
Today we will take a closer look at the Ethereum blockchain and discuss its most important structures, namely transactions, blocks and state. I assume that you are familiar with the basics of the blockchain technology, if not, I suggest that you read a few of my earlier posts on blocks, transactions and mining. This will be a long post, we will go a bit deeper than the usual introductions that you might have seen. As a consequence, this post is a bit more theoretical, we will get to more practical exercises soon once we have mastered the basics.
A short history of the Ethereum blockchain
As of today, the real identity of Satoshi Nakamoto, the author of the bitcoin white paper, is unknown, even though different people have claimed to be Satoshi over time. The origin of the Ethereum blockchain is far less mysterious. In fact, the Ethereum white paper that defines the basic structures and ideas of the Ethereum blockchain, was published in 2013 by Vitalik Buterin. Subsequently, its formal specification, known as yellow paper and working out the ideas presented in the white paper, was developed in 2014 (the initial commit on GitHub by Gavin Wood is from April 2014). The Ethereum foundation was established in the same year, and in 2015, the Ethereum network was launched with the creation of the first block, known as the genesis block.
Since then, Ethereum has been under constant development. Changes to the protocol are controlled by a formal process, based on EIPs (Ethereum improvement proposals). Several clients have been developed over time, like Geth in Go, OpenEthereum in Rust or the Hyperledger Besu client in Java.
At the time of writing, Ethereum is transitioning from a Proof-of-work consensus mechanism to a Proof-of-Stake (PoS) mechanism as part of the next major version of the protocol commonly referred to as Ethereum 2.0. With PoS, special nodes called validators are taking over the process of reaching consensus on the order of transactions by creating and validating new blocks. To become a validator, you have to invest a certain stake of digital currency that you lose if you misbehave. The intention of this change is to reduce the environmental footprint of the mining process, reduce transaction fees and – by supporting sharding – increase scalability. Even though the Beacon chain, which is the foundation for the new PoS approach, is already operational as of August 2021, the final transition will still take some time and is expected to happen at some point late in 2021 or early in 2022. As of today, the Rinkeby test network is already running a proof-of-authority (PoA) consensus algorithm known as clique, see EIP-255, but the final Ethereum 2.0 chain will be based on a protocol known as Casper (see for instance this paper or this paper on the Arxiv for more details on this)
Addresses and accounts
On a certain level, the Ethereum blockchain is conceptually very simple – there is, at any point in time, a state, describing among other things the balances of the participants in the network, there are transactions changing the state and there are blocks that group transactions for the purpose of achieving consensus on the order of transactions. And, of course, there are addresses and accounts that represent the participants in the network.
An account represents a (typically human) participant in the Ethereum network. Accounts are not stored in a central place, there is no such thing as “signing up” for an account. Instead, an account is simply a randomly generated public and private key pair, more precisely an ECDSA key pair with a 32 byte private key and a 64 byte public key (which, as always with ECDSA, can be derived from the private key). Everyone can create an account by simply creating such a key pair and use that account to build and submit transactions to the network. There is no central mechanism that makes sure that the same account is not used by two different actors, but given the length of the key (32 bytes, i.e. 256 bit) this is highly unlikely.
Associated with every account is the address, which is defined as the rightmost 160 bit (i.e. 20 bytes) of the hash value of the public key. Ethereum uses the Keccak hashing algorithm (which is not exactly what NIST has standardized as SHA3-256, but close to it). Again, theoretically two different public keys could produce the same address due to a collision, but in practice this possibility is mostly ignored, and the address is considered to be in a one-to-one relation to the key pair.
Actually, we have been cheating a bit at this point. The relation between accounts and addresses described above is only valid for accounts that are owned by (typically) human actors external to the blockchain. However, we have already learned that Ethereum offers the possibility to store and run smart contracts, i.e. pieces of code that execute on the blockchain. These contracts are represented by addresses as well, but there is no private key behind these addresses (and consequently, a smart contract can, by itself, not create and sign a transaction). To distinguish these two types of accounts, accounts that hold a key pair are sometimes called externally owned account (EOA), while addresses occupied by a smart contract are called contract accounts.
