
In this post, we will look in some more detail into networking in a Kubernetes cluster. Even though the Kubernetes networking model is independent of the underlying cloud provider, the actual implementation does of course depend on the cloud provider which communicates with Kubernetes through a CNI plugin.
I will continue to use EKS, so some of this will be EKS specific. To work with me through the example, you will first have to bring up your cluster, start two nodes and deploy a pod running a httpd on one of the nodes. I have written a script up.sh and a manifest file that automates all this. To download and apply all this, enter
$ git clone https://github.com/christianb93/Kubernetes.git $ cd Kubernetes/cluster $ chmod 700 up.sh $ ./up.sh $ kubectl apply -f ../pods/alpine.yaml
Node-to-Pod networking
Now let us log into the node on which the container is running and collect some information on the local network interface attached to the VM.
$ ifconfig eth0
eth0: flags=4163 mtu 9001
inet 192.168.118.64 netmask 255.255.192.0 broadcast 192.168.127.255
inet6 fe80::2b:dcff:fee7:448c prefixlen 64 scopeid 0x20
ether 02:2b:dc:e7:44:8c txqueuelen 1000 (Ethernet)
RX packets 197837 bytes 274587781 (261.8 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 25656 bytes 2389608 (2.2 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
So the local IP address of the node is 192.168.118.64. If we do a kubectl get pods -o wide, we get a different IP address – 192.168.99.199 – for the pod. Let us curl this from the node.
$ curl 192.168.99.199 <h1>It works!</h1>
So apparently we have reached our httpd. To understand why this works, let us investigate the network configuration in more detail. First, on the node on which the container is running, let us take a look at the network configuration inside the container.
$ ID=$(docker ps --filter name=alpine-ctr --format "{{.ID}}")
$ docker exec -it $ID "/bin/bash"
bash-4.4# ip link
1: lo: mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
3: eth0@if6: mtu 9001 qdisc noqueue state UP
link/ether 4a:8b:c9:bb:8c:8e brd ff:ff:ff:ff:ff:ff
bash-4.4# ifconfig eth0
eth0 Link encap:Ethernet HWaddr 4A:8B:C9:BB:8C:8E
inet addr:192.168.99.199 Bcast:192.168.99.199 Mask:255.255.255.255
UP BROADCAST RUNNING MULTICAST MTU:9001 Metric:1
RX packets:12 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:936 (936.0 B) TX bytes:0 (0.0 B)
bash-4.4# ip route
default via 169.254.1.1 dev eth0
169.254.1.1 dev eth0 scope link
What do we learn from this? First, we see that inside the container namespace, there is a virtual ethernet device eth0, with IP address 192.168.99.199. If you run kubectl get pods -o wide on your local workstation, you will find that this is the IP address of the Pod. We also see that there is a route in the container namespace that direct all traffic to this interface. The output of the ip link command also shows that this device is a virtual ethernet device that has a paired device (with index if6) in a different namespace. So let us exit the container, go back to the node and try to figure out what the network configuration on the node is.
