
In my previous post, we have seen how we can use Kubernetes deployment objects to bring up a given number of pods running our Docker images in a cluster. However, most of the time, a pod by itself will not be able to operate – we need to connect it with other pods and the rest of the world, in other words we need to think about networking in Kubernetes.
To try this out, let us assume that you have a cluster up and running and that you have submitted a deployment of two httpd instances in the cluster. To easily get to this point, you can use the scripts in my GitHub repository as follows. These scripts will also open two ssh connections, one to each of the EC2 instances which are part of the cluster (this assumes that you are using a PEM file called eksNodeKey.pem as I have done it in my examples, if not you will have to adjust the script up.sh accordingly).
# Clone repository $ git clone https://github.com/christianb93/Kubernetes.git $ cd Kubernetes/cluster # Bring up cluster and two EC2 nodes $ chmod 700 up.sh $ ./up.sh # Bring down nginx controller $ kubectl delete svc ingress-nginx -n ingress-nginx # Deploy two instances of the httpd $ kubectl apply -f ../pods/deployment.yaml
Be patient, the creation of the cluster will take roughly 15 minutes, so time to get a cup of coffee. Note that we delete an object – the nginx ingress controller service – that my scripts generate and that we will use in a later post, but which blur the picture for today.
Now let us inspect our cluster and try out a few things. First, let us get the running pods.
$ kubectl get pods -o wide
This should give you two pods, both running an instance of the httpd. Typically, Kubernetes will distribute these two pods over two different nodes in the cluster. Each pod has an IP address called the pod IP address which is displayed in the column IP of the output. This is the IP address under which the pod is reachable from other pods in the cluster.
To verify this, let us attach to one of the pods and run curl to access the httpd running in the other pod. In my case, the first pod has IP address 192.168.232.210. We will attach to the second pod and verify that this address is reachable from there. To get a shell in the pod, we can use the kubectl exec command which executes code in a pod. The following commands extract the id of the second pod, opens a shell in this pod, installs curl and talks to the httpd in the first pod. Of course, you will have to replace the IP address of the first pod – 192.168.232.210 – with whatever your output gives you.
$ name=$(kubectl get pods --output json | \
jq -r ".items[1].metadata.name")
$ kubectl exec -it $name "/bin/bash"
bash-4.4# apk add curl
bash-4.4# curl 192.168.232.210
<h1>It works!</h1>
Nice. So we can reach a port on pod A from any other pod in the cluster. This is what is called the flat networking model in Kubernetes. In this model, each pod has a separate IP address. All containers in the pod share this IP address and one IP namespace. Every pod IP address is reachable from any other pod in the cluster without a need to set up a gateway or NAT. Coming back to the comparison of a pod with a logical host, this corresponds to a topology where all logical hosts are connected to the same IP network.
In addition, Kubernetes assumes that every node can reach every pod as well. You can easily confirm this – if you log into the node (not the pod!) on which the second pod is running and use curl from there, directed to the IP address of the first pod, you will get the same result.
Now Kubernetes is designed to run on a variety of platforms – locally, on a bare metal cluster, on GCP, AWS or Azure and so forth. Therefore, Kubernetes itself does not implement those rules, but leaves that to the underlying platform. To make this work, Kubernetes uses an interface called CNI (container networking interface) to talk to a plugin that is responsible for executing the platform specific part of the network configuration. On EKS, the AWS CNI plugin is used. We will get into the details in a later post, but for the time being simply assume that this works (and it does).
So now we can reach every pod from every other pod. This is nice, but there is an issue – a pod is volatile. An application which is composed of several microservices needs to be prepared for the event that a pod goes down and is brought up again, be it due to a failure or simply due to the fact that an auto-scaler tries to empty a node. If, however, a pod is restarted, it will typically receive a different IP address.
Suppose, for instance, you had a REST service that you want to expose within your cluster. You use a deployment to start three pods running the REST service, but which IP address should another service in the cluster use to access it? You cannot rely on the IP address of individual pods to be stable. What we need is a stable IP address which is reachable by all pods and which routes traffic to one instance of this REST service – a bit like a cluster-internal load balancer.
