
In the last post, we have looked at the contrastive divergence algorithm to train a restricted Boltzmann machine. Even though this algorithm continues to be very popular, it is by far not the only available algorithm. In this post, we will look at a different algorithm known as persistent contrastive divergence and apply it to the BAS data set and eventually to the MNIST data set.
Recall that one of the ideas of contrastive divergence is to use a pattern from the sample set as a starting point for a Gibbs sampler to calculate the contribution of the negative phase to the weight update. The idea behind persistent contrastive divergence (PCD), proposed first in [1], is slightly different. Instead of running a (very) short Gibbs sampler once for every iteration, the algorithm uses the final state of the previous Gibbs sampler as the initial start for the next iteration. Thus, in every iteration, we take the result from the previous iteration, run one Gibbs sampling step and save the result as starting point for the next iteration.
This amounts to running one long chain of states that are related by Gibbs sampling steps. Of course this is not exactly one longs Gibbs sampler, as the weights and therefore the probability distribution changes with each step. However, the idea is that when the learning rate is small, the weight change during two subsequent iterations is neglegible, and we effectively create one long Gibbs sampler which provides a good approximation to the actual distribution.
In practice, one often uses several chains that are run in parallel. Such a chain is sometimes called a negative particle. It is recommended in [1] to chose the number of particles to be equal to the batch size. In an implementation in Python, we can store the state of the negative particles in a matrix N where each row corresponds to one particle.
The idea to form one long Markov chain obviously works best if the learning rate is very small. On the other hand, this slows down the convergence of the gradient descent algorithm. In order to solve this, it is common to reduce the learning rate over time, for instance linearly with the number of iterations.
A second additional improvement that is usually implemented is a weight decay. Essentially, a weight decay is an additional penalty that is applied to avoid that the weights grow too large which would slow down the sampling procedure.
Let us now see how the PCD algorithm can be coded in Python. We will again store the model parameters and the state in a Python class. In the __init__ method of that class, we initialize the weights and the bias vectors and also set the particles to some randomly chosen initial value.
class PCDRBM (Base.BaseRBM):
def __init__(self, visible = 8, hidden = 3, particles = 10, beta=2.0):
self.visible= visible
self.hidden = hidden
self.beta = beta
self.particles = particles
#
# Initialize weights with a random normal distribution
#
self.W = np.random.normal(loc=0.0, scale=0.01, size=(visible, hidden))
#
# set bias to zero
#
self.b = np.zeros(dtype=float, shape=(1, visible))
self.c = np.zeros(dtype=float, shape=(1, hidden))
#
# Initialize the particles
#
self.N = np.random.randint(low=0, high=2, size=(particles,self.visible))
self.global_step = 0
Assuming that we have a method runGibbsStep that runs one Gibbs sampling step with the given weight starting at some initial state, one iteration of the PCD algorithm now looks as follows.
# # Update step size - we do this linearly over time # step = initial_step_size * (1.0 -(1.0*self.global_step)/(1.0*iterations*epochs)) # # First we compute the negative phase. We run the # Gibbs sampler for one step, starting at the previous state # of the particles self.N # self.N, _ = self.runGibbsStep(self.N, size=self.particles) # # and use this to calculate the negative phase # Eb = expit(self.beta*(np.matmul(self.N, self.W) + self.c)) neg = np.tensordot(self.N, Eb, axes=((0),(0))) # # Now we compute the positive phase. We need the # expectation values of the hidden units # E = expit(self.beta*(np.matmul(V, self.W) + self.c)) pos = np.tensordot(V, E, axes=((0),(0))) # # Now update weights # dW = step*self.beta*(pos -neg) / float(batch_size) - step*weight_decay*self.W / float(batch_size) self.W += dW self.b += step*self.beta*np.sum(V - self.N, 0) / float(batch_size) self.c += step*self.beta*np.sum(E - Eb, 0) / float(batch_size) self.global_step +=1
As always, the full source code is available from my machine learning GitHub repository. I have enhanced the code in RBM.py so that it accepts a command line parameter --algorithm that lets you choose between ordinary contrastive divergence and the PCD algorithm.
Let us now run a few trials. First, we will again use the BAS data set. You can download and run the code from the GitHub repository as follows.
$ git clone http://www.github.com/christianb93/MachineLearning.git $ cd MachineLearning $ python RBM.py --algorithm=PCD --run_reconstructions=1 --show_metrics=1
When the script completes, you should again see the two images. The first image displays how the reconstruction errors and weight changes behave during the training.