$ ip link
1: lo: mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: mtu 9001 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 02:2b:dc:e7:44:8c brd ff:ff:ff:ff:ff:ff
3: eni3f5399ec799: mtu 9001 qdisc noqueue state UP mode DEFAULT group default
link/ether 66:37:e5:82:b1:f6 brd ff:ff:ff:ff:ff:ff link-netnsid 0
4: enie68014839ee@if3: mtu 9001 qdisc noqueue state UP mode DEFAULT group default
link/ether f6:4f:62:dc:38:18 brd ff:ff:ff:ff:ff:ff link-netnsid 1
5: eth1: mtu 9001 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 02:e8:f0:26:a7:3e brd ff:ff:ff:ff:ff:ff
6: eni97d5e6c4397@if3: mtu 9001 qdisc noqueue state UP mode DEFAULT group default
link/ether b2:c9:58:c0:20:25 brd ff:ff:ff:ff:ff:ff link-netnsid 2
$ ifconfig eth0
eth0: flags=4163 mtu 9001
inet 192.168.118.64 netmask 255.255.192.0 broadcast 192.168.127.255
inet6 fe80::2b:dcff:fee7:448c prefixlen 64 scopeid 0x20
ether 02:2b:dc:e7:44:8c txqueuelen 1000 (Ethernet)
RX packets 197837 bytes 274587781 (261.8 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 25656 bytes 2389608 (2.2 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
$ ip route
default via 192.168.64.1 dev eth0
169.254.169.254 dev eth0
192.168.64.0/18 dev eth0 proto kernel scope link src 192.168.118.64
192.168.89.17 dev eni3f5399ec799 scope link
192.168.99.199 dev eni97d5e6c4397 scope link
192.168.109.216 dev enie68014839ee scope link
Here we see that – in addition to a few other interfaces – there is a device eth0 to which all traffic is sent by default. However, there is also a device eni97d5e6c4397 which is the other end of the interface visible in the container. And there is a route that sends all traffic that is directed to the IP address of the pod to this interface. Overall, this gives a picture which seems familiar from our earlier analysis of docker networking
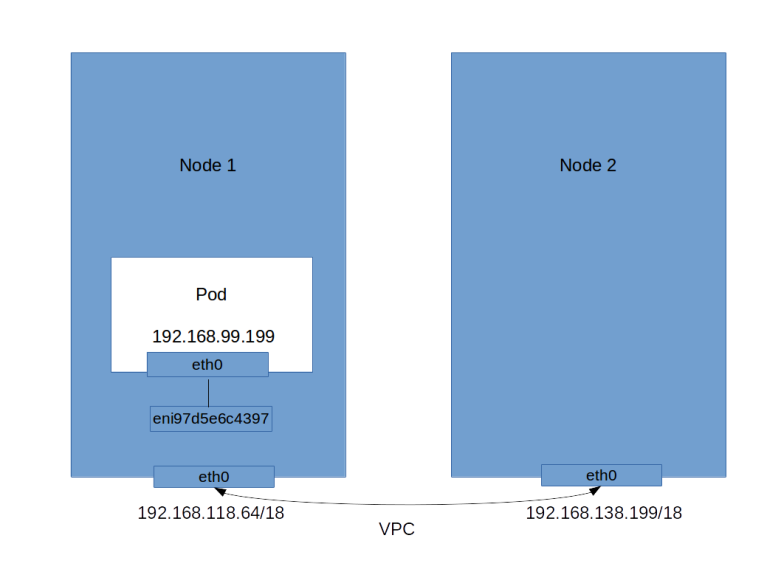
If we try to establish a connection to the httpd running in the pod, the routing table entry on the node will send the traffic to the interface eni97d5e6c4397. This is one end of a veth-pair, the other end appears inside the container as eth0. So from the containers point of view, this is incoming traffic received via eth0, which is happily accepted and processed by the httpd. The reply goes the other way – it is directed to eth0 inside the container, travels via the veth pair and ends up inside the host namespace, coming from eni97d5e6c4397.
Pod-to-Pod networking across nodes
Now let us try something else. Log into the second node – on which the container is not running – and try the curl from there. Surprisingly, this works as well! What we have seen so far does not explain this, so there is probably a piece of magic that we are still missing. To find this, let us use the aws cli to print out the network interfaces attached to the node on which the container is running (the following snippet assumes that you have the extremely helpful tool jq installed on your PC).
