
In the history of AI, progress has always come from several sources – more powerful hardware, more high-quality training data or refined training methods. And sometimes, we have seen a step change triggered by a new and innovative generation of models.
Some of you might remember the time when the term Deep Learning was coined, referring to machine learning models consisting of several stacked layers of neural networks. Later, convolutional neural networks (CNNs) took computer vision and image recognition by storm, and recurrent neural networks and in particular LSTMs where widely applied to boost applications in natural language processing like machine translation or sentiment analysis.
Similarly, the recent revolution in natural language processing has been triggered by a novel type of neural networks called Transformers which is very well adapted to the specific challenges of processing long sentences. In fact, all of the currently hyped language models like GPT , Googles LaMDA or Facebooks LLaMA are based on the transformer architecture – so clearly that is something that everybody interested in machine learning should probably understand.
This is what we will do in this series – take a deeper look at the transformer architecture, understand how these models are implemented and trained and learn how pre-trained, publicly available models can easily be downloaded and used. We will cover both the theory, referring to the original papers on the subject if that makes senses, and practice, using the PyTorch framework to implement some networks and training scripts ourselves.
More specifically, we will cover the following topics in this series:
- the basics of NLP – tokenization, vocabularies and language modelling tasks
- representing words as vectors and word similarity
- a brief look at the generation of models preceding transformers, i.e. recurrent neural networks, LSTM networks and encoder-decoder architectures
- Project I: training a character level LSTM on Tolstoys War and Peace
- the attention mechanism and how it is used in transformer models
- transformer blocks, encoders and decoders
- Subword tokenization and BPE
- Project II: training a transformer on Wikipedia
- Using pretrained transformers like GPT-2 or DialoGPT
- Project III: building a chatbot using DialoGPT and the Huggingface Transformer library
- Instruction fine-tuning and FLAN-T5
- Proximal Policy Optimization (PPO) and reinforcement learning
Obviously, we cannot start from zero to be able to cover all this. So I assume some familiarity with machine learning and neural networks (if this is new to you, you might want to read some of the excellent available introductions like chapter 7 of Speech and Language processing by Jurafsky and Martin, which also covers parts of what we will discuss, chapter 3 and 4 of Dive into Deep Learning or chapter 5 – 7 of Machine learning with neural networks by B. Mehlig). I also assume that you understand the basics of PyTorch, if not, I recommend the excellent introduction to PyTorch which is part of the official documentation.
Tokenization, vocabularies and basis tasks in NLP
After this short outlook of what’s ahead, let us dive right into the content. We start by explaining some terms that you will see over and over again if you get into the field of natural language processing (NLP).
First, let us discuss some of the common problems that NLP tries to solve. Some of these problems can be described as a classification task. The input that machine learning models receive is a text, consisting of a sequence of words or, more generally, token (we get to this in a minute), and the output is a label. An example for this type of task is sentiment analysis. The model is given a text, for instance a review of a movie or a book, and is asked to predict whether the overall sentiment of the review is positive or negative. Note that the input to the model, the text, has a linear structure – each word has a position, so there is a notion of time in the input – while the output is simply a label.
A second class of tasks is sometimes called sequence-to-sequence and consists of receiving a sequence of words as an input and providing a sequence of words as output. The prime example is machine translation, which receives a sequence of words in the source language as input and produces a translation into the target language. Note that the length of the target and length of the source are, in general, different.
Finally, a third class of problems (there are many more in NLP) that we will be concerned with is text generation. Here the task is to create a text which appears natural and fluent (and of course grammatically correct) from scratch, maybe be completing a short piece of text fed into the model called the prompt. We will see later that machine translation can actually be expressed as conditional text generation, i.e. text generation giving some context which, in the case of a translation task will be an encoding of the input sequence.
