
In the previous post on RBMs, we have derived the following gradient descent update rule for the weights.
![\Delta W_{ij} = \beta \left[ \langle v_i \sigma(\beta a_j) \rangle_{\mathcal D} - \langle v_i \sigma(\beta a_j) \rangle_{P(v)} \right]](https://s0.wp.com/latex.php?latex=%5CDelta+W_%7Bij%7D+%3D+%5Cbeta+%5Cleft%5B+%5Clangle+v_i+%5Csigma%28%5Cbeta+a_j%29+%5Crangle_%7B%5Cmathcal+D%7D+-+%5Clangle+v_i+%5Csigma%28%5Cbeta+a_j%29+%5Crangle_%7BP%28v%29%7D+%5Cright%5D++&bg=FFFFFF&fg=000&s=1&c=20201002)
In this post, we will see how this update rule can be efficiently implemented. The first thing that we note is that the term 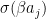
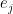
![\Delta W_{ij} = \beta \left[ \langle v_i e_j \rangle_{\mathcal D} - \langle v_i e_j \rangle_{P(v)} \right]](https://s0.wp.com/latex.php?latex=%5CDelta+W_%7Bij%7D+%3D+%5Cbeta+%5Cleft%5B+%5Clangle+v_i+e_j+%5Crangle_%7B%5Cmathcal+D%7D+-+%5Clangle+v_i+e_j+%5Crangle_%7BP%28v%29%7D+%5Cright%5D++&bg=FFFFFF&fg=000&s=1&c=20201002)
Theoretically, we know how to calculate this. The first term – the positive phase – is easy, this is just the average over the sample set.
The second term is more challenging. Theoretically, we would need a Gibbs sampler to calculate it using a Monte Carlo approach. One step of this sampler would proceed as follows.
- Given the values v of the visible units, calculate the resulting expectation values e
- Set hidden unit j to one with probability ej
- For each visible unit i, calculate the conditional probability pi to be one given the new values of the hidden units
- Set vi to 1 with probability pi
After some burn-in phase, we would then calculate the product 
The crucial point is that for a naive implementation, we would start the Gibbs sampling procedure during each gradient descent iteration from scratch, i.e. with some randomly initialized values for the visible units. One of the ideas behind the algorithm known as contrastive divergence that was proposed by G. Hinton in [1] is to restart the Gibbs sampler not at a random value, but a randomly chosen vector from the data set! The idea behind this is that if we have been running the training for some time, the model distribution should be close to the empirical distribution of the data, so sampling a vector from the data should give us something close to the equilibrium state of the Gibbs sampling Markov chain (if you do not known what a Markov chain is – do not worry and just read on, I will cover Markov chains and the mathematics behind all this in a later post).
The second approximation that the contrastive divergence algorithm makes is to replace the expectation values in the positive and negative phase by a point estimate. For the positive phase, that means we simply calculate the value at one point from the data set. For the negative phase, we run the Gibbs sampling procedure – starting as explained above with a vector from the data set – and then simply compute the product
It now turns out that, based on empirical observations, these approximations work extremely well – in fact, it turns out that instead of running a full Gibbs sampler with a few hundred or even a few thousand steps, one step is often sufficient! This is surprising, but open to an intuitive explanation – we run all this within the outer loop provided by the gradient descent algorithm, and if we chose the learning rate sufficiently small, the parameters do not change a lot between these steps, so that we effectively do something that is close to one long Gibbs sampling Markov chain.
With these simplifications, the constrastive divergence algorithm now looks as follows.
FOR EACH iteration DO
Sample a vector v from the data set
SET