$ nodeName=$(kubectl get pods --output json | jq -r ".items[0].spec.nodeName")
$ aws ec2 describe-instances --output json --filters Name=private-dns-name,Values=$nodeName --query "Reservations[0].Instances[0].NetworkInterfaces"
---- SNIP -----
{
"MacAddress": "02:e8:f0:26:a7:3e",
"SubnetId": "subnet-06088e09ce07546b9",
"PrivateDnsName": "ip-192-168-84-108.eu-central-1.compute.internal",
"VpcId": "vpc-060469b2a294de8bd",
"Status": "in-use",
"Ipv6Addresses": [],
"PrivateIpAddress": "192.168.84.108",
"Groups": [
{
"GroupName": "eks-auto-scaling-group-myCluster-NodeSecurityGroup-1JMH4SX5VRWYS",
"GroupId": "sg-08163e3b40afba712"
}
],
"NetworkInterfaceId": "eni-0ed2f1cf4b09cb8be",
"OwnerId": "979256113747",
"PrivateIpAddresses": [
{
"Primary": true,
"PrivateDnsName": "ip-192-168-84-108.eu-central-1.compute.internal",
"PrivateIpAddress": "192.168.84.108"
},
{
"Primary": false,
"PrivateDnsName": "ip-192-168-72-200.eu-central-1.compute.internal",
"PrivateIpAddress": "192.168.72.200"
},
{
"Primary": false,
"PrivateDnsName": "ip-192-168-96-163.eu-central-1.compute.internal",
"PrivateIpAddress": "192.168.96.163"
},
{
"Primary": false,
"PrivateDnsName": "ip-192-168-99-199.eu-central-1.compute.internal",
"PrivateIpAddress": "192.168.99.199"
}
],
---- SNIP ----
I have removed some of the output to keep it readable. We see that AWS has attached several elastic network interfaces (ENI) to our node. An ENI is a virtual network interface that AWS creates and manages for you. Each node can have more than one ENI attached, and each ENI can have a primary and multiple secondary IP addresses.
If you look at the last line of the output, you see that there is a network interface eni-0ed2f1cf4b09cb8be that has, as one of the secondary IP addresses, the IP address 192.168.99.199. This is the IP address of our Pod! Let us now go back to the node and inspect its network configuration once more. You will not find a network interface with this exact name, but you will find a network interface on the node on which the pod is running which has the same MAC address, namely eth1.
$ ifconfig eth1
eth1: flags=4163 mtu 9001
inet6 fe80::e8:f0ff:fe26:a73e prefixlen 64 scopeid 0x20
ether 02:e8:f0:26:a7:3e txqueuelen 1000 (Ethernet)
RX packets 224 bytes 6970 (6.8 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 20 bytes 1730 (1.6 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
This is an ordinary VPC interface and visible in the entire VPC under all of its IP addresses. So if we curl our httpd from the second node, the traffic will leave that node via the default interface, be picked up by the VPC, routed to the node on which the pod is running and enter via eth1. As IP forwarding is enabled on this node, the traffic will be routed to the Pod and arrive at the httpd.
This is the missing piece of magic we have been looking for. In fact, for every pod running on a node, EKS will add an additional secondary IP address to an ENI attached to the node (and attach additional ENIs if needed) which will make the Pod IP addressses visible in the entire VPC. This mechanism is nicely described in the documentation of the CNI plugin which EKS uses. So we now have the following picture.

So this allows us to run our httpd in such a way that it can be reached from the entire Pod network (and the entire VPC). Note, however, that it can of course not be reached from the outside world. It is interesting to repeat this experiment with a slighly adapted YAML file that uses the containerPort field:
apiVersion: v1
kind: Pod
metadata:
name: alpine
namespace: default
spec:
containers:
- name: alpine-ctr
image: httpd:alpine
ports:
- containerPort: 80
If we remove the old Pod and use this YAML file to create a new pod, we will find that the configuration does not change at all. In particular, running docker ps on the node on which the Pod is scheduled will teach you that this port specification is not the equivalent of the port specification of the docker run port mapping feature – as the Kubernetes API specification states, this field is informational.
Implementation of services
Let us now see how this picture changes if we add a service. First, we will use a service of type ClusterIP, i.e. a service that will make our httpd reachable from within the entire cluster under a common IP address. For that purpose – after deleting our existing pods – let us create a deployment that brings up two instances of the httpd.
