
In the previous post, we have reached the point where our controller is up and running and is starting to handle events. However, we hit upon a problem at the end of the last post – when running in-cluster, our controller uses a service account which is not authorized to access our bitcoin network resources. In todays post, we will see how to fix this by adding RBAC rules to our service account. In addition, we will implement the creation of the actual stateful set when a new bitcoin network is created.
Step 7: defining a service account and roles
To define what a service account is allowed to do, Kubernetes offers an authorization scheme based on the idea of role-based access control (RBAC). In this model, we do not add authorizations to a user or service account directly. Instead, the model knows three basic entities.
- Subjects are actors that need to be authorized. In Kubernetes, actors can either be actual users or service accounts.
- Roles are collection of policy rules that define a set of allowed actions. For instance, there could be a role “reader” which allows read-access to all or some resources, and a separate role “writer” that allows write-access.
- Finally, there are role bindings which link roles and subjects. A subject can have more than one role, and each role can be assigned to more than one subject. The sum of all roles assigned to a subject determines what this subject is allowed to do in the cluster
The actual data model is a bit more complicated, as there are some rules that only make sense on the cluster level, and other rules can be restricted to a namespace.
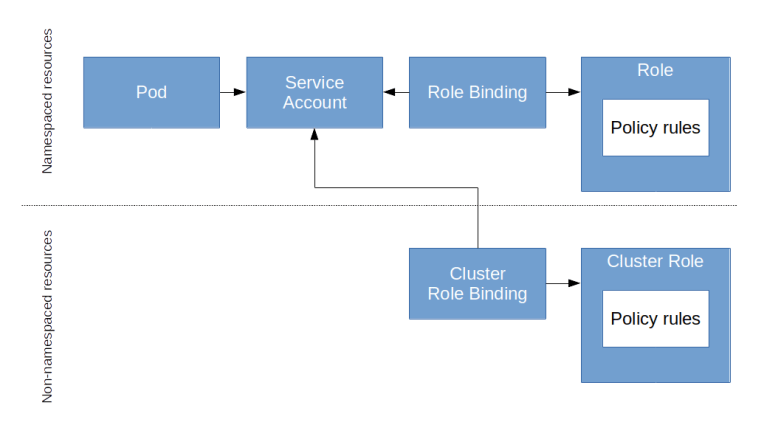
How do we specify a policy rule? Essentially, a policy rule lists a set of resources (specified by the API group and the resource type or even specific resource names) as they would show up in an API path, and a set of verbs like GET, PUT etc. When we add a policy rule to a role, every subject that is linked to this role will be authorized to run API calls that match this combination of resource and verb.
A cluster role then basically consists of a list of policy rules (there is also a mechanism called aggregation which allows us to build hierarchies or roles). Being an API object, it can be described by a manifest file and created using kubectl as any other resource. So to set up a role that will allow our controller to list, get and update bitcoin network resources and pods and create, update, get, list and delete stateful sets, we would apply the following manifest file.
kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: bitcoin-controller-role rules: - apiGroups: ["apps", ""] resources: ["statefulsets", "services"] verbs: ["get", "watch", "list", "create", "update", "delete"] - apiGroups: [""] resources: ["pods"] verbs: ["get", "list", "watch"] - apiGroups: ["bitcoincontroller.christianb93.github.com"] resources: ["bitcoinnetworks"] verbs: ["get", "list", "watch"]
Next, we set up a specific service account for our controller (otherwise we would have to add our roles to the default service account which is used by all pods by default – this is not what we want). We need to do this for every namespace in which we want to run the bitcoin operator. Here is a manifest file that creates a new namespace bitcoin-controller with a corresponding service account.
apiVersion: v1
kind: Namespace
metadata:
name: bitcoin-controller
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: bitcoin-controller-sva
namespace: bitcoin-controller
Let us now link this service account and our cluster role by defining a cluster role binding. Again, a cluster role binding can be defined in a manifest file and be applied using kubectl.
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: bitcoin-controller-role-binding subjects: - kind: ServiceAccount name: bitcoin-controller-sva namespace: bitcoin-controller roleRef: kind: ClusterRole name: bitcoin-controller-role apiGroup: rbac.authorization.k8s.io
Finally, we need to modify our pod specification to instruct Kubernetes to run our controller using our newly created service account. This is easy, we just need to add the service account as a field to the Pod specification:
... spec: serviceAccountName: bitcoin-controller-sva ...
When we now run our controller using the modified manifest file, it should be able to access all the objects it needs and the error messages observed at the end of our last post should disappear. Note that we need to run our controller in the newly created namespace bitcoin-controller, as our service account lives in this namespace. Thus you will have to create a service account and a cluster role binding for every namespace in which you want to run the bitcoin controller.
Step 8: creating stateful sets
Let us now start to fill the actual logic of our controller. The first thing that we will do is to make sure that a stateful set (and a matching headless service) is created when a new bitcoin network is defined and conversely, the stateful set is removed again when the bitcoin network is deleted.
