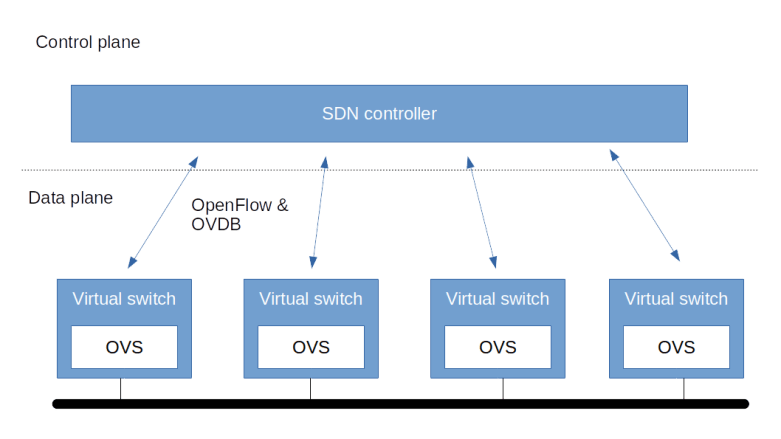
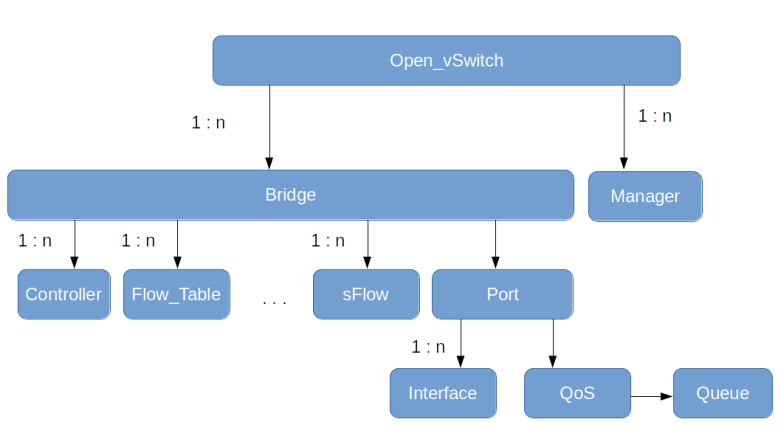
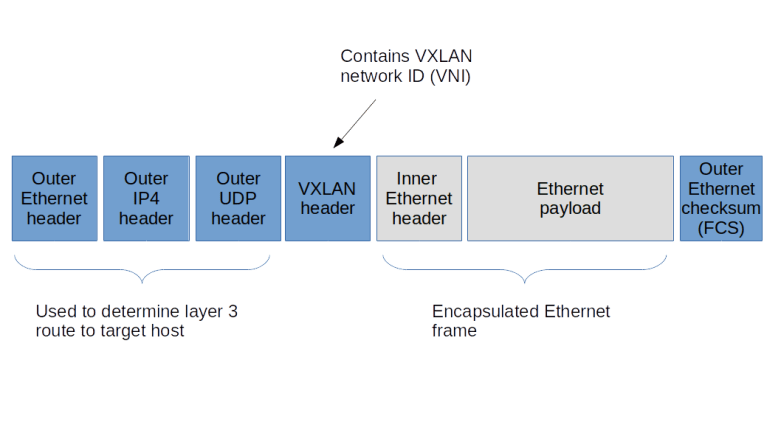
In the last post, we have discussed the architecture of Open vSwitch and how it with a control plane to realize an SDN. Today, we will make this a bit more tangible by running two hands-on labs with OVS.
The labs in this post are modelled after some of the How-to documents that are part of the Open vSwitch documentation, but use a combination of virtual machines and Docker to avoid the need for more than one physical machine. In both labs, we bring up two virtual machines which are connected via a VirtualBox virtual network, and inside each machine, we bring up two Docker containers that will eventually interact via OVS bridges.
