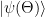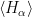Do usable universal quantum computers exist today? If you follow the recent press releases, you might believe that the answer is “yes”, with IBM announcing a 50 qubit quantum computer and Google promoting its Bristlecone architecture with up to 72 qubits. Unfortunately, the world is more complicated than this – time to demystify the hype a bit.
The need for error correction
The important point is that it is not just the number of qubits that matters, but also their quality. When we study quantum algorithms like Shor’s algorithm, we are working with idealized qubits that behave exactly the way an isolated two-state quantum system is supposed to behave – these idealized qubits are often called logical qubits. However, in a real world implementation, there is no fully isolated two-state quantum system. Every system interacts to some extent with the environment, an interaction that we can try to reduce to a minimum, for instance by cooling our device down to very low temperatures, but never fully avoid. A trapped ion could, for instance, interact with radiation entering our device from the environment, and suddenly is part of a larger quantum system, consisting of the ion, the photons making up the radiation and maybe even the source of the photon. This will introduce errors into our system, i.e. deviations of the behavior of the system from the idealized theoretical model.
In addition to unwanted interactions with the environment, other errors could creep into our computation. When manipulating qubits to realize gates, we might make mistakes, for instance by directing a microwave pulse with a slightly incorrect frequency at our qubit, and we can make mistakes during each measurement.
Thus the real qubits in a quantum computer – called physical qubits – are prone to errors. These errors might be small for one qubit, but they tend to propagate through the circuit and add up to a significant error that will render the result of our quantum computation unusable. Thus we need error correction, i.e. the ability to detect and correct errors during our computation.
So how would you do this? Of course, errors can also occur in classical systems, and there are well developed methods to detect and correct them. Unfortunately, these approaches typically rely on the ability to copy and measure individual bits. This is easy for a classical bit, but more complicated for a qubit, as a measurement will collapse our system into an eigenstate of the observed operator and thus interfere with quantum algorithm.
The good news is that quantum error correction is still possible. In this post, I will try to explain the basics, before we then dive into more advanced topics in the next few posts.
