
In the last post, we have seen how Python can be used to control the generation of an EKS cluster. However, an EKS cluster without any worker nodes – and hence without the ability to start pods and services – is of very limited use. Today, we therefore take a look at the process of adding worker nodes.
Again, we roughly follow the choreography of Amazons Getting started with EKS guide, but instead of going through the individual steps using the console first, we start using the API and the Python SDK right away.
This description assumes that you have started an EKS cluster as described in my last post. If not, you can do this by running the create_cluster Python script that executes all necessary steps.
Essentially, we will do two things. First, we will create an AWS Auto-Scaling group that we will use to manage our worker nodes. This can be done using the AWS API and the Python SDK. Part of this setup will be a new role, that, in a second step, we need to make known to Kubernetes so that our nodes can join the cluster. This will be done using the Kubernetes API. Let us now look at each of these steps in turn.
Creating an auto-scaling group
An auto-scaling group is essentially a group of EC2 instances that are combined into one management unit. When you set up an auto-scaling group, you specify a scaling policy and AWS will apply that policy to make sure that a certain number of instances is automatically running in your group. If the number of instances drops below a certain value, or if the load increases (depending on the policy), then AWS will automatically spin up new instances for you.
We will use AWS CloudFormation to set up the auto-scaling group, using the template referenced in the “Getting started” guide. This is not an introduction into CloudFormation, but it is instructive to look at this template, stored at this URL.
If you look at this file, you will recognize a few key elements. First, there are parameters whose values we will have to provide when we use the template. These parameters are
- A unique name for the node group
- The name of an SSH key pair that we will later use to log into our nodes. I recommend to create a separate key pair for this, and I will assume that you have done this and that this key pair is called eksNodeKey
- An instance type that AWS will use to spin up nodes
- The ID of an AMI image that will be used to spin up the nodes. In this tutorial, we will use Kubernetes v1.11 and the specific AWS provided AMIs which are listed in the Getting started guide. I work in the region eu-frankfurt-1, and will therefore use the AMI ID ami-032ed5525d4df2de3
- The minimum, maximum and desired size of the auto-scaling group. We will use one for the minimum size, two for the desired size and three for the maximum size, so that our cluster will come up with two nodes initially
- The size of the volume attached to each node – we will not provide a value for this and stick to the default (20 GB at the time of writing)
- In addition, we will have to supply the VPC, the subnets and the security group that we used before
In addition to the parameters, the CloudFormation template contains a list of resources that will be created. We see that in addition to several security groups and the auto scaling group, a IAM role called the node instance role and a corresponding instance profile is created. This is the role that the nodes will assume to interact with the Kubernetes master, and behind the scenes, the AWS IAM authenticator will be used to map this IAM role to a Kubernetes user, so that the nodes can authenticate themselves against the Kubernetes API. This requires some configuration, more precisely a mapping between IAM roles and Kubernetes users, which we will set up in our second steps in the next section.
So how do we apply this cloud formation template? Again, the AWS API comes to the rescue. It provides an API endpoint (client) for CloudFormation which has a method create_stack. This method expects a Python data structure that contains the parameters that we want to use, plus the URL of the cloud formation template. It will then take the template, apply the parameters, and create the resources defined in the template.
Building the parameter structure is easy, assuming that you have already stored all configuration data in Python variables (we can use the same method as in the last post to retrieve cluster data like the VPC ID). The only tricky part is the list of subnets. In CloudFormation, a parameter value that is a list needs to be passed as a comma separated list, not as a JSON list (it took me some failed attempts to figure out this one). Hence we need to convert our list of subnets into CSV format. The code snippet to set up the parameter map then looks as follows.
params = [
{'ParameterKey' : 'KeyName' ,
'ParameterValue' : sshKeyPair },
{'ParameterKey' : 'NodeImageId' ,
'ParameterValue' : amiId },
{'ParameterKey' : 'NodeInstanceType' ,
'ParameterValue' : instanceType },
{'ParameterKey' : 'NodeAutoScalingGroupMinSize' ,
'ParameterValue' : '1' },
{'ParameterKey' : 'NodeAutoScalingGroupMaxSize' ,
'ParameterValue' : '3' },
{'ParameterKey' : 'NodeAutoScalingGroupDesiredCapacity' ,
'ParameterValue' : '2' },
{'ParameterKey' : 'ClusterName' ,
'ParameterValue' : clusterName },
{'ParameterKey' : 'NodeGroupName' ,
'ParameterValue' : nodeGroupName },
{'ParameterKey' : 'ClusterControlPlaneSecurityGroup' ,
'ParameterValue' : secGroupId },
{'ParameterKey' : 'VpcId' ,
'ParameterValue' : vpcId },
{'ParameterKey' : 'Subnets' ,
'ParameterValue' : ",".join(subnets) },
]
Some of the resources created by the template are IAM resources, and therefore we need to confirm explicitly that we allow for this. To do this, we need to specify a specific capability when calling the API. With that, our call now looks as follows.
cloudFormation = boto3.client('cloudformation')
cloudFormation.create_stack(
StackName = stackName,
TemplateURL = templateURL,
Parameters = params,
Capabilities = ['CAPABILITY_IAM'])
Here the template URL is the location of the CloudFormation template provided above, and stack name is some unique name that we use for our stack (it is advisable to include the cluster name, so that you can create and run more than one cluster in parallel).