Lab 11: setting up an overlay network with Open vSwitch
In the first lab, we will establish interaction between the OVS bridges on the two involved virtual machines using an overlay network. Specifically, the Docker containers on each VM will be connected to an OVS bridge, and the OVS bridges will use VXLAN to talk to each other, so that effectively, all Docker containers appear to be connected to an Ethernet network spanning the two virtual machines.

Instead of going through all steps required to set this up, we will again bring up the machines automatically using a combination of Vagrant and Ansible, and then discuss the major steps and the resulting setups. To run the lab, you will again have to download the code from my repository and start Vagrant.
git clone https://github.com/christianb93/networking-samples cd lab11 vagrant up
While this is running, let us quickly discuss what the scripts are doing. First, of course, we create two virtual machines, each running Ubuntu Bionic. In each machine, we install Open vSwitch and Docker. We then install the docker Python3 module to make Ansible happy.
Next, we bring up two Docker containers, each running an image which is based on NGINX but has some networking tools installed on top. For each container, we set up a pair of two VETH devices. One of the devices is then moved into the networking namespace of the container, and one of the two devices will later be added to our bridge, so that these VETH device pairs effectively operate like an Ethernet cable connecting the containers to the bridge.
We then create the OVS bridge. In the Ansible script, we use the Ansible OVS module to do this, but if you wanted to create the bridge manually, you would use a command like
ovs-vsctl add-br myBridge \
-- add-port myBridge web1_veth1 \
-- add-port myBridge web2_veth1
This is actually a combination of three commands (i.e updates on the OVSDB database) which will be run in one single transaction (the OVS CLI uses the double dashes to combine commands into one transaction). With the first part of the command, we create a virtual OVS bridge called myBridge. With the second and third line, we then add two ports, connected to the two VETH pairs that we have created earlier.
Once the bridge exists and is connected to the containers, we add a third port, which is a VLXAN port, which, using a manual setup, would be the result of the following commands.
ovs-vsctl add-port myBridge vxlan0 \\
-- set interface vxlan0 type=vxlan options:remote_ip=192.168.50.4 options:dst_port=4789 options:ttl=5
Again, we atomically add the port to the bridge and pass the VXLAN options. We set up the VTEP as a point-to-point connection to the second virtual machine, using the standard UDP port and a TTL of five to avoid that UDP packets get lost.
Finally, we configure the various devices and assign IP addresses. To configure the devices in the container namespaces, we could attach to the containers, but it is easier to use netns to run the required commands within the container namespaces.
Once the setup is complete, we are ready to explore the newly created machines. First, use vagrant ssh boxA to log into boxA. From there, use Docker exec to attach to the first container.
sudo docker exec -it web1 "/bin/bash"
You should now be able to ping all other containers, using the IP addresses 172.16.0.2 – 172.16.0.4. If you run arp -n inside the container, you will also find that all three IP addresses are directly resolved into MAC addresses and are actually present on the same Ethernet segment.
To inspect the bridges that OVS has created, exit the container again so that we are now back in the SSH session on boxA and use the command line utility ovs-vsctl to list all bridges.
sudo ovs-vsctl list-br
This will show us one bridge called myBridge, as expected. To get more information, run
sudo ovs-vsctl show
This will print out the full configuration of the current OVS node. The output should look similar to the following snippet.
af3a2230-3d2a-4364-a0b9-1da4e32211e4
Bridge myBridge
Port "web2_veth1"
Interface "web2_veth1"
Port "vxlan0"
Interface "vxlan0"
type: vxlan
options: {dst_port="4789", remote_ip="192.168.50.5", ttl="5"}
Port "web1_veth1"
Interface "web1_veth1"
Port myBridge
Interface myBridge
type: internal
ovs_version: "2.9.2"
We can see that the output nicely reflects the structure of our network. There is one bridge, with three ports – the two VETH ports and the VXLAN port. We also see the parameters of the VXLAN ports that we have specified during creation. It is also possible to obtain the content of the OVSDB tables that correspond to the various objects in JSON format.
sudo ovs-vsctl list bridge sudo ovs-vsctl list port sudo ovs-vsctl list interface
Lab 12: VLAN separation with Open vSwitch
In this lab, we will use a setup which is very similar to the previous one, but with the difference that we use layer 2 technology to span our network across the two virtual machines. Specifically, we establish two VLANs with ids 100 (containing web1 and web3) and 200 (containing the other two containers). On those two logical Ethernet networks, we establish two different layer 3 networks – 192.168.50.0/24 and 192.168.60.0/24.