State
The Ethereum state is organized as key-value pairs, where the key is the address and the value is again a complex data structure which consists of the following fields.
- First, there is the nonce. The nonce is a counter that is increased with every transaction that originates from this address (i.e. account), and we get back to its role when discussing transactions below
- Then, there is a balance, which reflects the current amount of Ether (the native currency of the Ethereum blockchain) owned by the account
- Next, there is a field called code, which, if the account is a contract account, holds the bytecode of the smart contract
- Finally, there is a field called storage. This is again a set of key-value pairs that a smart contract can use as persistent storage – we will get to this when we learn more about smart contracts.
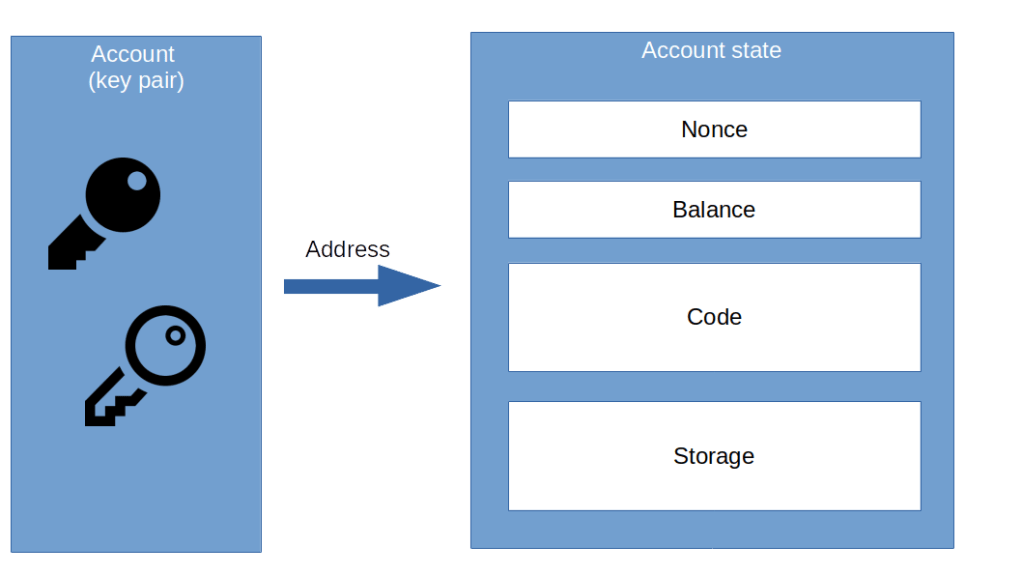
Technically, the state is not really stored in the blockchain. Instead, the blockchain contains the initial state (in block zero of the chain, i.e. the genesis block), and all transactions. As the state can only be changed as part of a transaction, this is sufficient to reconstruct the state from the blockchain data. This is in fact what a full Ethereum client (the piece of software making up a node – some people including myself find the term client for this a bit confusing, given that we will learn later that most of these clients actually act as a server) does when it is initially started – it gets all blocks from the current blockchain, replays the transactions which are part of the blocks and uses this to reconstruct the state, which is then stored in a database on disk.
Note that there are some clients, the so-called light clients, which do not actually go through this process, but only download block headers and access full clients to be able to read the state if needed. Even though the state is not stored as part of the blocks, each block contains a hash value built from the state. This (and the fact that the state is organized in a data structure called a Merkle Patricia trie) allows even a light clients to access and validate the state for a given address.
Ether and gas
Before proceeding to discuss transactions, it is helpful to understand what Ether and gas are. Ether is nothing but the native digital currency of the Ethereum blockchain, similar to what bitcoin is to the bitcoin blockchain. The smallest amount of Ether that can be transferred is one Wei, and 1018 Wei is equivalent to one Ether. The balance, for instance, that is stored as part of the state of an account, is the balance in Wei. Another unit that is frequently used is the GWei, which is 109 Wei, so that 109 GWei is again one Ether.
