
In the last post in this series, we have created a more or less functional bitcoin controller. However, to be reasonably easy to operate, there are still a few things that are missing. We have hardcoded secrets in our images as well as our code, and we log data, but do not publish events. These shortcomings are on our todo list for today.
Step 12: using secrets to store credentials
So far, we have used the credentials to access the bitcoin daemon at several points. We have placed the credentials in a configuration file in the bitcoin container where they are accessed by the daemon and the bitcoin CLI and we have used them in our bitcoin controller when establishing a connection to the RPC daemon. Let us now try to replace this by a Kubernetes secret.
We will store the bitcoind password and user in a secret and map this secret into the pods in which our bitcoind is running (thus the secret needs to be in the namespace in which the bitcoin network lives). The name of the secret will be configurable in the definition of the network.
In the bitcoind container, we add a startup script that checks for the existence of the environment variables. If they exist, it overwrites the configuration. It then starts the bitcoind as before. This makes sure that our image will still work in a pure Docker environment and that the bitcoin CLI can use the same passwords.
When our controller brings up pods, it needs to make sure that the secret is mapped into the environments of the pod. To do this, the controller needs to add a corresponding structure to the container specification when bringing up the pod, using the secret name provided in the specification of the bitcoin network. This is done by the following code snippet.
sts.Spec.Template.Spec.Containers[0].EnvFrom = []corev1.EnvFromSource{
corev1.EnvFromSource{
SecretRef: &corev1.SecretEnvSource{
Optional: &optional,
LocalObjectReference: corev1.LocalObjectReference{
Name: bcNetwork.Spec.Secret,
},
},
},
}
The third point where we need the secret is when the controller itself connects to a bitcoind to manage the node list maintained by the daemon. We will use a direct GET request to retrieve the secret, not an informer or indexer. The advantage of this approach is that in our cluster role, we can restrict access to a specific secret and do not have to grant the service account the right to access ANY secret in the cluster which would be an obvious security risk.
Note that the secret that we use needs to be in the same namespace as the pod into which it is mapped, so that we need one secret for every namespace in which a bitcoin network will be running.
Once we have the secret in our hands, we can easily extract the credentials from it. To pass the credentials down the call path into the bitcoin client, we also need to restructure the client a bit – the methods of the client now accept a full configuration instead of just an IP address so that we can easily override the default credentials. If no secret has been defined for the bitcoin network, we still use the default credentials. The code to read the secret and extract the credentials has been placed in a new package secrets.
Step 13: creating events
As a second improvement, let us adapt our controller so that it does not only create log file entries, but actively emits events that can be accessed using kubectl or the dashboard or picked up by a monitoring tool.
Let us take a quick look at the client-side code of the Kubernetes event system. First, it is important to understand that events are API resources – you can create, get, update, list, delete and watch them like any other API resource. Thus, to post an event, you could simply use the Kubernetes API directly and submit a POST request. However, the Go client package contains some helper objects that make it much easier to create and post events.
A major part of this mechanism is located in the tools/record package within the Go client. Here the following objects and interfaces are defined.
- An event sink is an object that knows how to forward events to the Kubernetes API. Most of the time, this will be a REST client accessing the API, for instance the implementation in events.go in kubernetes/typed/core/v1.
- Typically, a client does not use this object directly, but makes use of an event recorder. This is just a helper object that has a method Event that assembles an event and passes it to the machinery so that it will eventually be picked up by the recorder and sent to the Kubernetes API
- The missing piece that connects and event sink and an event recorder is an event broadcaster. This is a factory class for event recorders. You can ask a broadcaster for a record and set up the broadcaster such that events received via this recorder are not only forwarded to the API, but also logged and forwarded to additional event handlers.
- Finally, an event source is basically a label that is added to the events that we generate, so that whoever evaluates or reads the events knows where they originate from
Under the hood, the event system uses the broadcaster logic provided by the package apimachinery/pkg/watch. Here, a broadcaster is essentially a collection of channels. One channel, called the incoming channel, is used to collect messages, which are then distributed to N other channels called watchers. The diagram below indicates how this is used to manage events.
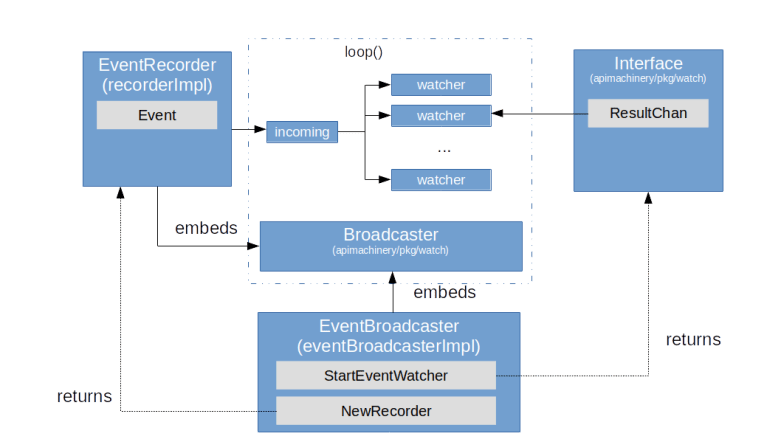
When you create an event broadcaster, a watch.Broadcaster is created as well (embedded into the event broadcaster), and when you ask this broadcaster to create a new recorder, it will return a recorder which is connected to the same watch.Broadcaster. If a recorder publishes an event, it will write into the incoming queue of this broadcaster, which then distributes the event to all registered watchers. For each watcher, a new goroutine is started with invokes a defined function once an event is received. This can be a function to perform logging, but also be a function to write into an event sink.
To use this mechanism, we therefore have to create an event broadcaster, an event source, an event sink, register potentially needed additional handlers and finally receive a recorder. The Kubernetes sample controller again provides a good example how this is done.
After adding a similar code to our controller, we will run into two small problems. First, events are API resources, and therefore our controller needs the right to create them. So once more, we need to adapt our cluster role to grant that right. The second problem that we can get is that the event refers to a bitcoin network, but is published via the core Kubernetes API. The scheme used for that purpose is not aware of the existence of bitoin network objects, and the operation will fail, resulting in the mesage ‘Could not construct reference to …due to: ‘no kind is registered for the type v1.BitcoinNetwork in scheme “k8s.io/client-go/kubernetes/scheme/register.go:65″‘. To fix this, we can simply add our scheme to the default scheme (as it is also done in the sample controller
This completes todays post. In the next post, we will discuss how we can efficiently create and run automated unit and integration tests for our controller and mock the Kubernetes API.
