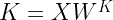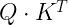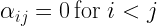Ultimately, VertexAI is about the processing of data. In previous posts in this series, we have placed our data in a GCS bucket and referenced it within our pipelines directly by the URI – you could call this a self-managed dataset. Alternatively, VertexAI also allows you to defined managed datasets which are stored in a central registry, a feature which we will explore today.
Tabular datasets
The first thing that you have to understand when working with VertexAI datasets is that they come in different flavours called types and objectives in the VertexAI console. The type is more than an attribute, and we will see that for instance tabular datasets which we will look at first behave fundamentally different from other types of datasets like text datasets.
To get started, let us create a small tabular dataset with sample data. I have added a simple script to my repository for this series that will build a small dataset in CSV format with two columns, populated with random data. Run the script
python3 datasets/create_csv.py
and upload the resulting file data.csv to the GCS bucket that you should have created as part of the initial setup for this series.
gsutil cp \
data.csv \
gs://vertex-ai-$GOOGLE_PROJECT_ID/datasets/my-dataset.csv
Now we can import this dataset into the VertexAI data registry. For that purpose, open the Google cloud console and use the navigation bar at the left to visit “Vertex AI – Datasets”. Make sure to select the region that you are using and click on “Create dataset”. You should see a screen similar to the one below.

Enter “my-dataset” as dataset name at the top, then select “Tabular” and “Regression / classification”. Click on “Create”.
You will now be taken to a screen that gives you different options to actually import data into your newly created dataset. Select the CVS file that we have just uploaded to GCS as a GCS source.

If you now hit “Continue”, Google will link the URI of your CSV file to the dataset. Note that in that sense, a tabular dataset is more or less a reference to a physical dataset located somewhere in a GCS bucket. Vertex AI does not create a copy, so if you modify the CSV file, this will modify the dataset.
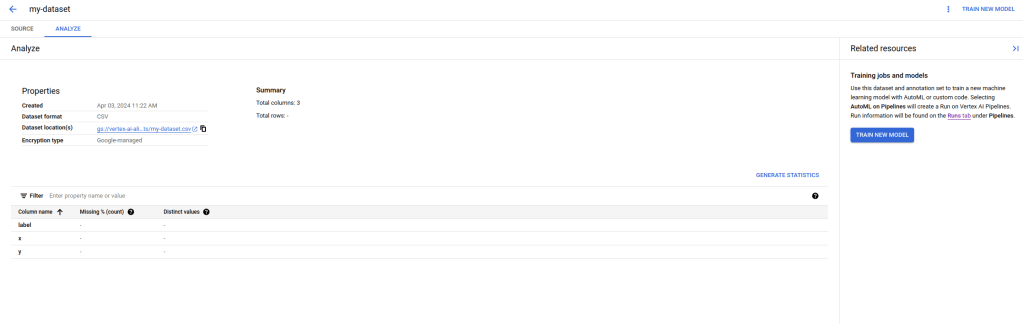
You now have several options to proceed. You can follow the link displayed on the right hand side to use Vertex AIs AutoML feature which will train a regression model on your data from scratch (be careful, there is an extra charge associated with that which goes far beyond the cost for the actual compute capacity needed, so do not do this if you just want to play). You can also analyze the data by clicking on the link “Generate statistics”.
Be patient, even for our tiny sample with 2000 items, this will take some time – when I tried this, it took about ten minutes. As a result, you will get the count of distinct values per column, and Vertex AI would also inform you about any missing values.
Let us now try to collect a bit more information on our dataset by using the Python API. The high-level API defines APIs which are specific for a given dataset type, but there is also an API that we can use to get information for an arbitrary dataset. Our repository contains an example that demonstrates how to use this in datasets/get_dataset.py. Let us run this.
python3 datasets/get_dataset.py
If you look at the output, you will find that it references a metadata schema that is in fact specific to the type of dataset that we have defined. The metadata schema is the URI of a file on GCS, and you can of course use gsutil to download a copy of this.
gsutil cp gs://google-cloud-aiplatform/schema/dataset/metadata/tabular_1.0.0.yaml .
more tabular_1.0.0.yaml
From this description, you will learn that a tabular dataset is really only a pointer to the data that is contains, which can either be stored in one or more files on GCS or in a BigQuery table. In addition to this, Google will only store some metadata like the creation time and a unique ID. Google will, however, add a metadata item to the metadata store that also references the dataset.
Text datasets
Let us now turn to a slightly more interesting type of datasets – text datasets. The basic workflow for text datasets is the same as for tabular datasets – we create the dataset (either via the SDK or on the console) and upload data. However, the format of the data is different – data is usually imported in JSON format that follows a specific schema which depends on the classification task. Let us use sentiment analysis as an example for which the schema is available here. Essentially, each item in our data (called a document) would be represented by a JSON object that looks as follows.
{
"textContent" : "the actual text",
"sentimentAnnotation": {
"sentiment": 1,
"sentimentMax": 2
},
}
Here, the textContent is the actual data. The content of sentimentAnnotation – if present – contains the label, which consists of a score between 0 and maximal 10, and the sentimentMax value that specifies the maximum value (and should be the same for all documents in the set).