Ether is the currency used to make payments in the Ethereum blockchain. One of the things you pay for is the processing, i.e. validation and inclusion in a block, of transactions. Similar to the bitcoin network, miners (or, after transitioning to the proof-of-stake algorithm, validators) are rewarded in Ether. The way how the fees are calculated, however, is a bit more subtle than with the bitcoin network. The reason behind this is that as part of a transaction, a smart contract might have to be executed, and to avoid DoS attacks, we want the fees to depend on the complexity of that smart contract.
To achieve this, the Ethereum blockchain uses a measurement for the complexity of a transaction called gas. Every transaction consumes a certain amount of gas. A simple transfer, for instance, requires 21000 units of gas. When a smart contract is executed as part of a transaction, every instruction consumes a certain amount of gas as well.
To price gas and to therefore price transactions, every transaction contains a gas price. This is the amount of Ether (or Wei) that the participant posting the transaction is willing to pay per unit of gas consumed by the transaction. Miners can use the gas price to select the transactions that are most beneficial for them, so that transactions with a high gas price tend to be mined faster, while transactions with a low gas price can stay pending for a long time – potentially forever. Thus choosing a reasonable gas price is essential for the successful processing of a transaction, and clients typically use a heuristic to propose a gas price for a given transaction.
In addition to the amount of gas consumed by a transaction and the gas price, there is also a gas limit that the originator of a transaction can define. Especially when executing an unknown smart contract, the amount of gas needed can be hard to predict, and therefore the gas limit serves as a safeguard to make sure that a malicious contract cannot consume an unlimited amount of gas. If during the execution of a transaction, the gas limit is exceeded, the transaction is reverted – note, however, that the gas used up to this point is lost. Therefore choosing the gas limit is also vital to ensure proper processing of a transaction.
Let us go through an example to see how this works. Suppose that you run a comparatively complex transaction, like the deployment of a smart contract, that consumes 2,409,371 units of gas. Suppose further that the current gas price is 1 GWei. Then the amount of Ether you would have to pay for this transaction is
1 GWei = 1000000000 Wei x 2409371 = 2.409371 x 1015 Wei = 0.002409371 Ether
Assuming a price of 2.600 USD per Ether, this would cost you roughly 6.26 USD. In reality, however, the real gas price is even higher (today it was 25 GWei), so this would be more than 150 USD. This is an expensive transaction, and most transactions are cheaper. Still, transaction costs can be significant on the Ethereum mainnet (the example is actually taken from the Rinkeby test network, where of course Ether costs nothing, but just to give you an idea).
If, however, you submit the transaction with a gas limit below 2,409,371, the transaction would not complete and would be reverted, resulting in a loss of the gas consumed so far.
To make things a bit more complicated, there is actually a second gas limit – the gas limit per block. This limit is set by the miners and determines an upper limit for the amount of gas that all transactions included in a block can consume. The block gas limit is a field in the block header, and, according to the yellow paper, section 4.3.4 and section 6.2, a node will verify that for each block:
- the block gas limit of the current block differs from the block limit of the parent block by at most roughly 0,1% (1/1024), so that miners can only change the block gas limit within this range with every new block
- when a transaction is added to a block, the sum of the gas limit of this transaction and the gas used by the transactions already part of the block must not exceed the block gas limit
At the time of writing, the gas limit of a block on the mainnet is roughly 15 Mio. units of gas, and the utilisation is pretty efficient, meaning that most blocks seem to spend an amount of gas which is only barely below the block gas limit.
Transactions
Let us now take a closer look at an Ethereum transaction. Here is a diagram that shows the fields that make up a transaction.