Encoding logical states
In order to understand the basic ideas and structures behind quantum error correction, it is useful to study a simplified example – the three qubit code. To introduce this code, let us suppose that we have access to a communication channel across which we can send individual qubits from one quantum device to another one. Suppose further that this transmission is not perfect, but is subject to a bit flip error with a probability p. Thus, with probability p, a one-qubit state 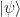 will be changed to
will be changed to  during transmission, where
during transmission, where  is the usual bit flip operator, and with probability 1-p, the transmission does not change the state. The aim is to construct an encoding of a qubit such that these errors can be detected and corrected.
is the usual bit flip operator, and with probability 1-p, the transmission does not change the state. The aim is to construct an encoding of a qubit such that these errors can be detected and corrected.
To achieve this, we encode every single qubit state in a three-qubit state before transmitting it. Thus we use the following encoding
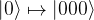
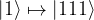
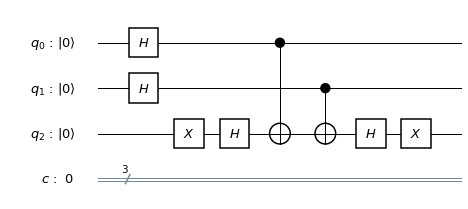
It is not difficult to see that this encoding can in fact be realized by a unitary circuit – the circuit below will do the trick.
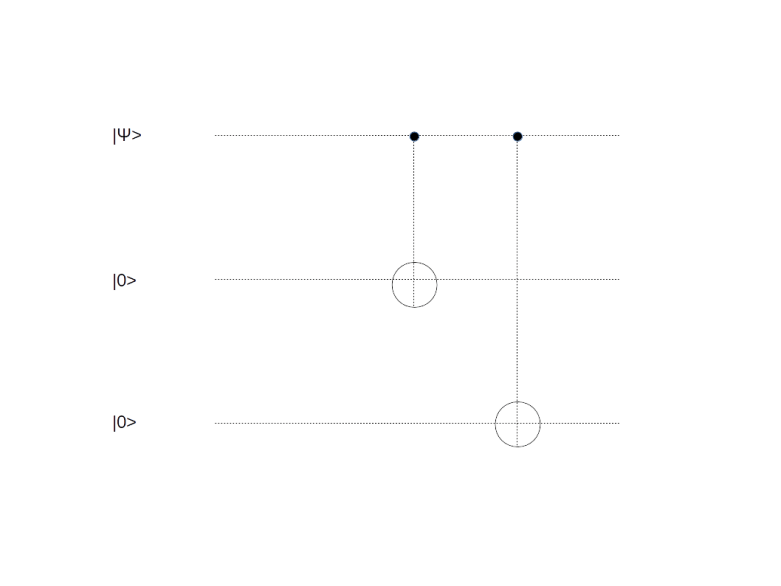
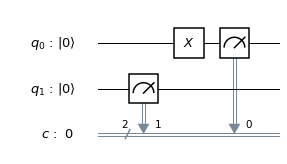
To transmit one qubit, we use this encoding to obtain a three-qubit message. We then send those three qubits through our communication channel. After the transmission, we apply a procedure known as syndrome measurement, using the following circuit.
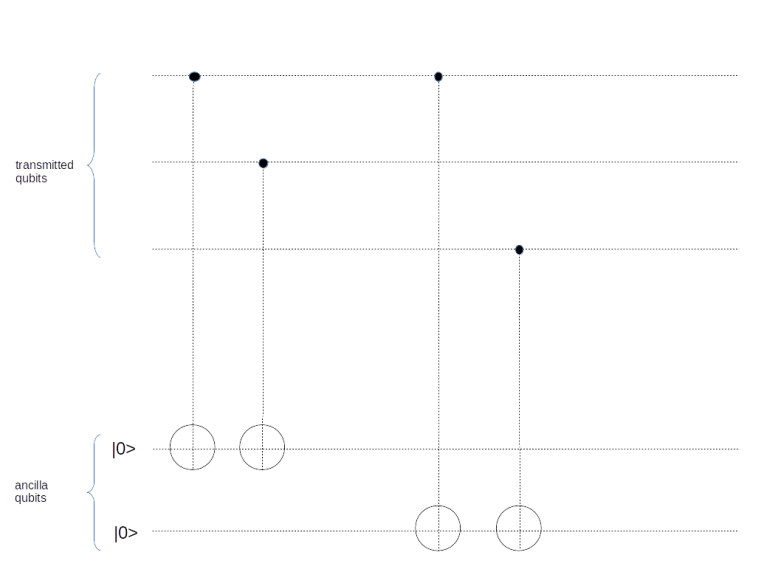
Let us see what this circuit is doing. First, let us suppose that the original qubit was 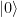 , encoded as
, encoded as  , and no error did occur during the transmission. Then the three qubits at the top of the circuit will still be . In this case, the CNOT gates act as the identity, and the overall state after passing the circuit is
, and no error did occur during the transmission. Then the three qubits at the top of the circuit will still be . In this case, the CNOT gates act as the identity, and the overall state after passing the circuit is
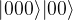
Similarly, if the original qubit is 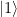 and no error occurred, all CNOT gates will act as inversion. Thus the ancilla qubits will be inverted twice, and we end up with the state
and no error occurred, all CNOT gates will act as inversion. Thus the ancilla qubits will be inverted twice, and we end up with the state

