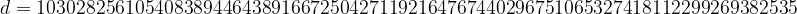In the last post in my series on bitcoin and the blockchain, we have successfully “dockerized” the bitcoin core reference implementation and have built the bitcoin-alpine docker container that contains a bitcoin server node on top of the Alpine Linux distribution. In this post, we will use this container image to build up and initialize a small network with three nodes.
First, we start a node that will represent the user Alice and manage her wallet.
$ docker run -it --name="alice" -h="alice" bitcoin-alpine
Note that we have started the container with the option -it so that it stays attached to the current terminal and we can see its output. Let us call this terminal terminal 1. We can now open a second terminal and attach to the running server and use the bitcoin CLI to verify that our server is running properly.
$ docker exec -it alice "sh" # bitcoin-cli -regtest --rpcuser=user --rpcpassword=password getinfo
If you run – as shown above – the bitcoin CLI inside the container using the getbalance RPC call, you will find that at this point, the balance is still zero. This not surprising, our network does not contain any bitcoins yet. To create bitcoins, we will now bring up a miner node and mine a certain amount of bitcoin. So in a third terminal, enter
$ docker run -it --name="miner" -h="miner" bitcoin-alpine
This will create a second node called miner and start a second instance of the bitcoin server within this network. Now, however, our two nodes are not yet connected. To change this, we can use the addnode command in the bitcoin CLI. So let us figure out how they can reach each other on the network. We have started both containers without any explicit networking options, so they will be connected to the default bridge network that Docker creates on your host. To figure out the IP addresses, run
$ docker network inspect bridge
on your host. This should produce a list of network devices in JSON format and spit out the IP addresses of the two nodes. In my case, the node alice has the IP address 172.17.0.2 and the miner has the IP address 172.17.0.3. So let us change back to terminal number 2 (attached to the container alice) and run
# bitcoin-cli -regtest --rpcuser=user --rpcpassword=password addnode 172.17.0.3 add
In the two terminal windows that are displaying the output of the two bitcoin daemons on the nodes alice and miner, you should now see an output similar to the following.
2018-03-24 14:45:38 receive version message: /Satoshi:0.15.0/: version 70015, blocks=0, us=[::]:0, peer=0
This tells you that the two peers have exchanged a version message and recognized each other. Now let us mine a few bitcoins. First attach a terminal to the miner node – this will be terminal four.
$ docker exec -it miner "sh"
In that shell, enter the following command
# bitcoin-cli -regtest --rpcuser=user --rpcpassword=password generate 101 # bitcoin-cli -regtest --rpcuser=user --rpcpassword=password getbalance
You should now see a balance of 50 bitcoins. So we have mined 50 bitcoins (in fact, we have mined much more, but it requires additional 100 blocks before a mined transaction is considered to be part of the balance and therefore only the amount of 50 bitcoins corresponding to the very first block shows up).
This is already nice, but when you execute the RPC method getbalance in terminal two, you will still find that Alice balance is zero – which is not surprising, after all the bitcoins created so far have been credited to the miner, not to Alice. To change this, we will now transfer 30 bitcoin to Alice. As a first step, we need to figure out what Alice address is. Each wallet maintains a default account, but we can add as many accounts as we like. So let us now add an account called “Alice” on the alice node. Execute the following command in terminal two which is attached to the container alice.
# bitcoin-cli -regtest --rpcuser=user --rpcpassword=password getnewaddress "Alice"
The output should be something like mkvAYmgqrEFEsJ9zGBi9Z87gP5rGNAu2mx which is the bitcoin address that the wallet has created. Of course you will get a different address, as the private key behind that address will be chosen randomly by the wallet. Now switch to the terminal attached to the miner node (terminal four). We will now transfer 30 bitcoin from this node to the newly created address of Alice.
# bitcoin-cli -regtest --rpcuser=user --rpcpassword=password sendtoaddress "mkvAYmgqrEFEsJ9zGBi9Z87gP5rGNAu2mx" 30.0
The output will be the transaction ID of the newly created transaction, in my case this was
2bade389ac5b3feabcdd898b8e437c1d464987b6ac1170a06fcb24ecb24986a8
If you now display the balances on both nodes again, you will see that the balance in the default account on the miner node has dropped to something a bit below 20 (not exactly 20, because the wallet has added a fee to the transaction). The balance of Alice, however, is still zero. The reason is that the transaction does not yet count as confirmed. To confirm it, we need to mine six additional blocks. So let us switch to the miners terminal once more and enter
# bitcoin-cli -regtest --rpcuser=user --rpcpassword=password generate 6
If you now display the balance on the node alice, you should find that the balance is now 30.
Congratulations – our setup is complete, we have run our first transaction and now have plenty of bitcoin in a known address that we can use. To preserve this wonderful state of the world, we will now create two new images that contain snapshots of the nodes so that we have a clearly defined state to which we can always return when we run some tests and mess up our test data. So switch back to a terminal on your host and enter the following four commands.
$ docker stop miner $ docker stop alice $ docker commit miner miner $ docker commit alice alice
If you now list the available images using docker images, you should see two new images alice and miner. If you want, you can now remove the stopped container instances using docker rm.
Now let us see how we can talk to a running server in Python. For that purpose, let us start a detached container using our brand new alice image.
$ docker run -d --rm --name=alice -p 18332:18332 alice
We can now communicate with the server using RPC requests. The bitcoin RPC interface follows the JSON RPC standard. Using the powerful Python package requests, it is not difficult to write a short function that submits a request and interprets the result.
def rpcCall(method, params = None, port=18332, host="localhost", user="user", password="password"):
#
# Create request header
#
headers = {'content-type': 'application/json'}
#
# Build URL from host and port information
#
url = "http://" + host + ":" + str(port)
#
# Assemble payload as a Python dictionary
#
payload = {"method": method, "params": params, "jsonrpc": "2.0", "id": 1}
#
# Create and send POST request
#
r = requests.post(url, json=payload, headers=headers, auth=(user, password))
#
# and interpret result
#
json = r.json()
if 'result' in json and json['result'] != None:
return json['result']
elif 'error' in json:
raise ConnectionError("Request failed with RPC error", json['error'])
else:
raise ConnectionError("Request failed with HTTP status code ", r.status_code)
If have added this function to my btc bitcoin library within the module utils. We can use this function in a Python program or an interactive ipython session similar to the bitcoin CLI client. The following ipython session demonstrates a few calls, assuming that you have cloned the repository.
In [1]: import btc.utils
In [2]: r = btc.utils.rpcCall("listaccounts")
In [3]: r
Out[3]: {'': 0.0, 'Alice': 30.0}
In [4]: r = btc.utils.rpcCall("dumpprivkey", ["mkvAYmgqrEFEsJ9zGBi9Z87gP5rGNAu2mx"])
In [5]: r
Out[5]: 'cQowgjRpUocje98dhJrondLbHNmgJgAFKdUJjCTtd3VeMfWeaHh7'
We are now able to start our test network at any time from the saved docker images and communicate with it using RPC calls in Python. In the next post, we will see how a transaction is created, signed and propagated into the test network.