Most of these fields should be clear by now. We have already discussed the gas price and the gas limit. The signature actually consists of three values, conventionally called v, r and s. Here, r and s are the components of the signature as in the usual ECDSA algorithm, and v is an additional value called the parity that can be used to unambiguously recover the public key from the signature – this explains why the public key is not part of the transaction. Note that therefore, the signature also implicitly contains the address of the sender of the transaction.
The value is the amount of Ether (in Wei) that is to be transferred from the sender to the recipient of the transaction, which can of course be zero. Finally, there is the nonce, which is a counter that needs to be incremented by one for each transaction that is generated for a given sender. This value is needed at different points during the execution of a transaction (see again the yellow paper, sections 6 and 7)
- When a transaction is validated, the nonce of the transaction needs to be equal to the nonce stored in the state of the senders address. When a transaction is executed, the nonce in the senders state is incremented by one
- When a smart contract is deployed as part of a transaction, the nonce determines, together with the sender address, the address of the smart contract
A miner will actually queue a transaction if it detects a gap in the nonce. Thus if you submit a transaction with nonce one and a transaction with nonce three, the miner will process transaction one, but will put the transaction with nonce three into a queue, assuming that a transaction with nonce two is still on its way through the network.
Also note that miners typically allow you to replace a transaction that is still pending by sending a new transaction with the same nonce. This is useful if your transaction is stuck because the gas price is too low – you can then send the transaction again, using a higher gas price and the same nonce, and the miner will replace the transaction in its pool of pending transactions with the new version. Of course, this is only possible as long as the transaction has not yet been included in a block. Some wallets also allow you to do the same to cancel a pending transaction – simply send a transaction with the same nonce and value zero. Note, however, that miners will only accept the replacement if the gas price of the new transaction is at most equal to that of the pending transaction, and to cancel a transaction, you will actually want to increase the gas price to make sure that the replacement is mined, not the original transaction.
Why is the nonce needed? One answer to this is that it avoids a form of malicious behavior known as replay attack. Suppose you create, sign and submit a transaction that transfers 100 ETH to Eve. The transaction is mined, included in a block and added to the chain, and Eve happily receives the 100 ETH. Now Eve is greedy – she takes the transaction from the block (which she can easily do, as the data is public) and submits exactly the same transaction once more – and again, and again – you see where this is going. The nonce avoids this – when Eve tries to submit the transaction again, the nonce of the state will already have increased as a consequence of the first transaction, and miners and validators will reject the second copy of the transaction.
We have not yet touched upon the two extra fields on the right hand side of the diagram. The first field, the data, is relevant for transactions that are ordinary transactions, i.e. transactions targeting an existing smart contract or a EOA. The field can be used to include arbitrary data in the transaction, for instance arguments for the invocation of a smart contract. The second field, called init, is only relevant if a transaction is used to deploy a smart contract. A transaction will serve as deployment when its to field is the zero address. In this case, the init field is supposed to contain byte code that will be executed, and the result of this byte code will be stored as new smart contract at the contract address determined by sender and nonce.
