our final test circuit looks as follows.
. Therefore, a measurement of this qubit will always yield zero. Thus our final test circuit looks as follows.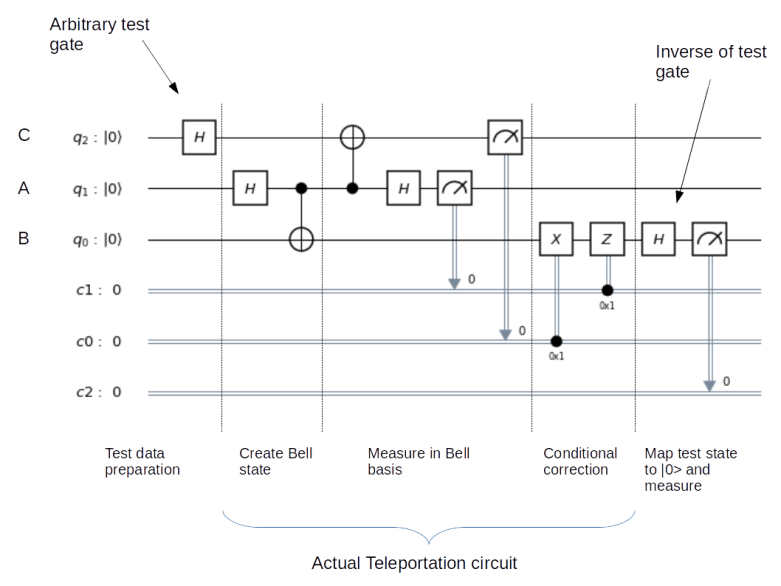



 and to which we apply a sequence of controlled multiplications by powers of a, and a working register, in which we do a quantum Fourier transform in the second step. The primary register needs to hold M=15, so we need four qubits there. For the working register, we use three qubits, which is the smallest possible choice, to keep the number of gates small.
and to which we apply a sequence of controlled multiplications by powers of a, and a working register, in which we do a quantum Fourier transform in the second step. The primary register needs to hold M=15, so we need four qubits there. For the working register, we use three qubits, which is the smallest possible choice, to keep the number of gates small. . Thus we only need to implement a unitary transformation which conditionally maps the state
. Thus we only need to implement a unitary transformation which conditionally maps the state 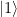 to the state
to the state  . In binary notation, eleven is 1011, and we therefore simply need to conditionally flip qubits 3 and 1. We also need a Pauli X gate in the primary register to build the initial state
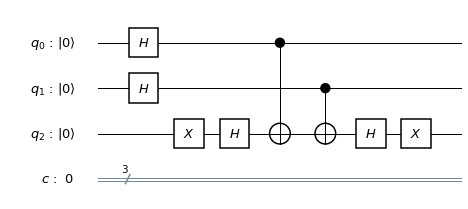
. In binary notation, eleven is 1011, and we therefore simply need to conditionally flip qubits 3 and 1. We also need a Pauli X gate in the primary register to build the initial state 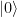 and Hadamard gates in the working register to create the initial superposition. Thus the first part of our circuit looks as follows.
and Hadamard gates in the working register to create the initial superposition. Thus the first part of our circuit looks as follows.

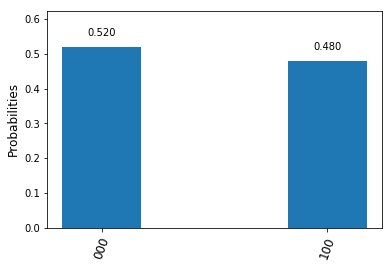
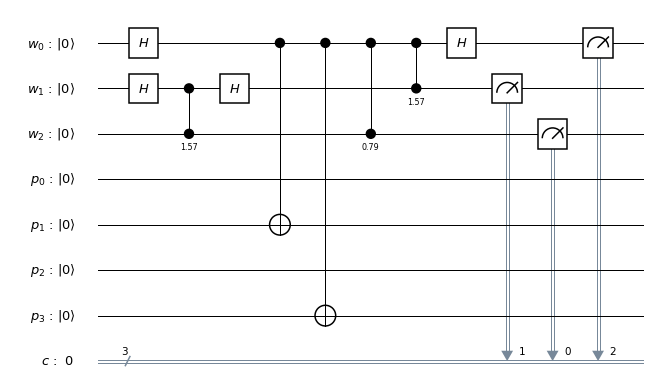

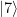 , and we can again implement this by two conditional bit flips, i.e. two CNOT gates.
, and we can again implement this by two conditional bit flips, i.e. two CNOT gates.




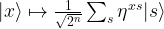
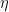 is an 2n-th root of unity with n being the number of qubits in the register, i.e.
is an 2n-th root of unity with n being the number of qubits in the register, i.e.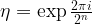
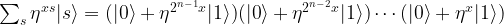


 plus a multiple of 2n. As
plus a multiple of 2n. As 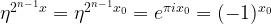






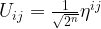

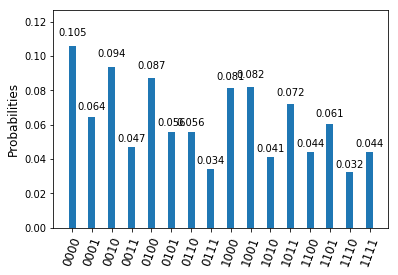



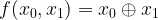
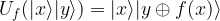


 , so that our state is now
, so that our state is now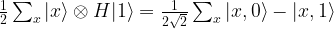
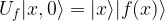



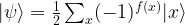
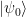 . Clearly,
. Clearly,

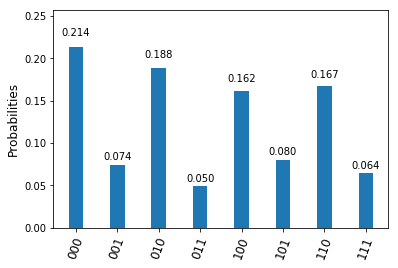
 when we perform a measurement in the computational basis. Thus we finally obtain the following circuit
when we perform a measurement in the computational basis. Thus we finally obtain the following circuit