![\Delta W_{ij} = \beta \left[ \langle v_i \sigma(\beta a_j) \rangle_{\mathcal D} - \langle v_i \sigma(\beta a_j) \rangle_{P(v)} \right]](https://s0.wp.com/latex.php?latex=%5CDelta+W_%7Bij%7D+%3D+%5Cbeta+%5Cleft%5B+%5Clangle+v_i+%5Csigma%28%5Cbeta+a_j%29+%5Crangle_%7B%5Cmathcal+D%7D+-+%5Clangle+v_i+%5Csigma%28%5Cbeta+a_j%29+%5Crangle_%7BP%28v%29%7D+%5Cright%5D++&bg=FFFFFF&fg=000&s=1&c=20201002)
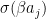 that appears several times is simply the conditional probability for the hidden unit j to be “on” and, as only the values 0 and 1 are possible, at the same time the conditional expectation value of that unit given the values of the visible units – let us denote this quantity by
that appears several times is simply the conditional probability for the hidden unit j to be “on” and, as only the values 0 and 1 are possible, at the same time the conditional expectation value of that unit given the values of the visible units – let us denote this quantity by 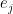 . Our update rule now reads
. Our update rule now reads![\Delta W_{ij} = \beta \left[ \langle v_i e_j \rangle_{\mathcal D} - \langle v_i e_j \rangle_{P(v)} \right]](https://s0.wp.com/latex.php?latex=%5CDelta+W_%7Bij%7D+%3D+%5Cbeta+%5Cleft%5B+%5Clangle+v_i+e_j+%5Crangle_%7B%5Cmathcal+D%7D+-+%5Clangle+v_i+e_j+%5Crangle_%7BP%28v%29%7D+%5Cright%5D++&bg=FFFFFF&fg=000&s=1&c=20201002)
 after each step and take the average of these values.
after each step and take the average of these values.
 with probability
with probability  with probability
with probability 

