Its been a few days since I started to play with Paperspace, and I have come across a couple of interesting features that the platform has – enough for a second post on this topic.
First, GIT integration. Recall that the usual process is to zip the current working directory and submit the resulting file along with the job, the ZIP file is then unzipped in the container in which the job is running and the contents of the ZIP file constitute the working directory. However, if you want to run code that requires, for instance, custom libraries, it is much easier to instruct Paperspace to get the contents of the working directory from GitHub. You can do that by supplying a GIT URL using the --workspace switch. The example below, for instance, instructs Paperspace to pull my code for an RBM from GitHub and to run it as a job.
#!/bin/sh
#
# Run the RBM as a job on Paperspace. Assume that you have the paperspace NodeJS
# CLI and have done a paperspace login before to store your credentials
#
#
~/node_modules/.bin/paperspace jobs create \
--workspace "git+https://github.com/christianb93/MachineLearning" \
--command "export MPLBACKEND=AGG ; python3 RBM.py \
--N=28 --data=MNIST \
--save=1 \
--tmpdir=/artifacts \
--hidden=128 \
--pattern=256 --batch_size=128 \
--epochs=40000 \
--run_samples=1 \
--sample_size=6,6 \
--beta=1.0 --sample=200000 \
--algorithm=PCDTF --precision=32" \
--machineType K80 \
--container "paperspace/tensorflow-python" \
--project "MachineLearning"
Be careful, the spelling of the URL must be exactly like this to be recognized as a GIT URL, i.e. “git+https” followed by the hostname without the “www”, if you use http instead of https or http://www.github.com instead of github.com, the job will fail (the documentation at this point could be better, and I have even had to look at the source code of the CLI to figure out the syntax). This is a nice feature, using that along with the job logs, I can easily reconstruct which version of the code has actually been executed, and it supports working in a team that is sharing GitHub repositories well.
Quite recently, Paperspace did apparently also add the option to use persistent storage in jobs to store data across job runs (see this announcement). Theoretically, the storage should be shared between notebooks and jobs in the same region, but as I have not yet found out how to start a notebook in a specific region, I could not try this out.
Another feature that I liked is that the container that you specify can actually be any container from the Docker Hub, for instance ubuntu. The only restriction is that Paperspace seems to overwrite the entrypoint in any case and will try to run bashinside the container to finally execute the command that you provide, so containers that do not have a bash in the standard execution path will not work. Still, you could use this to prepare your own containers, maybe with pre-installed data sets or libraries, and ask Paperspace to run them.
Finally, for those of us who are Python addicts, there is also a Python API for submitting and managing jobs in Paperspace. Actually, this API offers you two ways to run a Python script on Paperspace. First, you can import the paperspace package into your script and then, inside the script, do a paperspace.run(), as in the following example.
import paperspace
paperspace.run()
print('This will only be running on Paperspace')
What will happen behind the scenes is that the paperspace module takes your code, removes any occurrences of the paperspace package itself, puts the code into a temporary file and submits that as a job to Paperspace. You can then work with that job as with any other job, like monitoring it on the console or via the CLI.
That is nice and easy, but not everyone likes to hardcode the execution environment into the code. Fortunately, you can also simply import the paperspace package and use it to submit an arbitrary job, much like the NodeJs based CLI can do it. The code below demonstrates how to create a job using the Python API and download the output automatically (this script can also be found on GitHub).
import paperspace.jobs
from paperspace.login import apikey
import paperspace.config
import requests
#
# Define parameters
#
params = {}
#
# We want to use GIT, so we use the parameter workspaceFileName
# instead of workspace
#
params['workspaceFileName'] = "git+https://github.com/christianb93/MachineLearning"
params['machineType'] = "K80"
params['command'] = "export MPLBACKEND=AGG ; python3 RBM.py \
--N=28 --data=MNIST \
--save=1 \
--tmpdir=/artifacts \
--hidden=128 \
--pattern=256 --batch_size=128 \
--epochs=40000 \
--run_samples=1 \
--sample_size=6,6 \
--beta=1.0 --sample=200000 \
--algorithm=PCDTF --precision=32"
params['container'] = 'paperspace/tensorflow-python'
params['project'] = "MachineLearning"
params['dest'] = "/tmp"
#
# Get API key
#
apiKey = apikey()
print("Using API key ", apiKey)
#
# Create the job. We do NOT use the create method as it cannot
# handle the GIT feature, but assemble the request ourselves
#
http_method = 'POST'
path = '/' + 'jobs' + '/' + 'createJob'
r = requests.request(http_method, paperspace.config.CONFIG_HOST + path,
headers={'x-api-key': apiKey},
params=params, files={})
job = r.json()
if 'id' not in job:
print("Error, could not get jobId")
print(job)
exit(1)
jobId = job['id']
print("Started job with jobId ", jobId)
params['jobId'] = jobId
#
# Now poll until the job is complete
if job['state'] == 'Pending':
print('Waiting for job to run...')
job = paperspace.jobs.waitfor({'jobId': jobId, 'state': 'Running'})
print("Job is now running")
print("Use the following command to observe its logs: ~/node_modules/.bin/paperspace jobs logs --jobId ", jobId, "--tail")
job = paperspace.jobs.waitfor({'jobId': jobId, 'state': 'Stopped'})
print("Job is complete: ", job)
#
# Finally get artifacts
#
print("Downloading artifacts to directory ", params['dest'])
paperspace.jobs.artifactsGet(params)
There are some additional features that the Python API seems to have that I have not yet tried out. First, you can apparently specify an init script that will be run before the command that you provide (though the use of that is limited, as you could put this into your command as well). Second, and more important, you can provide a requirements file according to the pip standard to ask Paperspace to install any libraries that are not available in the container before running your command.
Overall, my impression is that these APIs make it comparatively easy to work with jobs on Paperspace. You can submit jobs, monitor them and get their outputs, and you enjoy the benefit that you are only billed for the actual duration of the job. So if you are interested in a job based execution environment for your Machine Learning models, it is definitely worth a try, even though it takes some time to get familiar with the environment.

