One of the strengths of Kubernetes is the ability to spin up pods and containers with a defined workload within seconds, which makes it the ideal platform for automated testing and continuous deployment. In this, we will see how GitHub, Kubernetes, Helm and Travis CI play together nicely to establish a fully cloud based CI/CD pipeline for your Kubernetes projects.
Introduction
Traditional CI/CD pipelines require a fully equipped workstation, with tools like Jenkins, build environments, libraries, repositories and so forth installed on them. When you are used to working in a cloud based environment, however, you might be looking for alternatives, allowing you to maintain your projects from everywhere and from virtually every PC with a basic equipment. What are your options to make this happen?
Of course there many possible approaches to realize this. You could, for instance, maintain a separate virtual machine running Jenkins and trigger your builds from there, maybe using Docker containers or Kubernetes as build agents. You could use something like Gitlab CI with build agents on Kubernetes. You could install Jenkins X on your Kubernetes cluster. Or you could turn to Kubernetes native solutions like Argo or Tekton.
All these approaches, however, have in common that they require additional infrastructure, which means additional cost. Therefore I dediced to stick to Travis CI as a CI engine and control my builds from there. As Travis runs builds in a dedicated virtual machine, I can use kind to bring up a cluster for integration testing at no additional cost.
The next thing I wanted to try out is a multi-staged pipeline based on the GitOps approach. Roughly speaking, this approach advocates the use of several repositories, one per stage, which each reflect the actual state of the respective stage using Infrastructure-as-a-code. Thus, you would have one repository for development, one for integration testing and one for production (knowing, of course, that real organisations typically have additional stages). Each repository contains the configuration (like Kubernetes YAML files or other configuration items) for the respective Kubernetes cluster. At every point in time, the cluster state is fully in sync with the state of the repository. Thus, if you want to make changes to a cluster, you would not use kubectl or the API to directly deploy into the cluster and update your repository after the fact, but you would rather change the configuration of the cluster stored in the repository, and have a fully automated process in place which detects this change and updates the cluster.
The tool chain originally devised by the folks at Weaveworks requires access to a Kubernetes cluster, which, as described above, I wanted to avoid for cost reasons. Still, some of the basic ideas of GitOps can be applied with Travis CI as well.
Finally, I needed an example project. Of course, I decided to choose my bitcoin controller for Kubernetes, which is described in a series of earlier posts starting here.
Overall design and workflow
Based on these considerations, I came up with the following high-level design. The entire pipeline is based on three GitHub repositories.
- The first repository, bitcoin-controller, represents the DEV stage of the project. It contains the actual source code of the bitcoin controller.
- The second repository, bitcoin-controller-helm-qa, represents the QA stage. It does not contain source code, but a Helm chart that describes the state of the QA environment.
- Finally, the third repository, bitcoin-controller-helm, represents a release of the production stage and contains the final, tested and released packaged Helm charts
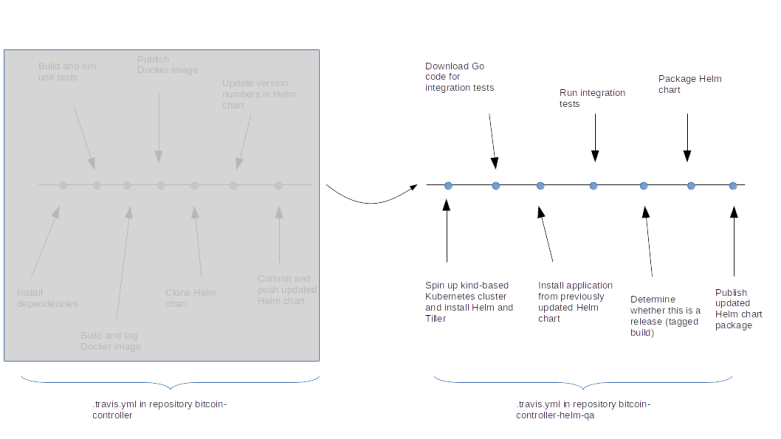
To illustrate the overall pipeline, let us take a look at the image below.