This requires some additional fields in our controller object that we need to define and populate. We will need
- access to indexers for services and stateful sets in order to efficiently query existing stateful sets and services, i.e. additional listers and informers (strictly speaking we will not need the informers in todays post, but in a future post – here we only need the listers)
- A clientset that we can use to create services and stateful sets
Once we have this, we can design the actual reconciliation logic. This requires a few thoughts. Remember that our logic should be level-based and not edge-based, because our controller could actually miss events, for instance if it is down for some time and comes up again. So the logic that we implement is as follows and will be executed every time when we retrieve a trigger from the work queue.
Retrieve the headless service for this bitcoin network IF service does not exist THEN create new headless service END IF Retrieve the stateful set for this bitcoin network IF stateful set does not exist THEN create new stateful set END IF Compare number of nodes in bitcoin network spec with replicas in stateful set IF they are not equal update stateful set object END IF
For simplicity, we will use a naming convention to match bitcoin networks and stateful sets. This has the additional benefit that when we try to create a second stateful set by mistake, it will be refused as no two stateful sets with the same name can exist. Alternatively, we could use a randomly generated name and use labels or annotations to match stateful sets and controllers (and, of course, there are owner references – more on this below).
Those of you who have some experience with concurrency, multi-threading, locks and all this (for instance because you have built an SMP-capable operating system kernel) will be a bit alerted when looking at this code – it seems very vulnerable to race conditions. What if a node is just going down and the etcd does not know about it yet? What if the cache is stale and the status in the etcd is already reflecting updates that we do not see? What if two events are processed concurrently by different worker threads? What if a user updates the bitcoin network spec while we are just bringing up our stateful sets?
There are two fundamentally different ways to deal with these challenges. Theoretically, we could probably use the API mechanisms provided for optimistic locking ( resource versions that are being checked on updates) to implement basic synchronization primitives like compare-and-swap as it is done to implement leader election on Kubernetes, see also this blog. We could then implement locking mechanisms based on these primitives and use them to protect our resources. However, this will never be perfect, as there will always be a lag between the state in the etcd and the actual state of the cluster. In addition, this can easily put us in a situation where deadlocks occur or locks at least slow down the processing massively.
The second approach – which, looking at the source code of some controllers in the Kubernetes repositories, seems to be the approach taken by the K8s community – is to accept that full consistency will never be possible and to strive for eventual consistency. All actors in the system need to prepare for encountering temporary inconsistencies and implement mechanisms to deal with them, for instance be re-queuing events until the situation is resolved. This is the approach that we will also take for our controller. This implies, for instance, that we re-queue events when errors occur and that we leverage the periodic resync of the cache to reconcile the to-be state and the as-is state periodically. In this way, inconsistencies can arise but should be removed in the next synchronisation cycle.
In this version of the code, error handling is still very simple – most of the time, we simply stop the reconciliation when an error occurs without re-queuing the event and rely on the periodic update that happens every 30 seconds anyway because the cache is re-built. Of course there are errors for which we might want to immediately re-queue to retry faster, but we leave that optimization to a later version of the controller.
Let us now run a few tests. I have uploaded the code after adding all the features explained in this post as tag v3 to Github. For simplicity, I assume that you have cloned this code into the corresponding directory github.com/christianb93/bitcoin-controller in your Go workspace and have a fresh copy of a Minikube cluster. To build and deploy the controller, we have to add the CRD, the service account, cluster role and cluster role binding before we can build and deploy the actual image.
$ kubectl apply -f deployments/crd.yaml $ kubectl apply -f deployments/rbac.yaml $ ./build/controller/minikube_build.sh $ kubectl apply -f deployments/controller.yaml
At this point, the controller should be up and running in the namespace bitcoin-controller, and you should be able to see its log output using
$ kubectl logs -n bitcoin-controller bitcoin-controller
Let us now add an actual bitcoin network with two replicas.
$ kubectl apply -f deployments/testNetwork.yaml
If you now take a look at the logfiles, you should see a couple of messages indicating that the controller has created a stateful set my-network-sts and a headless service my-network-svc. These objects have been created in the same namespace as the bitcoin network, i.e. the default namespace. You should be able to see them doing
$ kubectl get pods $ kubectl get sts $ kubectl get svc
When you run these tests for the first time in a new cluster, it will take some time for the containers to come up, as the bitcoind image has to be downloaded from the Docker Hub first. Once the pods are up, we can verify that the bitcoin daemon is running, say on the first node
$ kubectl exec my-network-sts-0 -- /usr/local/bin/bitcoin-cli -regtest -rpcuser=user -rpcpassword=password getnetworkinfo
We can also check that our controller will monitor the number of replicas in the stateful set and adjust accordingly. When we set the number of replicas in the stateful set to five, for instance, using
$ kubectl scale --replicas=5 statefulset/my-network-sts
and then immediately list the stateful set, you will see that the stateful set will bring up additional instances. After a few seconds, however, when the next regular update happens, the controller will detect the difference and scale the replica set down again.
This is nice, but there is again a problem which becomes apparent if we delete the network again.
$ kubectl delete bitcoinnetwork my-network
As we can see in the logs, this will call the delete handler, but at this point in time, the handler is not doing anything. Should we clean up all the objects that we have created? And how would that fit into the idea of a level based processing? If the next reconciliation takes place after the deletion, how can we identify the remaining objects?
Fortunately, Kubernetes offers very general mechanisms – owner references and cascading deletes – to handle these problems. In fact, Kubernetes will do all the work for us if we only keep a few points in mind – this will be the topic of the next post.