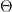 , in practice this could be weights, bias terms or any other parameters. To simplify things a bit, we will also assume that the latent variable is finite. Our aim is to maximize the log likelihood, which we can – under these assumptions – express as follows.
, in practice this could be weights, bias terms or any other parameters. To simplify things a bit, we will also assume that the latent variable is finite. Our aim is to maximize the log likelihood, which we can – under these assumptions – express as follows.
 . For that purpose, we introduce a term that is traditionally called Q and defined as follows (all this is a bit abstract, but will become clearer later when we do an example):
. For that purpose, we introduce a term that is traditionally called Q and defined as follows (all this is a bit abstract, but will become clearer later when we do an example):![Q(\Theta'; \Theta) = E \left[ \ln P(x,z | \Theta') | x, \Theta \right]](https://s0.wp.com/latex.php?latex=Q%28%5CTheta%27%3B+%5CTheta%29+%3D+E+%5Cleft%5B++%5Cln+P%28x%2Cz+%7C+%5CTheta%27%29++%7C+x%2C+%5CTheta+%5Cright%5D++&bg=FFFFFF&fg=000&s=1&c=20201002)
 of z. Thus the right hand side is, spelled out
of z. Thus the right hand side is, spelled out![E \left[ \ln P(x,z | \Theta') | x, \Theta \right] = \sum_z \ln P(x,z | \Theta') P(z | x, \Theta)](https://s0.wp.com/latex.php?latex=E+%5Cleft%5B++%5Cln+P%28x%2Cz+%7C+%5CTheta%27%29++%7C+x%2C+%5CTheta+%5Cright%5D+%3D+%5Csum_z+%5Cln+P%28x%2Cz+%7C+%5CTheta%27%29+P%28z+%7C+x%2C+%5CTheta%29++&bg=FFFFFF&fg=000&s=1&c=20201002)
 of parameters such that when passing from
of parameters such that when passing from  to
to  , the value of Q does not decrease, i.e.
, the value of Q does not decrease, i.e.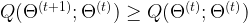