FOR EACH hidden unit DO
SET 
FOR EACH visible unit DO
SET 

SET

SET
![W = W + \lambda \beta \left[ v e^T - \bar{v} \bar{e}^T \right]](https://s0.wp.com/latex.php?latex=W+%3D+W+%2B+%5Clambda+%5Cbeta+%5Cleft%5B+v+e%5ET+-+%5Cbar%7Bv%7D+%5Cbar%7Be%7D%5ET+%5Cright%5D+&bg=FFFFFF&fg=000&s=0&c=20201002)
SET
![b = b + \lambda \beta \left[ v - \bar{v} \right]](https://s0.wp.com/latex.php?latex=b+%3D+b+%2B+%5Clambda+%5Cbeta+%5Cleft%5B+v+-+%5Cbar%7Bv%7D+%5Cright%5D+&bg=FFFFFF&fg=000&s=0&c=20201002)
SET
![c = c + \lambda \beta \left[ e - \bar{e} \right]](https://s0.wp.com/latex.php?latex=c+%3D+c+%2B+%5Clambda+%5Cbeta+%5Cleft%5B+e+-+%5Cbar%7Be%7D+%5Cright%5D+&bg=FFFFFF&fg=000&s=0&c=20201002)
DONE
The first six lines within an iteration constitute one Gibbs sampling step, starting with a value for the visible units from the data set, sampling the hidden units from the visible units and sampling the visible units from the hidden units. In the next line, we recalculate the expectation values of the hidden units given the (updated) values of the visible units. The value 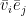
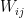


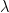
Let us now implement this in Python. To have a small data set for our tests, we will use an artificial data set called bars and stripes that I have seen first in [3]. Given a number N, we can create an image with N x N pixels for every number x smallers than 2N as follows. Each row corresponds to one binary digit of x. If this digit is one, the entire row is black, i.e. we have one black vertical stripe, otherwise the entire row is white. A second row of patterns is obtained by coloring the columns similarly instead of the rows. Thus we obtain 2N+1 possible patterns, more than enough for our purposes. I have written a helper class BAS in Python that creates these patterns.
Next, let us turn to the actual RBM. We store the current state of the RBM in a class RBM that is initialized as follows.
class RBM:
def __init__ (self, visible = 8, hidden = 3, beta = 1):
self.visible = visible
self.hidden = hidden
self.beta = beta
self.W = np.random.normal(loc = 0, scale = 0.01, size = (visible, hidden))
self.b = np.zeros(shape = (1,visible))
self.c = np.zeros(shape = (1,hidden))
Here W is the weight matrix, beta is the inverse temperature, and b and c are the bias vectors for the visible and hidden units.
Next we need a method that runs one step in a Gibbs sampling chain, starting with a state of the visible units captured in a matrix V (we calculate this in a mini-batch for more than one sample at a time, each row in the matrix represents one sample vector). Using once more the numpy library, this can be done as follows.
def runGibbsStep(self, V, size = 1):
#
# Sample hidden units from visible units
#
E = expit(self.beta*(np.matmul(V, self.W) + self.c))
U = np.random.random_sample(size=(size, self.hidden))
H = (U <= E).astype(int)
#
# and now sample visible units from hidden units
#
P = expit(self.beta*(np.matmul(H, np.transpose(self.W)) + self.b))
U = np.random.random_sample(size=(size, self.visible))
return (U <= P).astype(int), E
With this method at hand – which returns the new value for the visible units but the old value for the conditional expectation of the hidden units – we can now code our training routine.
def train(self, V, iterations = 100, step = 0.01):
batch_size = V.shape[0]
#
# Do the actual training. First we calculate the expectation
# values of the hidden units given the visible units. The result
# will be a matrix of shape (batch_size, hidden)
#
for _ in range(iterations):
#
# Run one Gibbs sampling step and obtain new values
# for visible units and previous expectation values
#
Vb, E = self.runGibbsStep(V, batch_size)
#
# Calculate new expectation values
#
Eb = expit(self.beta*(np.matmul(Vb, self.W) + self.c))
#
# Calculate contributions of positive and negative phase
# and update weights and bias
#
pos = np.tensordot(V, E, axes=((0),(0)))
neg = np.tensordot(Vb, Eb, axes=((0),(0)))
dW = step*self.beta*(pos -neg) / float(batch_size)
self.W += dW
self.b += step*self.beta*np.sum(V - Vb, 0) / float(batch_size)
self.c += step*self.beta*np.sum(E - Eb, 0) / float(batch_size)
Let us now play around with this network a bit and visualize the training results. To do this, clone my repository and then run the simulation using
$ git clone https://github.com/christianb93/MachineLearning.git $ cd MachineLearning $ python RBM.py --run_reconstructions=1 --show_metrics=1
This will train a restricted Boltzmann machine on 20 images out of the BAS dataset with N=6. For the training, I have used standard parameters (which you can change using the various command line switches, use --help to see which parameters are available). The learning rate was set to 0.05. The number of iterations during training was set to 30.000, and 16 hidden units are used. The inverse temperature 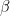
After every 500 iterations, the script prints out the current value of the reconstruction error. This is defined to be the norm of the difference between the value of the visible units when the Gibbs sampling step starts and the value after completing the Gibbs sampling step, i.e. this quantity measures how well the network is able to reconstruct the value of the visible units from the hidden units alone.
After the training phase is completed, the script will select eight patterns randomly. For each of these patterns, it will flip a few bits and then run 100 Gibbs sampling steps. If the training was successful, we expect that the result will be a reconstruction of the original image, i.e. the network would be able to match the distorted images to the original patterns.
When all the calculations have been completed, the network will display two images. The first image should roughly look like the image below.

