
This blog is all about code – we will implement and train an LSTM on Tolstoys War and Peace and use it to generate new text snippets that (well, at least very remotely) resemble pieces from the original novel. All the code can be found here in my GitHub repository for this series.
First, let us talk about the data we are going to use. Fortunately, the original novel is freely available in a text-only format at Project Gutenberg. The text file in UTF-8 encoding contains roughly 3.3 million characters.
After downloading the book, we need to preprocess the data. The respective code is straightforward – we tokenize the text, build a vocabulary from the list of token and save the vocabulary on disk. We then encode the entire text and save 90% of the data in a training data set and 10% of the data in a validation data set.
The tokenizer requires some thoughts. We cannot simply use the standard english tokenizer that comes with PyTorch, as we want to split the text down to the level of the individual characters. In addition, we want to compress a sequence of multiple spaces into one, remove some special characters and replace line breaks by spaces. Finally, we convert the text into a list of characters. Here is the code for a simple tokenizer that does all this.
def tokenize(text):
text = re.sub(r"[^A-Za-z0-9 \-\.;,\n\?!]", '', text)
text = re.sub("\n+", " ", text)
text = re.sub(" +", " ", text)
return [_t for _t in text]
The preprocessing step creates three files that we will need later – train.json which contains the encoded training data in JSON format, val.json which contains the part of the text held back for validation and vocab.pt which is the vocabulary.
The next step is to assemble a dataset that loads the encoded book (either the training part or the validation part) from disk and returns the samples required for training. Teacher forcing is implemented in the __getitem__ method of the dataset by setting the targets to be the input shifted by one character to the right.
def __getitem__(self, i):
if (i < self._len):
x = self._encoded_book[i: i + self._window_size]
y = self._encoded_book[i + 1: i + self._window_size + 1]
return torch.tensor(x), torch.tensor(y)
else:
raise KeyError
For testing, it is useful to have an implementation of the dataset that uses only a small part of the data. This is implemented by an additional parameter limit that, if set, restricts the length of the dataset artificially to a given number of token.
Next let us take a look at our model. Nothing here should come as a surprise. We first use an embedding layer to convert the input (a sequence of indices) into a tensor. The actual network consists of an LSTM with four layers and an output layer which converts the data back from the hidden dimension to the vocabulary, as we have used it before. Here is the forward method of the model which again optionally accepts a previously computed hidden layer – the full model can be found here.
def forward(self, x, hidden = None):
x = self._embedding(x) # shape is now (L, B, E)
x, hidden = self._lstm(x, hidden) # shape (L, B, H)
x = self._out(x)
return x, hidden
Finally, we need a training loop. Training proceeds as in the examples we have seen before. After each epoch, we perform a validation run, record the validation loss and save a model checkpoint. Note, however, that training will take some time, even on a GPU – be prepared for up to an hour on an older GPU. In case you want to skip training, I have included a pretrained model checkpoint in the GitHub repository, so if you want to run the training yourself, remove this first. Assuming that you have set up your environment as described in the README, training therefore proceeds as follows.
cd warandpeace
python3 preprocess.py
# Remove existing model unless you want to pick up from previous model
rm -f model.pt
python3 train.py
Note that the training will look for an existing model model.pt on disk, so you can continue to train using a previously saved checkpoint. If you start the training from scratch and use the default parameters, you will have a validation loss of roughly 1.27 and a training loss of roughly 1.20 at the end of the last epoch. The training losses are saved into a file called losses.dat that you can display using GNUPlot if that is installed on your machine.
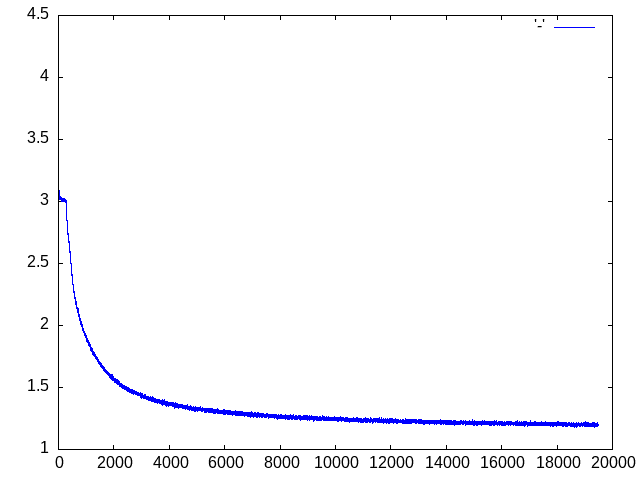
In case you want to reproduce the training but do not have access to a GPU, you can use this notebook in which I have put together the entire code for this post and run it in Google Colab, using one of the freely available GPUs. Training time will of course depend on the GPU that Google will assign to your runtime, for me training took roughly 30 minutes.
After training has completed (or in case you want to dive right away into inference using the pretrained model), we can now start to sample from the model.
python3 predict.py
The script has some parameters that you can use to select a sampling method (greedy search, temperature sampling, top-k sampling or top-p sampling), the parameters (temperature, k, p), the length of the sample and the prompt. Invoke the script with
python3 predict.py --help
to get a summary of the available parameters. Here are a few examples created with the standard settings and a length of 500 characters, using the model checked into the repository. Note that sampling is actually fast, even on a CPU, so you can try this also in case you are not working on a CUDA-enabled machine.
She went away and down the state of a sense of self-sacrifice. The officers who rode away and that the soldiers had been the front of the position of the room, and a smile he had been free to see the same time, as if they were struck with him. The ladies galloped over the shoulders and in a bare house. I should be passed about so that the old count struck him before. Having remembered that it was so down in his bridge and in the enemys expression of the footman and promised to reach the old…
Thats a wish to be a continued to be so since the princess in the middle of such thoughts of which it was all would be better. Seeing the beloved the contrary, and do not about that a soul of the water. The princess wished to start for his mother. He was the princess and the old colonel, but after she had been sent for him when they are not being felt at the ground of her face and little brilliant strength. The village of Napoleon was stronger difficult as he came to him and asked the account
Of course this is not even close to Tolstoy, but our model has learned quite a bit. It has learned to assemble characters into words, in fact all the words in the samples are valid english words. It has also learned that at the start of a sentence, words start with a capital letter. We even see some patterns that resemble grammar, like “Having remembered that” or “He was the princess”, which of course does not make too much sense, but is a combination of a pronoun, a verb and an object. Obviously our model is small and our training data set only consists of a few million token, but we start to see that this approach might take us somewhere. I encourage you to play with additional training runs or changed parameters like the number of layers or the model dimension to see how this affects the quality of the output.
In the next post, we will continue our journey through the history of language models and look at encoder-decoder architectures and the rise of attention mechanisms.

2 Comments