 is maximized. This part of the algorithm is therefore called the maximization step. Then we start over, using
is maximized. This part of the algorithm is therefore called the maximization step. Then we start over, using 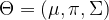
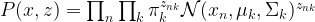

 and
and  . Using this notation, we can now write down the result of calculating the Q function:
. Using this notation, we can now write down the result of calculating the Q function: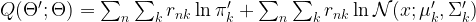
 . For a fixed
. For a fixed  and
and  , and we can now try to maximize this function with respect to these parameters. This calculation is not difficult, but again a bit tiresome (and requires the use of Lagrangian multipliers as there is a constraint on the
, and we can now try to maximize this function with respect to these parameters. This calculation is not difficult, but again a bit tiresome (and requires the use of Lagrangian multipliers as there is a constraint on the 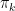 ), and I again refer to
), and I again refer to 
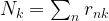


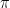 , the covariance matrices
, the covariance matrices  and the means
and the means  – which could, for instance, be chosen randomly. Then, we calculate the responsibilities as above – essentially, this is the expectation step, as it amounts to finding Q.
– which could, for instance, be chosen randomly. Then, we calculate the responsibilities as above – essentially, this is the expectation step, as it amounts to finding Q. 
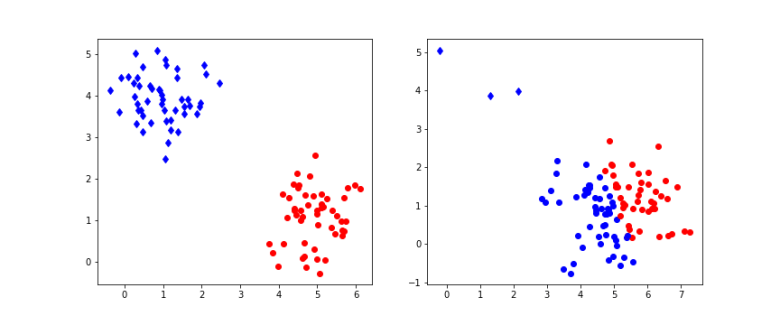
 of points in some euclidian space and a number K of clusters. We want to identify the centre
of points in some euclidian space and a number K of clusters. We want to identify the centre 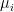 of each cluster and then assign the data points xi to some of the
of each cluster and then assign the data points xi to some of the  , namely to the
, namely to the 

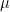 of cluster centers, we can easily minimize Rij by assigning each data point to the cluster whose center is closest to xi. Thus we set
of cluster centers, we can easily minimize Rij by assigning each data point to the cluster whose center is closest to xi. Thus we set

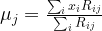

 is a multivariate Gaussian distribution with mean
is a multivariate Gaussian distribution with mean 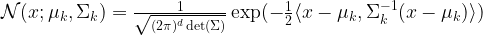
 .
. with the additional constraint that only one of the Zk is allowed to be different from zero. We interpret
with the additional constraint that only one of the Zk is allowed to be different from zero. We interpret 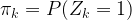


 is as above and
is as above and
 . As we already have k, this amounts to sampling from the Gaussian distribution
. As we already have k, this amounts to sampling from the Gaussian distribution 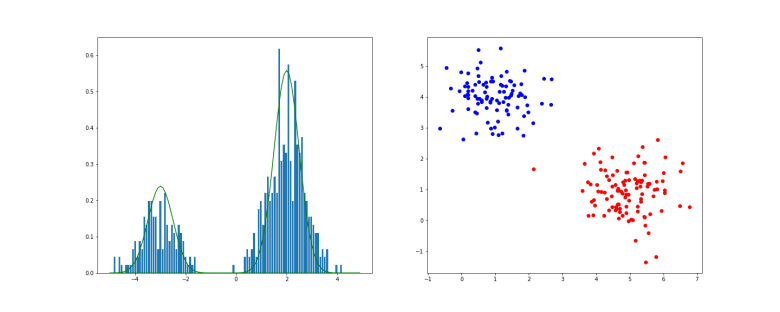


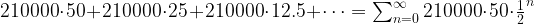
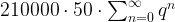
 . This series converges, and its value is
. This series converges, and its value is
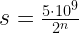
 for n, we obtain
for n, we obtain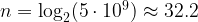
 .
.