Fortunately, Kubernetes services come to the rescue. A service is a Kubernetes object that has a stable IP address and is associated with a set of pods. When traffic is received which is directed to the service IP address, the service will select one of the pods (at random) and forward the traffic to it. Thus a service is a decoupling layer between the instable pod IP addresses and the rst of the cluster or the outer world. We will later see that behind the scenes, a service is not a process running somewhere, but essentially a set of smart NAT and routing rules.
This sounds a bit abstract, so let us bring up a service. As usual, a service object is described in a manifest file.
apiVersion: v1
kind: Service
metadata:
name: alpine-service
spec:
selector:
app: alpine
ports:
- protocol: TCP
port: 8080
targetPort: 80
Let us call this file service.yaml (if you have cloned my repository, you already have a copy of this in the directory network). As usual, this manifest file has a header part and a specification section. The specification section contains a selector and a list of ports. Let us look at each of those in turn.
The selector plays a role similar to the selector in a deployment. It defines a set of pods that are assumed to be reachable via the service. In our case, we use the same selector as in the deployment, so that our service will send traffic to all pods brought up by this deployment.
The ports section defines the ports on which the service is listening and the ports to which traffic is routed. In our case, the service will listen for TCP traffic on port 8080, and will forward this traffic to port 80 on the associated pods (as specified by the selector). We could omit the targetPort field, in this case the target port would be equal to the port. We could also specify more than one combination of port and target port and we could use names instead of numbers for the ports – refer to the documentation for a full description of all configuration options.
Let us try this. Let us apply this manifest file and use kubectl get svc to list all known services.
$ kubectl apply -f service.yaml $ kubectl get svc
You should now see a new service in the output, called alpine-service. Similar to a pod, this service has a cluster IP address assigned to it, and a port number (8080). In my case, this cluster IP address is 10.100.234.120. We can now again get a shell in one of the pods and try to curl that address
$ name=$(kubectl get pods --output json | \
jq -r ".items[1].metadata.name")
$ kubectl exec -it $name "/bin/bash"
bash-4.4# apk add curl # might not be needed
bash-4.4# curl 10.100.234.120:8080
<h1>It works!</h1>
If you are lucky and your container did not go down in the meantime, curl will already be installed and you can skip the apk add curl. So this works, we can actually reach the service from within our cluster. Note that we now have to use port 8080, as our service is listening on this port, not on port 80.
You might ask how we can get the IP address of the service in real world? Well, fortunately Kubernetes does a bit more – it adds a DNS record for the service! So within the pod, the following will work
bash-4.4# curl alpine-service:8080 <h1>It works!</h1>
So once you have the service name, you can reach the httpd from every pod within the cluster.
Connecting to services using port forwarding
Having a service which is reachable within a cluster is nice, but what options do we have to reach a cluster from the outside world? For a quick and dirty test, maybe the easiest way is using the kubectl port forwarding feature. This command allows you to forward traffic from a local port on your development machine to a port in the cluster which can be a service, but also a pod. In our case, let us forward traffic from the local port 5000 to port 8080 of our service (which is hooked up to port 80 on our pods).
$ kubectl port-forward service/alpine-service 5000:8080
This will start an instance of kubectl which will bind to port 5000 on your local machine (127.0.0.1). You can now connect to this port, and behind the scenes, kubectl will tunnel the traffic through the Kubernetes master node into the cluster (you need to run this in a second terminal, as the kubectl process just started is still blocking your terminal).
$ curl localhost:5000 <h1>It works!</h1>
A similar forwarding can be realized using kubectl proxy, which is designed to give you access to the Kubernetes API from your local machine, but can also be used to access services.
Connect to a service using host ports
Forwarding is easy and a quick solution, but most likely not what you want to do in a production setup. What other options do we have?
One approach is to use host ports. Essentially, a host port is a port on a node that Kubernetes will wire up with the cluster IP address of a service. Assuming that you can reach the host from the outside world, you can then use the public IP address of the host to connect to a service.
To create a host port, we have to modify our manifest file slightly by adding a host port specification.
apiVersion: v1
kind: Service
metadata:
name: alpine-service
spec:
selector:
app: alpine
ports:
- protocol: TCP
port: 8080
targetPort: 80
type: NodePort
Note the additional line at the bottom of the file which instructs Kubernetes to open a node port. Assuming that this file is called nodePortService.yaml, we can again use kubectl to bring down our existing service and add the node port service.