The first part of the setup – bringing up the containers and creating the VETH pairs – is very similar to the previous labs. Once this is done, we again set up the two bridges. On boxA, this would be done with the following sequence of commands.
sudo ovs-vsctl add-br myBridge sudo ovs-vsctl add-port myBridge enp0s8 sudo ovs-vsctl add-port myBridge web1_veth1 tag=100 sudo ovs-vsctl add-port myBridge web2_veth1 tag=200
This will create a new bridge and first add the VM interface enp0s8 to it. Note that by default, every port added to OVS is a trunk port, i.e. the traffic will carry VLAN tags. We then add the two VETH ports with the additional parameter tag which will mark the port as an access port and define the corresponding VLAN ID.
Next we need to fix our IP setup. We need to remove the IP address from the enp0s8 as this is now part of our bridge, and set the IP address for the two VETH devices inside the containers.
sudo ip addr del 192.168.50.4 dev enp0s8
web1PID=$(sudo docker inspect --format='{{.State.Pid}}' web1)
sudo nsenter -t $web1PID -n ip addr add 192.168.50.1/24 dev web1_veth0
web2PID=$(sudo docker inspect --format='{{.State.Pid}}' web2)
sudo nsenter -t $web2PID -n ip addr add 192.168.60.2/24 dev web2_veth0
Finally, we need to bring up the devices.
sudo nsenter -t $web1PID -n ip link set web1_veth0 up sudo nsenter -t $web2PID -n ip link set web2_veth0 up sudo ip link set web1_veth1 up sudo ip link set web2_veth1 up
The setup of boxB proceeds along the following lines. In the lab, we again use Ansible scripts to do all this, but if you wanted to do it manually, you would have to run the following on boxB.
sudo ovs-vsctl add-br myBridge
sudo ovs-vsctl add-port myBridge enp0s8
sudo ovs-vsctl add-port myBridge web3_veth1 tag=100
sudo ovs-vsctl add-port myBridge web4_veth1 tag=200
sudo ip addr del 192.168.50.5 dev enp0s8
web3PID=$(sudo docker inspect --format='{{.State.Pid}}' web3)
sudo nsenter -t $web3PID -n ip addr add 192.168.50.3/24 dev web3_veth0
web4PID=$(sudo docker inspect --format='{{.State.Pid}}' web4)
sudo nsenter -t $web4PID -n ip addr add 192.168.60.4/24 dev web4_veth0
sudo nsenter -t $web3PID -n ip link set web3_veth0 up
sudo nsenter -t $web4PID -n ip link set web4_veth0 up
sudo ip link set web3_veth1 up
sudo ip link set web4_veth1 up
Instead of manually setting up the machines, I have of course again composed a couple of Ansible scripts to do all this. To try this out, run
git clone https://github.com/christianb93/networking-samples cd lab12 vagrant up
Now log into one of the boxes, say boxA, attach to the web1 container and try to ping web3 and web4.
vagrant ssh boxA sudo docker exec -it web1 /bin/bash ping 192.168.50.3 ping 192.168.60.4
You should see that you can get a connection to web3, but not to web4. This is of course what we expect, as the VLAN tagging is supposed to separate the two networks. To see the VLAN tags, open a second session on boxA and enter
sudo tcpdump -e -i enp0s8
When you now repeat the ping, you should see that the traffic generated from within the container web1 carries the VLAN tag 100. This is because the port to which enp0s8 is attached has been set up as a trunk port. If you stop the dump and start it again, but this time listening on the device web1_veth1 which we have added to the bridge as an access port, you should see that no VLAN tag is present. Thus the bridge operates as expected by adding the VLAN tag according to the tag of the access port on which the traffic comes in.
In the next post, we will start to explore another important feagure of OVS – controlling traffic using flows.