This matrix visualizes the result of the reconstruction process described above. Each of the rows shows the outcome for one of the eight selected patterns. The first image in each row is the original pattern from the BAS data set. The second one is the distorted image some pixels have been flipped. The third image shows the result of the reconstruction run after 50 Gibbs iterations, and the last image shows the result after the full 100 iterations.
We see that in most cases, the network is able to correctly reconstruct the original image. However, there are also a fes rows that look suspicious. In the first row, we could hope that the network eventually converges if we execute more sampling steps. In the third row, however, the network converges to a member of the BAS data set, but to the wrong one.
The second diagram that the script produces displays the change to the weights after each iteration and the reconstruction error.
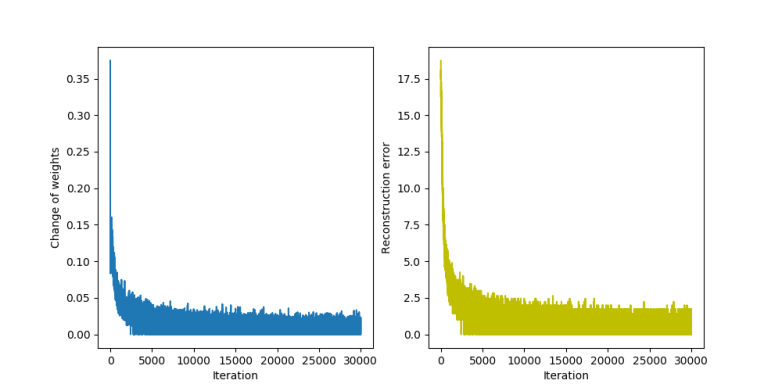
We see that both quantities quickly get smaller, but never stabilize at exactly zero. This is not really surprising – as we work with a non-zero temperature, we will always have some thermal fluctuations and the reconstruction error will never be constantly zero, but oscillate around a small value.
I invite you to play around with the parameters a bit to see how the network behaves. We can change the value of the inverse temperature with the parameter --beta, the number of hidden units with the parameter --hidden, the number of Gibbs steps used during the reconstruction with --sample and the step size with --step. If, for instance, you raise the temperature, the fluctuations of the reconstruction error will increase. If, one the other hand, we choose a very small temperature, the network converges very slowly. Making the step size too small or too large can also lead to non-convergence etc.
That completes this post on contrastive divergence. In the next post, I will show you an alternative algorithm that has gained a lot of popularity called persistent contrastive divergence (PCD), before we finally set out to implement an restricted Boltzmann machine on a GPU using the TensorFlow framework.
1. G. Hinton, Training products of experts by minimizing contrastive divergence, Journal Neural Computation Vol. 14, No. 8 (2002), 1771 1800
2. G. Hinton, A practical guide to training restricted Boltzmann machines, Technical Report University of Montreal TR-2010-003 (2010)
[3] D. MacKay, Information Theory, Inference and learning
algorithms, section 43, available online at this URL

2 Comments