Instead of including the text content directly, the field textContent can also be replaced by a field textGcsUri which is the URI of a file stored on GCS, so that every record is represented by one file. Also note that only each line is valid JSON, while the full document is not – this is why the format is called JSON lines and has extension *.jsonl.
To try this, we again need a small sample dataset. As this is a series on Vertex AI, I could not resist the temptation to write a small script which asks Googles Gemini Pro model to do this for us. It uses few-shot learning to get a batch of ten records from the LLM, validates the content to see that it is valid, and repeats this until we have collected 100 valid documents which are then written to a file text.jsonl. You can either run this yourself
python3 datasets/generate_text_data.py
or use the file that I have included in the repository
cp datasets/text.jsonl .
In any case, we will again have to copy the file that you want to use to a GCS bucket as we did it before for the tabular dataset.
gsutil cp \
text.jsonl \
gs://vertex-ai-$GOOGLE_PROJECT_ID/datasets/text.jsonl
Once the upload is complete, you can create a dataset using the same workflow as for our tabular dataset, with the difference that you will have to select a text dataset with the objective sentiment analysis. Also note that you will have to specify the minimum and maximum sentiment score (0 and 2 in our case) and you will have to use a location that supports this feature which is not yet available in all locations. Let us call our dataset “text-dataset”.
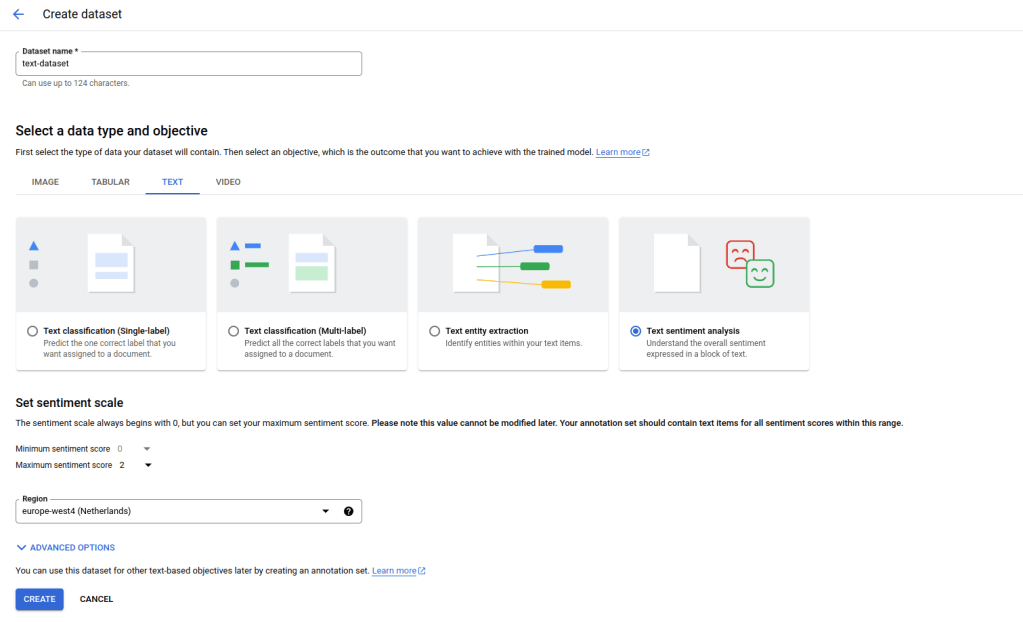
Then proceed with the import as before by selecting the GCS location of the text.jsonl file that we have uploaded earlier. Again, the import takes some time. Note that the test data set that is included in the repository does actually contain duplicates, so when the import completes, you will only see 98 records, not 100 – this nicely demonstrates that Google does some work behind the scenes while you are waiting.
Let us now take a closer look at our dataset by running the script again that we have already used to display our tabular dataset, specifying the name and region of our new dataset – be sure to use the same region here as the one that you have selected when creating the dataset.
python3 datasets/get_dataset.py \
--dataset=text-dataset \
--region=europe-west4
If you compare this to the output for our tabular dataset, you should see two interesting differences. First, this dataset has a different schema reflecting the fact that this is a text dataset, not a tabular dataset. Second the GCS bucket that is displayed is not the bucket that we have used for the upload, but a bucket that Google has generated for us. This reflects the fact that this time, the data itself is managed by Google and is more than just a reference.
It is instructive to actually visit the GCS bucket that Google has generated (which will be owned by you, so you can actually see it). You will find that behind the scenes, Google has created one blob for every item in the input. This allows the platform to also modify each item separately, and in fact, in the console window for this dataset, you can edit individual items and add, remove or change labels.
Corresponding to this, you can also export your dataset, either directly from the console or programmatically using the export_data method of the DatasetServiceClient. Here, exporting means that the data will be written to a GCS location of your choice from where you can further process it – I would not recommend to directly use the bucket controlled by Google for this purpose as this is supposed to be managed by Google exclusively.
This closes our short series on Vertex AI. Of course, there are many features that we have not yet touched upon, like notebook and the workbench, batch predictions, feature stores or the new platform components with GenAI specific services like the model garden, LLMs and vector storage. However, with the basic understanding that you will have gained if you have followed me up to this point, you should be well prepared to explore these features as well.