Blocks
After all these preparations, we are now ready to finally discuss blocks. In Ethereum, a block consists of three pieces – the block header, the list of transactions included in the block and a list of headers of other blocks, the so-called ommers (which is a gender-neutral term, sometimes these blocks are called uncle blocks). These components are displayed in the diagram below

The block header contains the following information (note that the order in the list and the diagram is not exactly the order in which the fields actually appear in the block, see the source code or the yellow paper for a full and more formal description)
- First, there is a reference to the parent of the block, given by the hash value of the parent block. So the parent cannot be changed without breaking the chain, which is, after all, a characteristic property that you would expect from any blockchain. Formally, this is the Keccak hash of the RLP encoded parent block
- Next, there is a hash value of the list of ommers that can be used to validate this data
- The third field is the beneficiary, which is the address to which the mining reward for this block belongs
- The next field is the hash value root of the Merkle-Patricia trie built from the state of all addresses. The presence of this field allows a light client to validate state information without having to download the entire chain
- Similar to the hash value of the ommers list, the block header also contains a hash value of the tree of transactions included in this block
- The next field is again the hash value of the root of a trie, this time the tree built from all transaction receipts. A transaction receipt is a data structure that describes the outcome of the process of validating a transaction. Similar to the state, it is not stored in the blockchain, but needs to be calculated by a client by replaying the transactions, and the presence of the root in the block header allows a client to validate that a receipt is not manipulated
- A special part of a transaction receipt is the set of logs generated by the transaction. We will look at logs and events in a bit more detail when we talk about the Solidity programming language. To make it easier to scan the blockchain for specific log entries, the block header contains a Bloom filter of the log entries which is a special data structure that supports fast searching
- The block header also contains the block number, i.e. the number of ancestors (the genesis block therefore has block number zero) and a creation timestamp
- As discussed before, the block header contains the block gas limit along with the total gas used for this block, i.e. by all transactions in the block
- A miner can use the extra data field to add at most 32 bytes of data to a block
- Finally, there are the nonce, the mixed hash and the difficulty, which are used for the PoW algorithm (Ethereum uses an algorithm called ethash which aims at making the use of ASICS for mining more difficult by using large data structures that need to be manipulated in memory, see also appendix J of the yellow paper for a formal definition)
As you would expect, a miner that mines a new block is rewarded for this work. The reward consists of two components. First, the miner receives a base reward of currently 2 ETH for each newly mined block, regardless of the transactions contained in the block. Second, the miner receives transaction fees. The mechanism by which this happens is currently being changed by EIP-1599. Previously, a miner received the full transaction fees for all transactions in the block being mined. After implementation of the EIP, the fees will consist of a base fee that is allowed to vary slowly over time, and a priority fee that is the difference of the total transaction fees and the base fee. The miner will only receive the priority fee, and the base fee will be burned. The EIP also adds the base fee as an additional field to the block header.
Most of the above should sound familiar – but there is one detail that struck me on first reading, namely the role of the ommers. Why are they needed? The reason for including ommers is that in addition to the block reward that a miner receives for a new block, the miners (i.e. beneficiaries) of an ommer block referenced in a new block will also receive a reward, called the uncle reward.
The motivation behind this (you might want to read this paper for all the glorious details and how this impacts the rewards of miners) is as follows. Suppose you are a miner that is mining a new block, say A. At the same time, a second miner is mining another valid block, called B. Both blocks have the same parent P (the current tip of the canonical chain). Now, as the block mining rate on the Ethereum block chain is rather high, it can happen and will happen that A and B are found and distributed at roughly the same point in time. This will lead to a short fork, but after some time, the chain stabilizes and only A or B will become part of the canonical chain (the longest chain). Suppose that block B ends up being on the canonical chain – then your mining reward for block A is not part of “the” state any more, and your reward is lost.
However, suppose that you now mine a new block C, with parent B. Then, the stale block A will be an ommer of block C. If you manage to include A in the ommer list of block C, and block C makes it to the chain, you (being the beneficiary of block A) will still receive the uncle reward. The uncle reward is lower than the standard block reward, but at least the reward is not zero. In this sense, the uncle reward is a mechanism that fosters fast mining and rewards miners for producing blocks, even if this block does not make it to the canonical chain. In addition, a miner who includes ommers in a block also receives a small reward as an incentive to also include ommers created by other miners.
This closes todays post. Yes, this was a long post, but if you have followed me so far, you should have gained a solid understanding of the basic building blocks of the Ethereum block chain. Armed with this understanding, we will – in the next post – go ahead and learn more about the mysterious smart contracts that we have already touched upon several times.






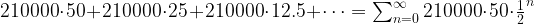
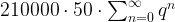
 . This series converges, and its value is
. This series converges, and its value is
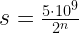
 for n, we obtain
for n, we obtain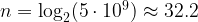
 .
.