The situation is a bit different if a bit flip error has affected one of the qubits during the transmission, say the first one. Suppose the original state was again . After encoding and transmission with a bit flip on the first qubit, we will receive the state  . Therefore both ancilla qubits will be inverted, and we obtain the state
. Therefore both ancilla qubits will be inverted, and we obtain the state

Let us now generalize these considerations. Assume that we are encoding the state  , so that the encoded state will be
, so that the encoded state will be  . When we go through the above exercise for all possible cases, we arrive at the following table that shows the transmission error and the resulting state after passing the syndrome measurement circuit.
. When we go through the above exercise for all possible cases, we arrive at the following table that shows the transmission error and the resulting state after passing the syndrome measurement circuit.
| Error |
Resulting state |
| No error |

|
| Bit flip on first qubit |
 |
| Bit flip on second qubit |
 |
| Bit flip on third qubit |
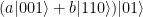 |
Now let us see what happens if we measure the ancilla qubits. First, note that all the states are already eigenstates for the corresponding measurement operator. Thus measuring the ancilla qubits will not change the state of the first three qubits and it will not reveal any information on the encoded state. The second important observation is that the value of the ancilla qubits tells us the exact error that has occurred. Thus we have found a way to not only find out that an error has occurred without destroying our superposition, but also to figure out which qubit was flipped. Given that information, we can now apply a bit flip operator once more to the affected qubit to correct the error. Again, this will not reveal the values of a and b and not collapse our state, and we can therefore continue to work with the encoded quantum state, for instance by running it through the inverse of the encoding circuit to get our original state back.
More general error models
So what we have found so far is that it is possible, also in the quantum world, to detect and protect against pure bit flip errors without destroying the superposition. But there is more we can learn from that example. In fact, let us revisit our original assumption that the only thing that can go wrong is that the operator X is applied to some of the qubits and allow a more general operator. Suppose, for instance, that our error is represented by applying to at most one of our qubits the operator
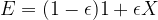
for a small  . In contrast to our earlier assumption that the error operator is discrete, i.e. is either applied or not applied, this operator is now continuous, depending on the parameter
. In contrast to our earlier assumption that the error operator is discrete, i.e. is either applied or not applied, this operator is now continuous, depending on the parameter  , i.e. it looks as if we had to deal with a full continuous spectrum of errors. A short calculation shows that after transmitting and applying the syndrome measurement circuit above, the state of our quantum system will now be
, i.e. it looks as if we had to deal with a full continuous spectrum of errors. A short calculation shows that after transmitting and applying the syndrome measurement circuit above, the state of our quantum system will now be
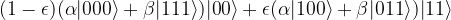
Now let us again apply a measurement of the ancilla qubits. Then, according to the laws of quantum mechanics, the system will collapse onto an eigenstate, i.e. it will – up to normalization – end up in one of the states

and

But these are exactly the states in which we end up if no error occurs or a single bit flip error occurs. Thus, our measurement forces the system to somehow decide whether an error occurred or not and if yes, which error occurred – we are opening the box in which Schrödingers cat is hidden. This is a very important observation often referred to as the digitization of errors – it suffices to protect against discrete errors as the syndrome measurement will collapse any superposition of different errors states.
So far we have worked with a code which is able to protect against a bit flip error. But of course this is not the only type of error that can occur. At the first glance, it looks like there is a vast universe of potential errors that we have to account for, as in theory, the error could be any unitary operator. However, using arguments similar to the discussion in the last paragraph, one can show that it suffices to protect against two types of errors: the bit flip error discussed above and the phase flip error, represented by the matrix
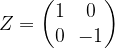
Note that the phase flip error has no classical equivalent, other than the bit flip error which can classically be interpreted as a bit flipping from one to zero or vice versa randomly. The first error correction code that was able to handle both, bit flip errors and phase flip errors (and combinations thereof, ), and therefore any possible type of error (as long as the number of errors is limited) was described in 1995 by P. Shor. This code uses nine qubits to encode one logical qubit and is somehow a repeated application of the three bit code, based on the observation that the Hadamard transform turns a bit flip error into a phase flip error and vice versa. Later, different types of codes were discovered that are also universal in the sense that they protect against any potential one qubit error, i.e. against any error that only affects one qubit.
Let us now look at the structure that these codes have in common. First, the encoding can be described as identifying a 2-dimensional subspace C, called the code space, in the larger space spanned by all qubits. In the case of the three qubit code, the code space is spanned by the states and  , corresponding to a logical zero and a logical one. More generally, the space C can have dimension 2n and the full Hilbert space can have dimension 2k, in which case we can encode n qubits in a larger set of k qubits (in the nine qubit code example, k = 9 and n = 1).
, corresponding to a logical zero and a logical one. More generally, the space C can have dimension 2n and the full Hilbert space can have dimension 2k, in which case we can encode n qubits in a larger set of k qubits (in the nine qubit code example, k = 9 and n = 1).
Hence the code space is spanned by a set of 2n basis vectors 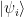 that we call code words. In the case n = 1, it is common practice to denote the codewords by
that we call code words. In the case n = 1, it is common practice to denote the codewords by  and
and 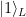 to indicate that they represent a logical qubit encoded using k physical qubits.
to indicate that they represent a logical qubit encoded using k physical qubits.
In addition, there is a set of error operators, i.e. a finite set of operators  like the phase flip or bit flip operators acting on the larger Hilbert space. These operators represent the impact of discretized noise and will generally move the code words out of the code space, i.e. they will rotate the code space onto different subspaces of the entire Hilbert space.
like the phase flip or bit flip operators acting on the larger Hilbert space. These operators represent the impact of discretized noise and will generally move the code words out of the code space, i.e. they will rotate the code space onto different subspaces of the entire Hilbert space.