$ kubectl delete svc alpine-service $ kubectl apply -f nodePortService.yaml $ kubectl get svc
We see that Kubernetes has brought up our service, but this time, we see two ports in the line describing our service. The second port (32226 in my case) is the port that Kubernetes has opened on each node. Traffic to this port will be forwarded to the service IP address and port. To try this out, you can use the following commands to get the external IP address of the first node, adapt the AWS security group such that traffic to this node is allowed from your workstation, determine the node port and curl it. If your cluster is not called myCluster, replace every occurrence of myCluster with the name of your cluster.
$ nodePort=$(kubectl get svc alpine-service --output json | jq ".spec.ports[0].nodePort") $ IP=$(aws ec2 describe-instances --filters Name=tag-key,Values=kubernetes.io/cluster/myCluster Name=instance-state-name,Values=running --output text --query Reservations[0].Instances[0].PublicIpAddress) $ SEC_GROUP_ID=$(aws ec2 describe-instances --filters Name=tag-key,Values=kubernetes.io/cluster/myCluster Name=instance-state-name,Values=running --output text --query Reservations[0].Instances[0].SecurityGroups[0].GroupId) $ myIP=$(wget -q -O- https://ipecho.net/plain) $ aws ec2 authorize-security-group-ingress --group-id $SEC_GROUP_ID --port $nodePort --protocol tcp --cidr "$myIP/32" $ curl $IP:$nodePort <h1>It works!</h1>
Connecting to a service using a load balancer
A node port will allow you to connect to a service using the public IP of a node. However, if you do this, this node will be a single point of failure. For a HA setup, you would typically choose a different options – load balancers.
Load balancers are not managed directly by Kubernetes. Instead, Kubernetes will ask the underlying cloud provider to create a load balancer for you which is then connected to the service – so there might be additional charges. Creating a service exposed via a load balancer is easy – just change the type field in the manifest file to LoadBalancer
apiVersion: v1
kind: Service
metadata:
name: alpine-service
spec:
selector:
app: alpine
ports:
- protocol: TCP
port: 8080
targetPort: 80
type: LoadBalancer
After applying this manifest file, it takes a few seconds for the load balancer to be created. Once this has been done, you can find the external DNS name of the load balancer (which AWS will create for you) in the column EXTERNAL-IP of the output of kubectl get svc. Let us extract this name and curl it. This time, we use the jsonpath option of the kubectl command instead of jq.
$ host=$(kubectl get svc alpine-service --output \
jsonpath="{.status.loadBalancer.ingress[0].hostname}")
$ curl $host:8080
<h1>It works!</h1>
If you get a “couldn not resolve hostname” error, it might be that the DNS entry has not yet propagated through the infrastructure, this might take a few minutes.
What has happened? Behind the scenes, AWS has created an elastic load balancer (ELB) for you. Let us describe this load balancer.
$ aws elb describe-load-balancers --output json
{
"LoadBalancerDescriptions": [
{
"Policies": {
"OtherPolicies": [],
"LBCookieStickinessPolicies": [],
"AppCookieStickinessPolicies": []
},
"AvailabilityZones": [
"eu-central-1a",
"eu-central-1c",
"eu-central-1b"
],
"CanonicalHostedZoneName": "ad76890d448a411e99b2e06fc74c8c6e-2099085292.eu-central-1.elb.amazonaws.com",
"Subnets": [
"subnet-06088e09ce07546b9",
"subnet-0d88f92baecced563",
"subnet-0e4a8fd662faadab6"
],
"CreatedTime": "2019-03-17T11:07:41.580Z",
"SecurityGroups": [
"sg-055b253a63c7aba0a"
],
"Scheme": "internet-facing",
"VPCId": "vpc-060469b2a294de8bd",
"LoadBalancerName": "ad76890d448a411e99b2e06fc74c8c6e",
"HealthCheck": {
"UnhealthyThreshold": 6,
"Interval": 10,
"Target": "TCP:30829",
"HealthyThreshold": 2,
"Timeout": 5
},
"BackendServerDescriptions": [],
"Instances": [
{
"InstanceId": "i-0cf7439fd8eb65858"
},
{
"InstanceId": "i-0fda48856428b9a24"
}
],
"SourceSecurityGroup": {
"GroupName": "k8s-elb-ad76890d448a411e99b2e06fc74c8c6e",
"OwnerAlias": "979256113747"
},
"DNSName": "ad76890d448a411e99b2e06fc74c8c6e-2099085292.eu-central-1.elb.amazonaws.com",
"ListenerDescriptions": [
{
"PolicyNames": [],
"Listener": {
"InstancePort": 30829,
"LoadBalancerPort": 8080,
"Protocol": "TCP",
"InstanceProtocol": "TCP"
}
}
],
"CanonicalHostedZoneNameID": "Z215JYRZR1TBD5"
}
]
}
This is a long output, let us see what this tells us. First, there is a list of instances, which are the instances of the nodes in your cluster. Then, there is the block ListenerDescriptions. This block specificies, among other things, the load balancer port (8080 in our case, this is the port that the load balancer exposes) and the instance port (30829). You will note that these are also the ports that kubectl get svc will give you. So the load balancer will send incoming traffic on port 8080 to port 30829 of one of the instances. This in turn is a host port as discussed before, and therefore will be connected to our service. Thus, even though technically not fully correct, the following picture emerges (technically, a service is not a process, but a collection of iptables rules on each node, which we will look at in more detail in a later post).