$ kubectl apply -f https://raw.githubusercontent.com/christianb93/Kubernetes/master/pods/deployment.yaml
Once the pods are up, you can again use curl to verify that you can talk to every pod from every node and every pod. Now let us create a service.
$ kubectl apply -f https://raw.githubusercontent.com/christianb93/Kubernetes/master/network/service.yaml
Once that has been done, enter kubectl get svc to get a list all services. You should see a newly created service alpine-service. Note down its cluster IP address – in my case this was 10.100.11.202.
Now log into one of the nodes again, attach to the container, install curl there and try to connect to port 10.100.11.202:8080
$ ID=$(docker ps --filter name=alpine-ctr --format "{{.ID}}")
$ docker exec -it $ID "/bin/bash"
bash-4.4# apk add curl
OK: 124 MiB in 67 packages
bash-4.4# curl 10.100.11.202:8080
<h1>It works!</h1>
So, as promised by the definition of s service, the httpd is visible within the cluster under the cluster IP address of the service. The same works if we are on a node and not attached to a container.
To see how this works, let us log out of the container again and search the NAT tables for the cluster IP address of the service.
$ sudo iptables -S -t nat | grep 10.100.11.202 -A KUBE-SERVICES -d 10.100.11.202/32 -p tcp -m comment --comment "default/alpine-service: cluster IP" -m tcp --dport 8080 -j KUBE-SVC-SXWLG3AINIW24QJC
So we see that Kubernetes (more precisely the kube-proxy running on each node) has added a NAT rule that captures traffic directed towards the service IP address to a special chain. Let us dump this chain.
$ sudo iptables -S -t nat | grep KUBE-SVC-SXWLG3AINIW24QJC -N KUBE-SVC-SXWLG3AINIW24QJC -A KUBE-SERVICES -d 10.100.11.202/32 -p tcp -m comment --comment "default/alpine-service: cluster IP" -m tcp --dport 8080 -j KUBE-SVC-SXWLG3AINIW24QJC -A KUBE-SVC-SXWLG3AINIW24QJC -m comment --comment "default/alpine-service:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-YRELRNVKKL7AIZL7 -A KUBE-SVC-SXWLG3AINIW24QJC -m comment --comment "default/alpine-service:" -j KUBE-SEP-BSEIKPIPEEZDAU6E
Now this is actually pretty interesting. The first line is simply the creation of the chain. The second line is the line that we already looked at above. The next two lines are the lines we are looking for. We see that, with a probability of 50%, we either jump to the chain KUBE-SEP-YRELRNVKKL7AIZL7 or to the chain KUBE-SEP-BSEIKPIPEEZDAU6E. Let us display one of them.
$ sudo iptables -S KUBE-SEP-BSEIKPIPEEZDAU6E -t nat -N KUBE-SEP-BSEIKPIPEEZDAU6E -A KUBE-SEP-BSEIKPIPEEZDAU6E -s 192.168.191.152/32 -m comment --comment "default/alpine-service:" -j KUBE-MARK-MASQ -A KUBE-SEP-BSEIKPIPEEZDAU6E -p tcp -m comment --comment "default/alpine-service:" -m tcp -j DNAT --to-destination 192.168.191.152:80
So we see the that this chain has two rules. The first rule marks all packages that are originating from the pod running on this node, this mark is later evaluated in the forwarding rules to make sure that the packet is accepted for forwarding. The second rule is where the magic happens – it performs a DNAT, i.e. a destination NAT, and sends our packets to one of the pods. The rule KUBE-SEP-YRELRNVKKL7AIZL7 is similar, with the only difference that it sends the packets to the other pod. So we see that two things are happening
- Traffic directed towards port 8080 of the cluster IP address is diverted to one of the pods
- Which one of the pods is selected is determined randomly, with a probability of 50% for both pods. Thus these rules implement a simple load balancer.