 . Another data point the network could get is
. Another data point the network could get is

 to be a bird is a function of the Xi. In other words, using the language of conditional probabilities,
to be a bird is a function of the Xi. In other words, using the language of conditional probabilities,
 with a vector valued random variable X. The attributes of a sample are described by the feature vector X in some subset of m-dimensional euclidian space, where m is the number of different features. In our example, m=2, as we try to classify animals based on two properties. The result of the classification is described by a random variable Y taking – for the simple case of a binary classification problem – values in
with a vector valued random variable X. The attributes of a sample are described by the feature vector X in some subset of m-dimensional euclidian space, where m is the number of different features. In our example, m=2, as we try to classify animals based on two properties. The result of the classification is described by a random variable Y taking – for the simple case of a binary classification problem – values in 
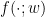 is a function parametrized by some parameter w that we call the weights of the model. The actual value w0 of w is unknown. Based on a sample for X and Y, we then try to fit the model, i.e. we try to find a value for w such that
is a function parametrized by some parameter w that we call the weights of the model. The actual value w0 of w is unknown. Based on a sample for X and Y, we then try to fit the model, i.e. we try to find a value for w such that  models the actual conditional distribution of Y as good as possible. Once the fitting phase is completed, we can then use the model to derive predictions about objects which are not in our initial sample set.
models the actual conditional distribution of Y as good as possible. Once the fitting phase is completed, we can then use the model to derive predictions about objects which are not in our initial sample set.


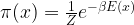
 for a single point in the state space intractable.
for a single point in the state space intractable.

 .
. 

 . We now calculate
. We now calculate 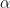 according to the formula above. We then accept the proposal with probability
according to the formula above. We then accept the proposal with probability  . If the proposal is accepted, we set xn+1 = y, otherwise we set xn+1 = xn, i.e. we stay where we are.
. If the proposal is accepted, we set xn+1 = y, otherwise we set xn+1 = xn, i.e. we stay where we are.