When you run this command, several things will happen, and it is instructive to take a look at the EC2 console and the CloudFormation console while the setup is in progress. First, you will find that a new stack appears on the CloudFormation console, being in status “In Creation”.
Second, the EC2 console will display – after a few seconds – a newly created auto scaling group, with the parameters specified in the template, and a few additional security groups.
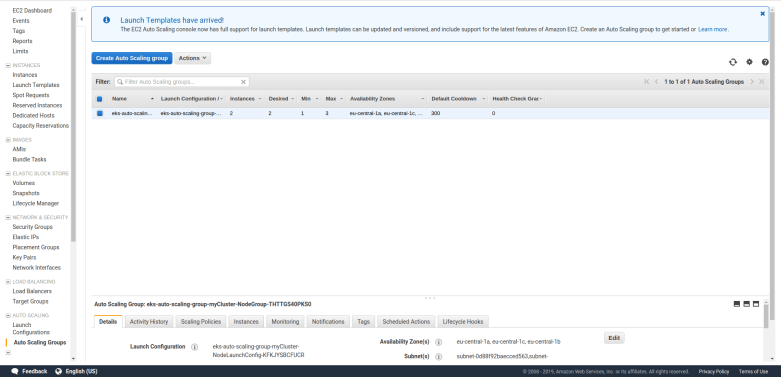
And when you list your instances, you will find that AWS will spin up two instances of the specified type. These instances will come up as usual and are ordinary EC2 instances.
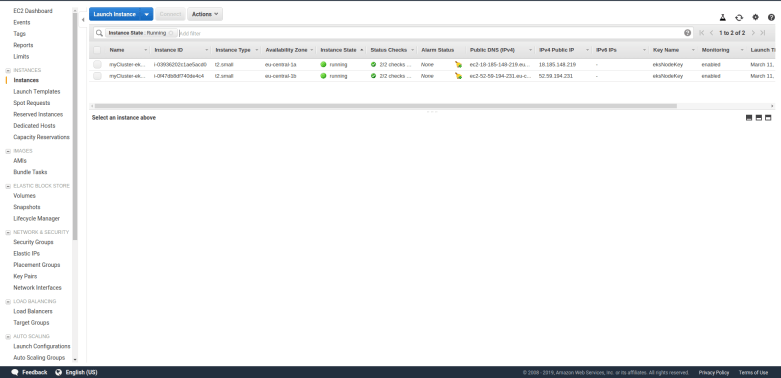
Remember that we specified a key pair when we created the auto-scaling group? Hopefully, you did save the PEM file – if yes, you can now SSH into your nodes. For that purpose, you will have to modify the security group of the nodes and open the SSH port for inbound traffic from your own network. Once this has been done, you can simply use an ordinary SSH command to connect to your machines.
$ ssh -i eksNodeKey.pem ec2-user@18.197.140.230
where of course you need to replace 18.197.140.230 with whatever public IP address the instance has. You can now inspect the node, for instance doing docker ps to see which docker containers are already running on the node, and you can use ps ax to see which processes are running.
Attaching the auto-scaling group to Kubernetes
At this point, the nodes are up and running, but in order to register with Kubernetes, they need to talk to the Kubernetes API. More specifically, the kubelet running on the node will try to connect to the cluster API and therefore act as a Kubernetes client. As every Kubernetes client, this requires some authorization. This field is a bit tricky, but let me try to give a short overview (good references for what follows are the documentation of the AWS IAM authenticator, this excellent blog post, and the Kubernetes documentation on authorization).
Kubernetes comes with several possible authentication methods. The method used by EKS is called bearer token. With this authentication method, a client request contains a token in its HTTPS header which is used by Kubernetes to authorize the request. To create and verify this token, a special piece of software is used – the AWS IAM authenticator. This utility can operate in client mode – it then generates a token – and in server mode, where it verifies a token.
The basic chain of events when a client like kubectl wants to talk to the API is as follows.