In order for a code to be useful, we of course need a relation between code space and errors that tells us that the errors can be detected and corrected. What are these conditions? A first condition is that no matter which errors occur, we can still tell the code words apart. This is guaranteed if the various error operators map different code words onto mutually orthogonal subspaces, in other words if
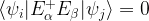
whenever 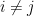 and for all
and for all  . Thus, even in the presence of errors, the different code words will never overlap.
. Thus, even in the presence of errors, the different code words will never overlap.
What about the case that both code words are the same? It is tempting to ask for the condition

i.e. to require that different errors map the same codeword to orthogonal subspaces. This would make recovery very easy. We could perform the measurements that correspond to projections onto these subspaces to detect the error and correct them by applying the inverse of the error operator. However, this condition is too restrictive. In the case of the nine qubit code, for example, it might very well happen that two different errors map a code word to the same state. However, the same applies for the correction, i.e. we do not have to distinguish between these two errors as the act similarly on the code space. Therefore, a more general condition is usually used which captures this case:

for a hermitian matrix 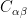 . If the matrix has full rank, the code is called non-degenerate, otherwise – as in the case of the nine qubit code – the code is called degenerate.
. If the matrix has full rank, the code is called non-degenerate, otherwise – as in the case of the nine qubit code – the code is called degenerate.
Of course this encoding generates some overhead. To represent one logical qubit, we need more than one physical qubit. For the Shor code, we have to use nine physical qubits to encode one logical qubit. It is natural to ask what the minimum overhead is that we need. In 1996, Steane discovered a code that requires only seven physical qubits. In the same year, a code that requires only five qubits was presented and it was shown that this is a lower bound, i.e. there is no error correction code that requires less than five qubits.
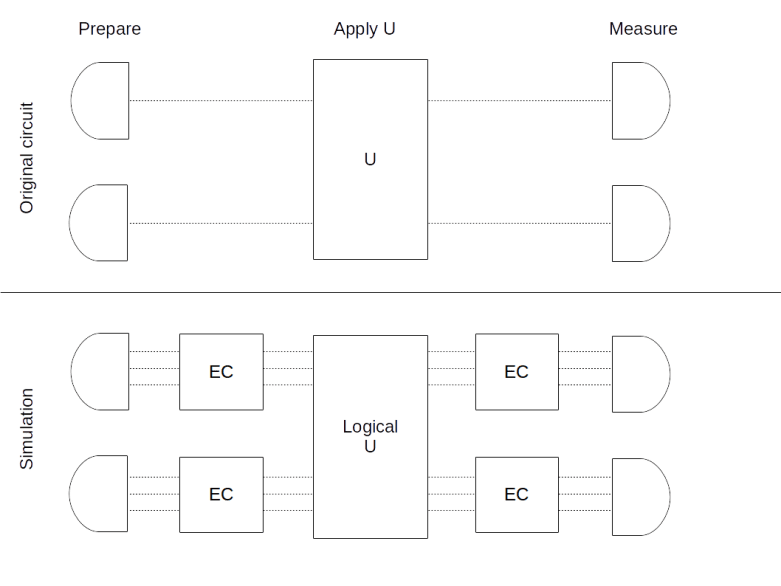
So there is an unavoidable overhead – and the situation is even worse. To implement error correction, you need again quantum gates, which can of course also experience errors. Thus you need additional circuitry to protect the error correction against errors, which can again introduce errors and so forth. That there is a way out of this vicious circle is not obvious and the content of the famous threshold theorem that we will study in a later post – but even this way out is very hard to implement and might require thousands of physical qubits to implement one single logical qubit.
So even with a 72 qubit device, we are still far away from implementing only one logical qubit – and having a few thousand logical qubits to use Short’s algorithm to break an RSA key with a realistic key length is yet another story. So it is probably a good idea to take claims about universal supremacy of quantum computing within a few years with a grain of salt.
In this post, we have looked at some of the essential ideas behind quantum error correction, i.e. the ability to detect and correct errors. However, this is not enough to build a reliable quantum computer – after all, adding an error correction circuit introduces additional qubits that can also create new errors. In addition, we need to be able to perform calculations on our encoded states. So there is more that we need for fault-tolerant quantum computing which is the topic of the next post.