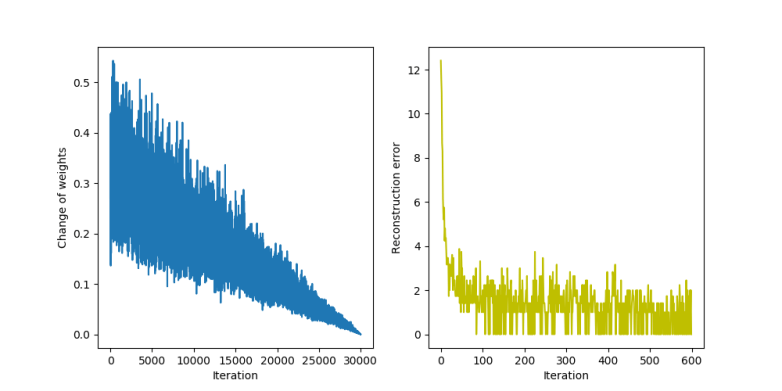
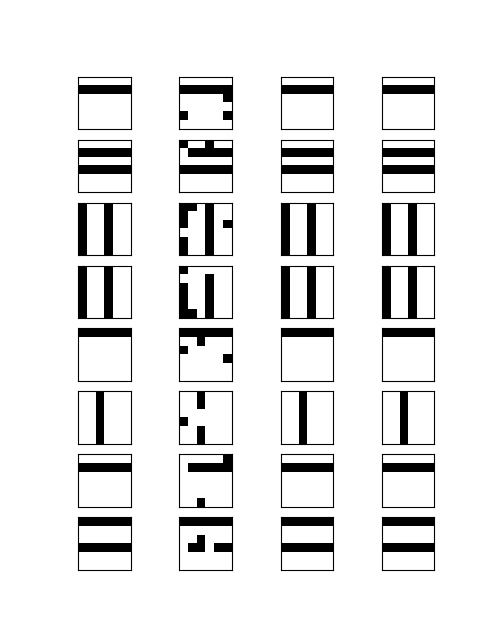
We see that the reconstruction error (the diagram on the right) decreases slower than it did for the ordinary contrastive divergence algorithm. On the left hand side, where the change of the weights is displayed, we can clearly see the impact of the linearly decreasing step size. The second picture shows again the result of a reconstruction attempt of slightly distorted patterns.
Let us now try out a different application of restricted Boltzmann machines – sampling. After a successful training phase, the model distribution given by the weights should be close to the empirical distribution of the training data. Thus, if we sample from the model distribution, using for instance Gibbs sampling, we should be able to obtain patterns. that somehow resemble the training data.
We will use this to generate handwritten digits based on the well known MNIST data set, more precisely the copy available at mldata.org. To download and read the data set, we use the method fetch_mldata provided by the scikit learn library. We will then train our network for 40.000 epochs using 60 images out of this data set and 128 hidden units and subsequently run 200.000 Gibbs sampling steps starting from a random pattern.
$ python RBM.py --algorithm=PCD --data=MNIST --N=28 --epochs=40000 --pattern=60 --hidden=128 --run_samples=1 --sample=200000 --save=1
Note that when you run this for the first time, the MNIST data set will be downloaded and stored in a folder in your home directory, so this might take some time (the file has a bit less than 60 MBytes).

The results are already very encouraging. Most patterns resemble a digit closely, only the image at the top left corner did obviously not converge properly. However, we still see a strong bias – only very few of the 9 digits that the data set contains appear. So we probably need to fine tune the parameters like number of hidden units, learning rate, weight decay or the number of epochs to obtain better results.
Unfortunately, when you start to play around to optimize this further, you will see that the run time of the algorithm has reached a point where quick iterations to try out different parameters become virtually impossible. I have been running this on my PC that has an Intel Core i7 CPU, and Python was able to distribute this nicely across all four physical cores, taking them to 100% utilization, but still the script was already running for 7 minutes. If we want to increase the number of iterations or the number of hidden units to be able to learn more pattern, the run time can easily go up to almost 30 minutes.
Of course professional training of neuronal networks is nowadays no longer been done on a CPU. Instead, modern frameworks use the power of graphical processing units (GPUs) that are optimized for exactly the type of work that we need – highly parallel processing of floating point matrices. Therefore, I will show you in the next post in this series how you can use the TensorFlow framework to move the workload to a GPU.
1. T. Tieleman, Training restricted Boltzmann machines using approximations to the likelihood gradient, International Conference on Machine Learning (ICML), 2008
2. A. Fischer, C. Igel, Training restricted Boltzmann machines: an introduction, Pattern Recognition Vol. 47 (2014), pp 25–39

1 Comment