- The client consults the configuration file
~/.kube/configto determine the authorization method to be used - In our case, this configuration refers to the AWS IAM authenticator, so the client calls this authenticator
- The authenticator looks up the current AWS credentials, uses them to generate a token and returns that token to the client
- The client sends the token to the API endpoint along with the request
- The Kubernetes API server extracts the token and invokes the authenticator running on the Kubernetes management nodes (as a server)
- The authenticator uses the token to determine the IAM role used by the client and to verify it
- It then maps the IAM role to a Kubernetes user which is then used for authorization
You can try this yourself. Log into one of the worker nodes and run the command
$ aws sts get-caller-identity
This will return the IAM role ARN used by the node. If you compare this with the output of the CloudFormation stack that we have used to create our auto-scaling group, you will find that the node assumes the IAM role created when our auto-scaling group was generated. Let us now verify that this identity is also used when the AWS IAM authenticator creates a token. For that purpose, let us manually create a token by running – still on the node – the command
$ aws-iam-authenticator token -i myCluster
This will return a dictionary in JSON format, containing a key called token. Extract the value of this key, this will be a base64 encoded string starting with “k8s-aws-v1”. Now, fortunately the AWS authenticator also offers an operation called verify that we can use to extract the IAM role again from the token. So run
$ aws-iam-authenticator verify -i myCluster -d ""k8s-aws-v1..."
where the dots represent the full token extracted above. As a result, the authenticator will print out the IAM role, which we again recognize as the IAM role created along with the auto-scaling group.
Essentially, when the kubelet connects to the server and the AWS IAM authenticator running on the server receives the token, it will use the same operation to extract the IAM role. It then needs to map the IAM role to a Kubernetes role. But where does this mapping information come from?
The answer is that we have to provide it using the standard way to store configuration data in a Kubernetes cluster, i.e. by setting up a config map.
Again, Amazon provides a template for this config map in YAML format, which looks as follows.
apiVersion: v1
kind: ConfigMap
metadata:
name: aws-auth
namespace: kube-system
data:
mapRoles: |
- rolearn:
username: system:node:{{EC2PrivateDNSName}}
groups:
- system:bootstrappers
- system:nodes
Thus our config map contains exactly one key-value pair, with key mapRoles. The value of this key is again a string in YAML format (note that the pipe is an escape character in YAML which instructs us to treat the next lines as a multi-line string, not as a list). Of course, we have to replace the placeholder by the ARN of the role that we want to map, i.e. the role created along with the auto-scaling group.
To create this config map, we will have to use the Python SDK for Kubernetes that will allow us to talk to the Kubernetes API. To install it, run
$ pip3 install kubernetes
To be able to use the API from within our Python script, we of course have to import some components from this library and read our kubectl configuration file, which is done using the following code.
from kubernetes import client, config config.load_kube_config() v1 = client.CoreV1Api()
The object that we call v1 is the client that we will use to create and submit API requests. To create our config map, we first need to instantiante an object of the type V1ConfigMap and populate it. Assuming that the role ARN we want to map is stored in the Python variable nodeInstanceRole, this can be done as follows.
body = client.V1ConfigMap()
body.api_version="v1"
body.metadata = {}
body.metadata['name'] = "aws-auth"
body.metadata['namespace'] = "kube-system"
body.data = {}
body.data['mapRoles'] = "- rolearn: " + nodeInstanceRole + "\n username: system:node:{{EC2PrivateDNSName}}\n groups:\n - system:bootstrappers\n - system:nodes\n"
Finally, we call the respective method to actually create the config map.
v1.create_namespaced_config_map("kube-system", body)
Once this method completes, our config map should be in place. You can verify this by running kubectl on your local machine to describe the config map.
$ kubectl describe configMaps aws-auth -n kube-system
Name: aws-auth
Namespace: kube-system
Labels:
Annotations:
Data
====
mapRoles:
----
- rolearn: arn:aws:iam::979256113747:role/eks-auto-scaling-group-myCluster-NodeInstanceRole-HL95F9DBQAMD
username: system:node:{{EC2PrivateDNSName}}
groups:
- system:bootstrappers
- system:nodes
Events:
If you see this output, we are done. The EC2 instances should now be able to connect to the Kubernetes master nodes, and when running
$ kubectl get nodes
you should get a list displaying two nodes. Congratulations, you have just set up your first Kubernetes cluster!
The full Python script which automates these steps can as usual be retrieved from GitHub. Once you are done playing with your cluster, do not forget to delete everything again, i.e. delete the auto-scaling group (which will also bring down the nodes) and the EKS cluster to avoid high charges. The best approach to clean up is to delete the CloudFormation stack that we have used to bring up the auto-scaling group (in the AWS CloudFormation console), which will also terminate all nodes, and then use the AWS EKS console to delete the EKS cluster as well.
This completes our post for today. In the next post in this series, we will learn how we can actually deploy containers into our cluster.

3 Comments