![W = W + \lambda \beta \left[ v e^T - \bar{v} \bar{e}^T \right]](https://s0.wp.com/latex.php?latex=W+%3D+W+%2B+%5Clambda+%5Cbeta+%5Cleft%5B+v+e%5ET+-+%5Cbar%7Bv%7D+%5Cbar%7Be%7D%5ET+%5Cright%5D+&bg=FFFFFF&fg=000&s=0&c=20201002)
![b = b + \lambda \beta \left[ v - \bar{v} \right]](https://s0.wp.com/latex.php?latex=b+%3D+b+%2B+%5Clambda+%5Cbeta+%5Cleft%5B+v+-+%5Cbar%7Bv%7D+%5Cright%5D+&bg=FFFFFF&fg=000&s=0&c=20201002)
![c = c + \lambda \beta \left[ e - \bar{e} \right]](https://s0.wp.com/latex.php?latex=c+%3D+c+%2B+%5Clambda+%5Cbeta+%5Cleft%5B+e+-+%5Cbar%7Be%7D+%5Cright%5D+&bg=FFFFFF&fg=000&s=0&c=20201002)
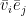 is then the contribution of the negative phase to the update of
is then the contribution of the negative phase to the update of 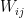 . We can summarize the contributions for all pairs of indices as the matrix
. We can summarize the contributions for all pairs of indices as the matrix  . Similarly, the positive phase contributes with
. Similarly, the positive phase contributes with  . In the next line, we update W with both contributions, where
. In the next line, we update W with both contributions, where 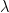 is the learning rate. We then apply similar update rules to the bias for visible and hidden units – the derivation of these update rules from the expression for the likelihood function is done similar to the derivation of the update rules for the weights as shown in my last post.
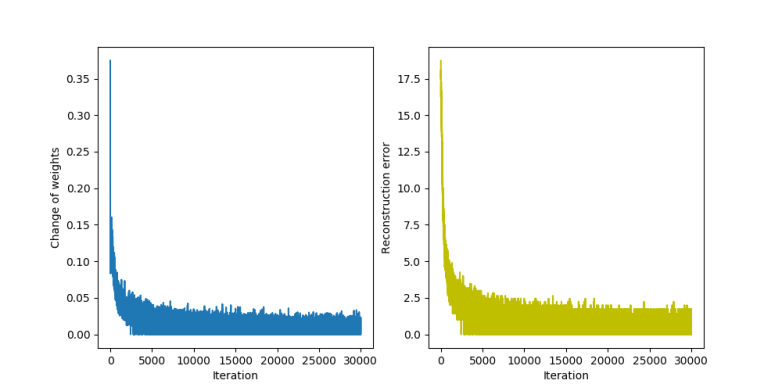
is the learning rate. We then apply similar update rules to the bias for visible and hidden units – the derivation of these update rules from the expression for the likelihood function is done similar to the derivation of the update rules for the weights as shown in my last post.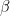 is set to 2.0. In each iteration, a mini-batch of 10 patterns is trained.
is set to 2.0. In each iteration, a mini-batch of 10 patterns is trained.



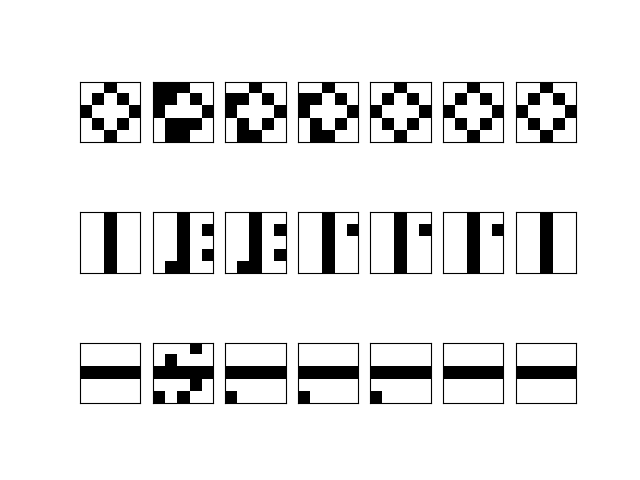

 patterns, where N is the number of units. In our case, with 25 units, this would be approximately 3 to 4 patterns.
patterns, where N is the number of units. In our case, with 25 units, this would be approximately 3 to 4 patterns. 

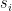 .
.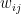 is the strength of the connection between the units i and j. We assume that no neuron is connected to ifself, i.e. that
is the strength of the connection between the units i and j. We assume that no neuron is connected to ifself, i.e. that  , and that the matrix of weights is symmetric, i.e. that
, and that the matrix of weights is symmetric, i.e. that 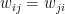 .
.

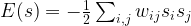
 . Let
. Let


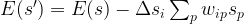
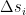 and the activation of unit i is never negative, this implies that during the upgrade process, the energy function will always increase or stay the same. Thus the state will settle in a local minimum of the energy function.
and the activation of unit i is never negative, this implies that during the upgrade process, the energy function will always increase or stay the same. Thus the state will settle in a local minimum of the energy function.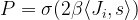

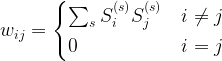
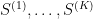 are the states that the network should remember (in a later post in this series, we will see that this rule can be obtained as the low temperature limit of a training algorithm called contrastive divergence that is used to train a certain class of Boltzmann machines).
are the states that the network should remember (in a later post in this series, we will see that this rule can be obtained as the low temperature limit of a training algorithm called contrastive divergence that is used to train a certain class of Boltzmann machines). and
and 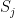 have the same sign, i.e. are in the same state. This corresponds to a rule known as Hebbian learning rule that has been postulated as a principle of learning by D. Hebb and basically states that during learning, connections between neurons are enforced if these neurons fire together (
have the same sign, i.e. are in the same state. This corresponds to a rule known as Hebbian learning rule that has been postulated as a principle of learning by D. Hebb and basically states that during learning, connections between neurons are enforced if these neurons fire together (

 .
. .
.