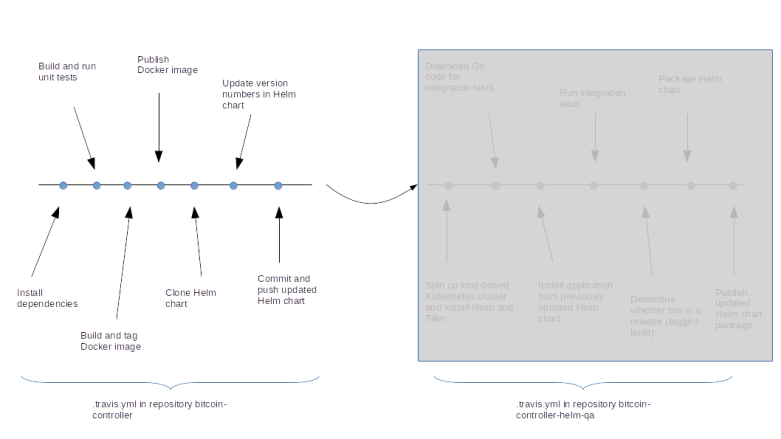
The process starts on the left hand side of the above diagram if a developer pushes a change into the DEV repository. At this point, the Travis CI process will start, spin up a virtual machine, install Go and required libraries and conduct build and unit test. Then, a Docker image is built and pushed into the Docker Hub image repository, using the Github commit as a tag. Finally, the new tag is written into the Helm chart stored in the QA repository so that the Helm chart points to the now latest version of the Docker image.
This change in the bitcoin-controller-helm-qa repository now triggers a second Travis CI pipeline. Once the virtual machine has been brought up by Travis, we install kind, spin up a Kubernetes cluster, install Helm in this cluster, download the current version of the Helm charts and install the bitcoin controller using this Helm chart. As we have previously updated the Docker tag in the Helm chart, this will pull the latest version of the Docker image.
We then run the integration tests against our newly established cluster. If the integration test succeeds, we package our Helm chart and upload them into the bitcoin-controller-helm repository.
However, we do not want to perform this last step for every single commit, but only for releases. To achieve this, we check at this point whether the commit was a tagged commit. If yes, a new package is built using the tag as version number. If not, the process stops at this point and no promote to the bitcoin-controller-helm-qa is executed.
Possible extensions
This simple approach can of course be extended into several directions. First, we could add an additional stage to also test our packaged Helm chart. In this stage, we would fully simulate a possible production environment, i.e. spin up a cluster at AWS, DigitalOcean or whatever your preferred provider is, deploy the packaged Helm chart and run additional tests. You could also easily integrate additional QS steps, like a performance test or static code analysis into this pipeline.
Some organisations like to add manual approval steps before deploying into production. Unfortunately, Travis CI does not seem to offer an easy solution for this. To solve this, one could potentially uses branches instead of tags to flag a certain code version as a release, and only allow specific users to perform a push or or merge into this branch.
Finally, we currently only store the Docker image which we then promote through the stages. This is fine for a simple project using Go, where there are no executables or other artifacts. For other projects, like a typical Java web application, you could use the same approach, but in addition store important artifacts like a WAR file in a separate repository, like Nexus or Artifactory.
Let us now dive into some more implementation details and pitfalls when trying to actually code this solution.
Build and deploy
Our pipeline starts when a developer pushes a code change into the DEV repository bitcoin-controller. At this point, Travis CI will step in and run our pipeline, according to the contents of the respective .travis.yml file. After some initial declarations, the actual processing is done by the stage definitions for the install, script and deploy phase.
install:
- go get -d -t ./...
script:
- go build ./cmd/controller/
- go test -v ./... -run "Unit" -count=1
- ./travis/buildImage.sh
deploy:
skip_cleanup: true
provider: script
script: bash ./travis/deploy.sh
on:
all_branches: true
Let us go through this step by step. In the install phase, we run go get to install all required dependencies. Among other things, this will download the Kubernetes libraries that are needed by our project. Once this has been completed, we use the go utility to build and run the unit tests. We then invoke the script buildImage.sh.
The first part of the script is important for what follows – it determines the tag that we will be using for this build. Here are the respective lines from the script.
# # Get short form of git hash for current commit # hash=$(git log --pretty=format:'%h' -n 1) # # Determine tag. If the build is from a tag push, use tag name, otherwise # use commit hash # if [ "X$TRAVIS_TAG" == "X" ]; then tag=$hash else tag=$TRAVIS_TAG fi
Let us see how this works. We first use git log with the pretty format option to get the short form of the hash of the current commit (this works, as Travis CI will have checked out the code from Github and will have taken us to the root directory of the repository). We then check the environment variable TRAVIS_TAG which is set by Travis CI if the build trigger originates from pushing a tag to the server. If this variable is empty, we use the commit hash as our tag, and treat the build as an ordinary build (we will see later that this build will not make it into the final stage, but will only go through unit and integration testing). If the variable is not set, then we use the name of the tag itself.
The rest of the script is straighforward. We run a docker build using our tag to create an image locally, i.e. within the Docker instance of the Travis CI virtual machine used for the build. We also tag this image as latest to make sure that the latest tag does actually point to the latest version. Finally, we write the tag into a file for later use.