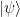

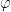
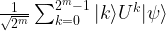

![U^k = \prod_i \big[ U^{2^i} \big]^{k_i}](https://s0.wp.com/latex.php?latex=U%5Ek+%3D+%5Cprod_i+%5Cbig%5B+U%5E%7B2%5Ei%7D+%5Cbig%5D%5E%7Bk_i%7D++&bg=FFFFFF&fg=000&s=1&c=20201002)
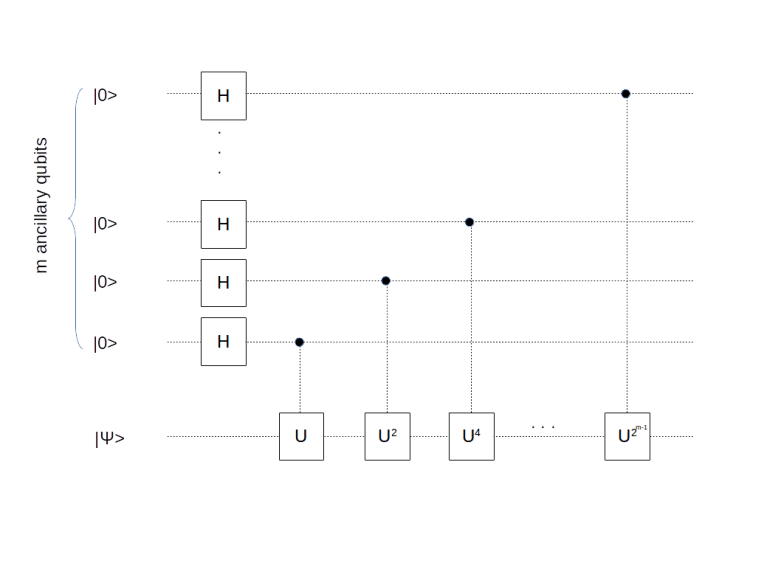
![\frac{1}{\sqrt{2^m}} \sum_{k=0}^{2^m - 1} |k \rangle U^k |\psi \rangle = \frac{1}{\sqrt{2^m}} \big[\sum_{k=0}^{2^m - 1} e^{2\pi i \varphi k} |k \rangle \big] \otimes |\psi \rangle](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B%5Csqrt%7B2%5Em%7D%7D+%5Csum_%7Bk%3D0%7D%5E%7B2%5Em+-+1%7D+%7Ck+%5Crangle+U%5Ek+%7C%5Cpsi+%5Crangle+%3D++%5Cfrac%7B1%7D%7B%5Csqrt%7B2%5Em%7D%7D+%5Cbig%5B%5Csum_%7Bk%3D0%7D%5E%7B2%5Em+-+1%7D+e%5E%7B2%5Cpi+i+%5Cvarphi+k%7D+%7Ck+%5Crangle+%5Cbig%5D+%5Cotimes++%7C%5Cpsi+%5Crangle++&bg=FFFFFF&fg=000&s=1&c=20201002)
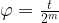
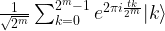