Let us now see how things change when we use a service of type NodePort. So let us use a slightly different YAML file.
$ kubectl delete -f https://raw.githubusercontent.com/christianb93/Kubernetes/master/network/service.yaml $ kubectl apply -f https://raw.githubusercontent.com/christianb93/Kubernetes/master/network/nodePortService.yaml
When we now run kubectl get svc, we see that our service appears as a NodePort service, and, as the second entry in the columns PORTS, we find the port that Kubernetes opens for us.
$ kubectl get services NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE alpine-service NodePort 10.100.165.3 8080:32755/TCP 13s kubernetes ClusterIP 10.100.0.1 443/TCP 7h
In my case, the port 32755 has been used. If we now go back to one of the nodes and search the iptables rules for this port, we find that Kubernetes has created two additional NAT rules.
$ sudo iptables -S -t nat | grep 32755 -A KUBE-NODEPORTS -p tcp -m comment --comment "default/alpine-service:" -m tcp --dport 32755 -j KUBE-MARK-MASQ -A KUBE-NODEPORTS -p tcp -m comment --comment "default/alpine-service:" -m tcp --dport 32755 -j KUBE-SVC-SXWLG3AINIW24QJC
So we find that for all traffic directed to this port, again a marker is set and the rule KUBE-SVC-SXWLG3AINIW24QJC applies. If you inspect this rule, you will find that it is similar to the rules above and again realizes a load balancer that sends traffic to port 80 of one of the pods.
Let us now verify that we can really reach this pod from the outside world. Of course, this only works once we have allowed incoming traffic on at least one of the nodes in the respective AWS security group. The following commands determine the node Port, your IP address, the security group and the IP address of the node, allow access and submit the curl command (note that I use the cluster name myCluster to select the worker nodes, in case you are not using my scripts to run this example, you will have to change the filter to make this work).
$ nodePort=$(kubectl get svc alpine-service --output json | jq ".spec.ports[0].nodePort") $ IP=$(aws ec2 describe-instances --filters Name=tag-key,Values=kubernetes.io/cluster/myCluster Name=instance-state-name,Values=running --output text --query Reservations[0].Instances[0].PublicIpAddress) $ SEC_GROUP_ID=$(aws ec2 describe-instances --filters Name=tag-key,Values=kubernetes.io/cluster/myCluster Name=instance-state-name,Values=running --output text --query Reservations[0].Instances[0].SecurityGroups[0].GroupId) $ myIP=$(wget -q -O- https://ipecho.net/plain) $ aws ec2 authorize-security-group-ingress --group-id $SEC_GROUP_ID --port $nodePort --protocol tcp --cidr "$myIP/32" $ curl $IP:$nodePort <h1>It works!</h1>
Summary
After all these nitty-gritty details, let us summarize what we have found. When you start a pod on a node, a pair of virtual ethernet devices is created, with one end being assigned to the namespace of the container and one end being assigned to the namespace of the host. Then IP routes are added so that traffic directed towards the pod is forwarded to this bridge. This allows access to the container from the node on which they are running. To realize access from other nodes and pods and thus the flat Kubernetes networking model, EKS uses the AWS CNI plugin which attaches the pods IP addresses as secondary IP addresses to elastic network interfaces.
When you start a service, Kubernetes will in addition set up NAT rules that will capture traffic determined for the cluster IP address of the service and perform a destination network address translation so that this traffic gets send to one of the pods. The pod is selected at random, which implements a simple load balancer. For a service of type NodePort, additional rules will be created which make sure that the same NAT processing applies to traffic coming from the outside world.
This completes today post. If you want to learn more, you might want to check out some of the links below.
- this post by Kevin Sookocheff
- the source code of the iptable interface of the kube proxy
- The proposal for the AWS CNI plugin
- my own series on networking in Docker (part I, part II)
- and of course the Kubernetes documention itself

2 Comments