Now we move into the deploy stage. Here, we use the option skip_cleanup to prevent Travis from cleanup up our working directory. We then invoke another script deploy.sh. Here, we read the tag again from the temporary file that we have created during the build stage and push the image to the Docker Hub, using this tag once more.
# # Login to Docker hub # echo "$DOCKER_PASSWORD" | docker login --username $DOCKER_USER --password-stdin # # Get tag # tag=$(cat $TRAVIS_BUILD_DIR/tag) # # Push images # docker push christianb93/bitcoin-controller:$tag docker push christianb93/bitcoin-controller:latest
At this point, it is helpful to remember the use of image tags in Helm as discussed in one of my previous posts. Helm advocates the separation of charts (holding deployment information and dependencies) from configuration by moving the configuration into separate files (values.yaml) which are then merged back into the chart at runtime using placeholders. Applying this principle to image tags implies that we keep the image tag in a values.yaml file. To prepare for integration testing where we will use the Helm chart to deploy, we will now have to replace the tag name in this file by the current tag. So we need to check out our Helm chart using git clone and use our beloved sed to replace the image tag in the values file by its current value.
But this is not the only change that we want to make to our Helm chart. Remember that a Helm chart also contains versioning information – a chart version and an application version. However, at this point, we cannot simply use our tag anymore, as Helm requires that these version numbers follow the SemVer semantic versioning rules. So at this point, we need to define rules how we compose our version number.
We do this as follows. Every release receives a version number like 1.2, where the first digit is the major release and the second digit is the minor release. In GitHub, releases are created by pushing a tag, and the tag name is used as version number (and thus has to follow this convention). Development releases are marked by appending a hyphen followed by dev and the commit hash to the current version. So if the latest version is 0.9 and we create a new build with the commit hash 64ed033, the new version number will be 0.9-dev64ed033.
So we update the values file and the Helm chart itself with the new image tag and the new version numbers. We then push the change back into the Helm repository. This will trigger a second Travis CI pipeline and the integration testing starts.
Integration testing
When the Travis CI pipeline for the repository bitcoin-helm-qa has reached the install stage, the first thing that is being done is to download the script setupVMAndCluster.sh which is located in the code repository and to run it. This script is responsible for executing the following steps.
- Download and install Helm (from the snap)
- Download and install kubectl
- Install kind
- Use kind to create a test cluster inside the virtual machine that Travis CI has created for us
- Init Helm and wait for the Tiller container to be ready
- Get the source code from the code repository
- Install all required Go libraries to be ready for the integration test
Most of these steps are straightforward, but there are a few details which are worth being mentioned. First, this setup requires a significant data volume to be downloaded – the kind binary, the container images required by kind, Helm and so forth. To avoid that this slows down the build, we use the caching feature provided by Travis CI which allows us to cache the content of an arbitrary directory. If, for instance, we find that the kind node image is in the cache, we skip the download and instead use docker load to pre-load the image into the local Docker instance.
The second point to observe is that for integration testing, we need the code for the test cases which is located in the code repository, not in the repository for which the pipeline has been triggered. Thus we need to manually clone into the code repository. However, we want to make sure that we get the version of the test cases that matches the version of the Helm chart (which could, for instance, be an issue if someone changes the code repository while a build is in progress). Thus we need to figure out the git commit hash of the code version under test an run git checkout to use that version. Fortunately, we have put the commit hash as application version into the Helm chart while running the build and deploy pipeline, so we can use grep and awk to extract and use the commit hash.
tag=$(cat Chart.yaml | grep "appVersion:" | awk {' print $2 '})
cd $GOPATH/src/github.com/christianb93
git clone https://github.com/christianb93/bitcoin-controller
cd bitcoin-controller
git checkout $tag
Once this script has completed, we have a fully functional Kubernetes cluster with Helm and Tiller installed running in our VM. We can now use the Helm chart to install the latest version of the bitcoin controller and run our tests. Once the tests complete, we perform a cleanup and run an additional script (promote.sh) to enter the final stage of the build process.
This script updates the repository bitcoin-controller-helm that represents the Helm repository with the fully tested and released versions of the bitcoin controller. We first examine the tag to figure out whether this is a stable version, i.e. a tagged release. If this is not the case, the script completes without any further action.
If the commit is a release, we rename the directory in which our Helm chart is located (as Helm assumes that the name of the Helm chart and the name of the directory coincide) and update the chart name in the Chart.yaml file. We then remove a few unneeded files and use the Helm client to package the chart.
Next we clone into the bitcoin-controller-helm repository, place our newly packaged chart there and update the index. Finally, we push the changes back into the repository – and we are done.