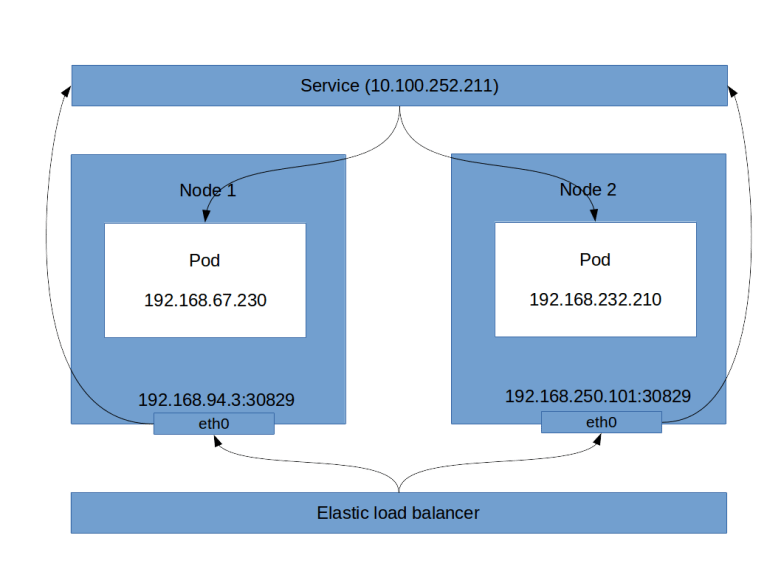
Using load balancers, however, has a couple of disadvantages, the most obvious one being that each load balancer comes with a cost. If you have an application that exposes tens or even hundreds of services, you clearly do not want to fire up a load balancer for each of them. This is where an ingress comes into play, which can distribute incoming HTTP(S) traffic across various services and which we will study in one of the next posts.
There is one important point when working with load balancer services – do not forget to delete the service when you are done! Otherwise, the load balancer will continue to run and create charges, even if it is not used. So delete all services before shutting down your cluster and if in doubt, use aws elb describe-load-balancers to check for orphaned load balancers.
Creating services in Python
Let us close this post by looking into how services can be provisioned in Python. First, we need to create a service object and populate its metadata. This is done using the following code snippet.
service = client.V1Service() service.api_version = "v1" service.kind = "Service" metadata = client.V1ObjectMeta(name="alpine-service") service.metadata = metadata service.type="LoadBalancer"
Now we assemble the service specification and attach it to the service object.
spec = client.V1ServiceSpec()
selector = {"app": "alpine"}
spec.selector = selector
spec.type="LoadBalancer"
port = client.V1ServicePort(
port = 8080,
protocol = "TCP",
target_port = 80 )
spec.ports = [port]
service.spec = spec
Finally, we authenticate, create an API endpoint and submit the creation request.
config.load_kube_config()
api = client.CoreV1Api()
api.create_namespaced_service(
namespace="default",
body=service)
If you have cloned my GitHub repository, you will find a script network/create_service.py that contains the full code for this and that you can run to try this out (do not forget to delete the existing service before running this).

1 Comment