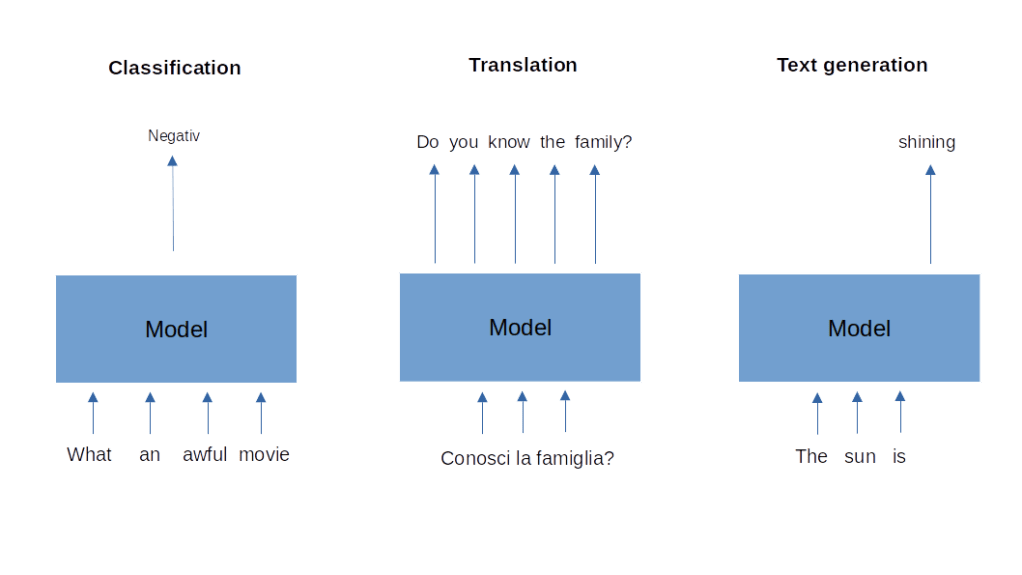
For all of these tasks, we will have to find a reasonable way to encode a sequence of words as number or, more precisely, as vectors. Typically, this proceeds in several steps. The first step is tokenization which means that we break down our text into a list of tokens. Initially, a token will be a word or a punctuation character, but later we will turn to more general tokens which can be parts of words or even individual characters. The most straightforward way to do this is to split a text along spaces, i.e. to do something like
text = "My name is John. What is your name?"
token = text.split()
print(token)
which would give the toutput
['My', 'name', 'is', 'John.', 'What', 'is', 'your', 'name?']
This is simple, maybe too simple. We combine, for instance, a punctuation mark along with the word after which it follows, which might not be a good idea as a punctuation mark has an independent syntactical meaning. We also do not convert our words to lower- or uppercase, so that “Name” and “name” would be different token. There are many ready-to-use implementations of more sophisticated approaches. For now, we will use the tokenizer that is part of the Torchtext library. To use this, please make sure that you have torch and torchtext installed, I have used version 2.0.0 of PyTorch and version 0.15.1 of Torchtext, but older versions should work as well. We can than tokenize the same text as before as follows.
import torchtext
tokenizer = torchtext.data.utils.get_tokenizer("basic_english")
print(tokenizer(text))
This time, the output that we get is
['my', 'name', 'is', 'john', '.', 'what', 'is', 'your', 'name', '?']
We see that the tokenizer has converted all words into lower-case and has translated punctuation marks into individual token.
The next stage consists of building a list of all known token that appear in our text, i.e. of all unique token. This can conveniently be done using a counter. Here is a short code snippet that creates a list of all unique token.
import collections
token = tokenizer(text)
counter = collections.Counter(token)
vocabulary = [t for t in counter.keys()]
print(vocabulary)
# Output: ['my', 'name', 'is', 'john', '.', 'what', 'your', '?']
So far, our token are still words. To feed them into a neural network, we will have to encode them as numbers. For that purpose, we replace each token in the original text by its index in the vocabulary, so that the initial text is turned into a sequence of numbers. Note that this sequence still preserves the sequential structure, i.e. the order of numbers is the same as the order of the corresponding words in the original sentence (there are other models, commonly referred to as bag-of-word models, in which only the unordered set of token is considered).
stois = dict()
for idx, t in enumerate(vocabulary):
stois[t] = idx
encoded_text = [stois[t] for t in token]
print(encoded_text)
# Output: [0, 1, 2, 3, 4, 5, 2, 6, 1, 7]
Of course, we can revert this process by replacing each index in the list by the corresponding token, a process known as decoding.
decoded_text = " ".join([vocabulary[idx] for idx in encoded_text])
print(decoded_text)
# Output: my name is john . what is your name ?
Most tokenizers will, in addition to the token generated by identifying words in the text, use additional special token that represent of instance unknown words (i.e. words which are not in the vocabulary as they have not been part of the text used to build the vocabulary) or the end or beginning of a sentence.
At this point, we have converted text into a sequence of numbers. In order to be meaningful as input to a neural network, we now have to turn each of these numbers into a vector. A straightforward approach would be to use one-hot encoding. Suppose that our vocabulary has V items. Then we can turn an index i into a vector in V-dimensional space which is one at position i and zero at all other positions. In other words, the encodings form a base of the vector space on which the model will then operate. This encoding is simply, but has two major drawbacks. First, it treats all words in the same way, regardless of their meaning. It would be nice to have an embedding that translates words into vectors in such a way that similar words end up as somehow similar vectors. Second, the vector space become huge. A vocabulary can easily be as big as 50 k or more token, so our vector space would have 50.000 dimensions, blowing up the model unnecessarily. For those reasons, other procedures to turn words into vectors are more common, which will be the topic of the next post. If you want to try out what we have discussed today, you can download a notebook here and play with it.

6 Comments