 with probability one. This is very similar to a random search for a global maximum – we start at some point x, choose a candidate for a point with higher value of
with probability one. This is very similar to a random search for a global maximum – we start at some point x, choose a candidate for a point with higher value of 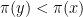 with a non-zero probability. This allows the algorithm to escape a local maximum much better. Intuitively, the algorithm will still try to spend more time in regions with large values of
with a non-zero probability. This allows the algorithm to escape a local maximum much better. Intuitively, the algorithm will still try to spend more time in regions with large values of 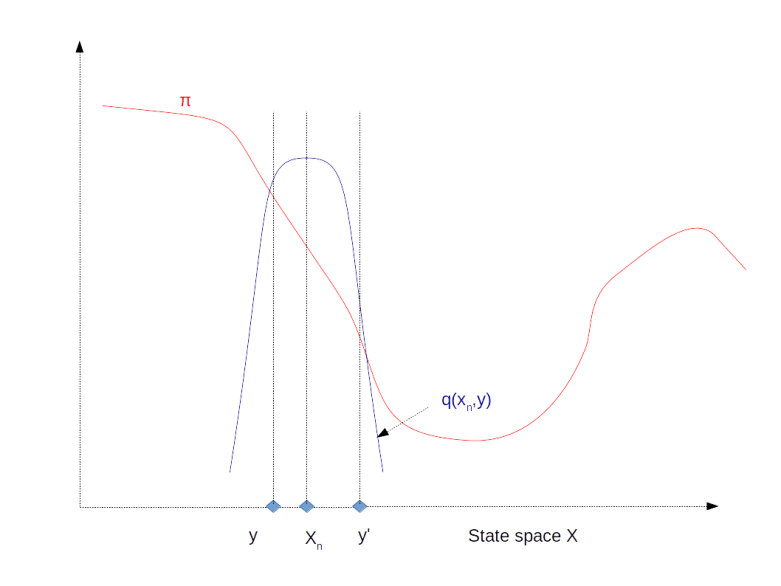
 and
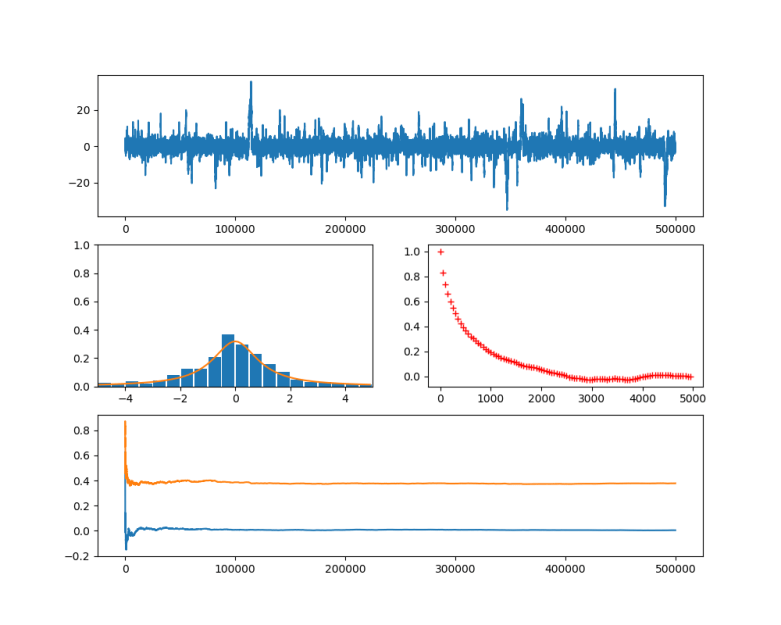
and  ) approximated using the partial sums develops over time. We see that even though we still have huge spikes, the integral remains comparatively stable and converges already after a few thousand iterations. Even if we run the simulation only for 1000 steps, we already get close to the actual values zero (for
) approximated using the partial sums develops over time. We see that even though we still have huge spikes, the integral remains comparatively stable and converges already after a few thousand iterations. Even if we run the simulation only for 1000 steps, we already get close to the actual values zero (for  (for
(for 
 and
and 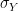 are the standard deviations of X and Y. In our case, given a lag, i.e. a number l less than the length of the chain, we can form two samples, one consisting of the points
are the standard deviations of X and Y. In our case, given a lag, i.e. a number l less than the length of the chain, we can form two samples, one consisting of the points  and the second one consisting of the points of the shifted series
and the second one consisting of the points of the shifted series  . The autocorrelation with lag l is then defined to be the correlation coefficient between these two series. In the diagram, we can see how the autocorrelation depends on the lag. We see that for a large lag, the autocorrelation becomes small, supporting our intuition that the series and the shifted series become independent. However, if we execute several simulation runs, we will also find that in some cases, the convergence of the autocorrelation is very slow, so care needs to be taken when trying to obtain a nearly independent sample from the chain.
. The autocorrelation with lag l is then defined to be the correlation coefficient between these two series. In the diagram, we can see how the autocorrelation depends on the lag. We see that for a large lag, the autocorrelation becomes small, supporting our intuition that the series and the shifted series become independent. However, if we execute several simulation runs, we will also find that in some cases, the convergence of the autocorrelation is very slow, so care needs to be taken when trying to obtain a nearly independent sample from the chain.  , we can use the conditional probability given either x1 or x2 as a proposal distribution. Thus, we first fix x2, and draw a new value for x1 from the conditional probability for x1 given the current value of x2. Then we move to this new coordinate, fix x1, draw from the conditional distribution of x2 given x1 and set the new value of x2 accordingly. It can be shown (see for example
, we can use the conditional probability given either x1 or x2 as a proposal distribution. Thus, we first fix x2, and draw a new value for x1 from the conditional probability for x1 given the current value of x2. Then we move to this new coordinate, fix x1, draw from the conditional distribution of x2 given x1 and set the new value of x2 accordingly. It can be shown (see for example