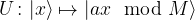

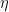 is an 2n-th root of unity with n being the number of qubits in the register, i.e.
is an 2n-th root of unity with n being the number of qubits in the register, i.e.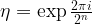
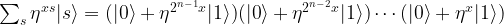


 plus a multiple of 2n. As
plus a multiple of 2n. As 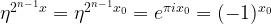






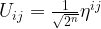
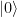 , at least up to a phase.
, at least up to a phase. 





 , so that our state is now
, so that our state is now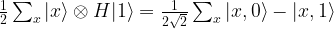



 . Clearly,
. Clearly,

 which is the same thing as the probability to measure
which is the same thing as the probability to measure  when we perform a measurement in the computational basis. Thus we finally obtain the following circuit
when we perform a measurement in the computational basis. Thus we finally obtain the following circuit











 called the Pauli group. Put differently, the Pauli group consists of those linear operators on the Hilbert space that can be written as a product
called the Pauli group. Put differently, the Pauli group consists of those linear operators on the Hilbert space that can be written as a product
 and an overall phase factor
and an overall phase factor 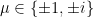 (we can even assume that all the
(we can even assume that all the 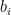 are equal to one as
are equal to one as  is a multiple of
is a multiple of  ). Any two elements of the Pauli group either commute or anti-commute. Within this group, we now consider a finite set
). Any two elements of the Pauli group either commute or anti-commute. Within this group, we now consider a finite set  of commuting elements and the subgroup S of the Pauli group generated by this set. This group (which is abelian as it is generated by mutually commuting elements) is called the stabilizer group. To this group, we can associate the subspace that consists of all vectors that are fixed by all elements of the group, i.e. the space
of commuting elements and the subgroup S of the Pauli group generated by this set. This group (which is abelian as it is generated by mutually commuting elements) is called the stabilizer group. To this group, we can associate the subspace that consists of all vectors that are fixed by all elements of the group, i.e. the space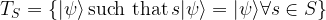
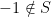 – you might want to take a look at
– you might want to take a look at 
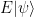 is now in the -1 eigenspace of s. Thus if we measure all elements of S, the outcome -1 for one of the measurements will tell us that an error has occurred. A similar argument shows that if the product of any two errors anti-commutes with at least one element of S, then we can also correct the error based on only the measurement results of elements in S. Mathematically speaking, the set of all elements of the Pauli group that commute with all elements of S is the centralizer of S, which in this case turns out to be equal to the normalizer N(S) of S, and a set
is now in the -1 eigenspace of s. Thus if we measure all elements of S, the outcome -1 for one of the measurements will tell us that an error has occurred. A similar argument shows that if the product of any two errors anti-commutes with at least one element of S, then we can also correct the error based on only the measurement results of elements in S. Mathematically speaking, the set of all elements of the Pauli group that commute with all elements of S is the centralizer of S, which in this case turns out to be equal to the normalizer N(S) of S, and a set  of errors can be detected and corrected if and only if
of errors can be detected and corrected if and only if
 . So the elements of the Pauli group that are neither in S nor in N(S) correspond to correctable errors.
. So the elements of the Pauli group that are neither in S nor in N(S) correspond to correctable errors.
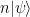 is again fixed by all elements of S and therefore in the code space TS. Thus the elements of N(S) generate automorphisms of the code space, i.e. logical operations. It is one of the strengths of the stabilizer formalism that once we have the stabilizer group S, we can not only derive the code space and the correctable errors, but can also use group theoretic considerations to describe logical operations – this will become clearer as we study surface codes in a later post.
is again fixed by all elements of S and therefore in the code space TS. Thus the elements of N(S) generate automorphisms of the code space, i.e. logical operations. It is one of the strengths of the stabilizer formalism that once we have the stabilizer group S, we can not only derive the code space and the correctable errors, but can also use group theoretic considerations to describe logical operations – this will become clearer as we study surface codes in a later post.

 . Thus our circuit does in fact implement a CNOT gate on the logical level.
. Thus our circuit does in fact implement a CNOT gate on the logical level.








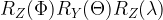

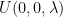 is a rotation around the z-axis and so forth. A short calculation shows that
is a rotation around the z-axis and so forth. A short calculation shows that




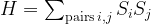






 and the vectors as linear combinations of tensor products to show that each hermitian operator is a linear combination of tensor products of hermitian single-qubit operators, and then use the fact that each hermitian single qubit operator is a linear combination of Pauli matrices). A tensor product of Pauli matrices corresponds to a measurement that can be easily implemented by a combination of a measurement in the standard computational basis and a unitary transformation, see for instance
and the vectors as linear combinations of tensor products to show that each hermitian operator is a linear combination of tensor products of hermitian single-qubit operators, and then use the fact that each hermitian single qubit operator is a linear combination of Pauli matrices). A tensor product of Pauli matrices corresponds to a measurement that can be easily implemented by a combination of a measurement in the standard computational basis and a unitary transformation, see for instance 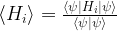
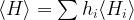
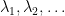 . Let us order the eigenvalues (which are of course real) such that
. Let us order the eigenvalues (which are of course real) such that  , and let us assume that
, and let us assume that  is an orthonormal basis of corresponding eigenvectors.
is an orthonormal basis of corresponding eigenvectors.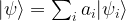
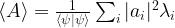
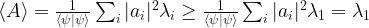
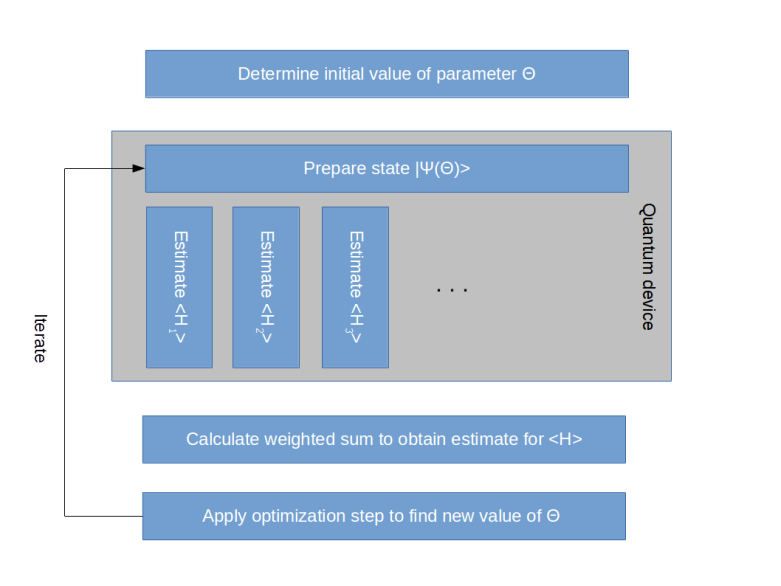
 . Thus finding an eigenvector for the lowest eigenvalue of A is equivalent to minizing the expectation value of A!
. Thus finding an eigenvector for the lowest eigenvalue of A is equivalent to minizing the expectation value of A! where the parameter
where the parameter 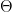 ranges over some subset of a finite dimensional euclidian space. One then tries to minimize the expectation value
ranges over some subset of a finite dimensional euclidian space. One then tries to minimize the expectation value
 , then determine the expectation value, adjust the parameter, determine the next expectation value and so forth. Unfortunately, calculating the expectation value of a matrix in a high dimensional Hilbert space is computationally very hard, which makes this algorithm difficult to apply to quantum systems with more than a few particles.
, then determine the expectation value, adjust the parameter, determine the next expectation value and so forth. Unfortunately, calculating the expectation value of a matrix in a high dimensional Hilbert space is computationally very hard, which makes this algorithm difficult to apply to quantum systems with more than a few particles. where the expectation value of each
where the expectation value of each  can be efficiently determined
can be efficiently determined