
In this post, I will discuss the general form of the EM algorithm to obtain a maximum likelihood estimator for a model with latent variables.
First, let us describe our model. We suppose that we are given some joint distribution of a random variable X (the observed variables) and and random variable Z (the latent variables) and are interested in maximizing the likelihood of an observed sample x of the visible variable X. We also assume that the joint distribution depends on a parameter 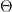

Even if the joint distribution belongs to some exponential family, the fact that we need to consider the logarithm of the sum and not the sum of the logarithms makes this expression and its gradient difficult to calculate. So let us look for a different approach.
To do this, let us assume that we are given a value 
![Q(\Theta'; \Theta) = E \left[ \ln P(x,z | \Theta') | x, \Theta \right]](https://s0.wp.com/latex.php?latex=Q%28%5CTheta%27%3B+%5CTheta%29+%3D+E+%5Cleft%5B++%5Cln+P%28x%2Cz+%7C+%5CTheta%27%29++%7C+x%2C+%5CTheta+%5Cright%5D++&bg=FFFFFF&fg=000&s=1&c=20201002)
That looks a bit complicated, so let me explain the notation a bit. We want to define a function Q that will be a function of the new parameter value
The right hand side is an expectation value. In fact, for each value of the visible variable x and the parameter 
![E \left[ \ln P(x,z | \Theta') | x, \Theta \right] = \sum_z \ln P(x,z | \Theta') P(z | x, \Theta)](https://s0.wp.com/latex.php?latex=E+%5Cleft%5B++%5Cln+P%28x%2Cz+%7C+%5CTheta%27%29++%7C+x%2C+%5CTheta+%5Cright%5D+%3D+%5Csum_z+%5Cln+P%28x%2Cz+%7C+%5CTheta%27%29+P%28z+%7C+x%2C+%5CTheta%29++&bg=FFFFFF&fg=000&s=1&c=20201002)
That is now again a sum of logarithms, not a logarithm of a sum, and we can hope to be able to deal with this much better.
This is nice, but so far we have only introduced a rather complicated additional object – what do we gain? It turns out that essentially, maxizing Q will effectively maximize the likelihood. Let us make this bold statement a bit more precise. Suppose we are able to iteratively maximize Q. Expressed formally, this would mean that we are able to find a sequence 


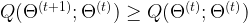
Then this very same sequence will be a sequence of parameters for which the log-likelihood is non-decreasing as well, i.e.

I will not include a proof for this in this post (the proof identifies the difference between any two subsequent steps as a Kullback-Leibler divergence and makes use of the fact that a Kullback-Leibler divergence is never negative, you can find a a proof in the references, in particular in [2], or in my more detailed notes on the EM algorithm and Gaussian mixture models, where I also briefly touch on convergence). Instead, let us try to understand how this can be used in practice.
Suppose that we have already constructed some parameter 
To see how this works in practice, let us now return to our original example – Gaussian mixtures. Here the parameter
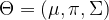
We consider a random variable X which has N components, each of which being a vector Xn in a d-dimensional space and corresponding to one sample vector (so in the language of machine learning, N will be our batch size). Similarly, Z consists of N components zn which again are subject to the restriction that only one of the znk be different from zero. We assume that the joint representation of our model is given by
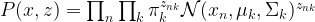
Now we need to compute Q. The calculation is a bit lengthy, and I will skip most of it here (you can find the details in the references or my notes for this post). To state the result, we have to introduce a quantity called responsibility which is defined as follows.

From this definition, is it clear that the responsibility is always between zero and one, and in fact is has an interpretation of a (conditional) probability that sample n belongs to cluster k. Note that the responsibility is a function of the model parameters 

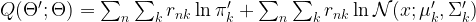
where the responsibilities are calculated using the old parameter set 


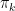

This starts to look familiar – this is the same expression that we did obtain for the cluster centers for the k-means algorithm! In fact, if we arrange the rnk as a matrix, the denominator is the sum across column k and the numerators is the weighted sum over all data points. However, there is one important difference – it is no longer true that given n, only one of the rnk will be different from one. Instead, the rnk are soft assignments that model the probability that the data point xn belongs to cluster k.
To write down the expression for the new value of the covariance matrix, we again need a notation first. Set
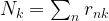
which can be interpreted as the number of soft assignments of points to cluster k. With that notation, the new value for the covariance matrix is

Finally, we can use the method of Lagrange multipliers to maximize with respect to the weights

Again, this is intuitively very appealing – the probability to be in cluster k is updated to be the number of points with a soft assignment to k divided by the total number of assignments
We now have all the ingredients in place to apply the algorithm in practice. Let us summarize how this will work. First, we start with some initial value for the parameters – the weights 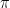


In the M-step, we then use these responsibilities and the formulas above to calculate the new values of the weights, the means and the covariance matrix. This involves a few matrix operations, which can be nicely expressed by the operations provide by the numpy library.

In the example above, we have created two sets of 500 sample points from different Gaussian mixture distributions and then applied the k-means algorithm and the EM algorithm. In the top row, we see the results of running the k-means algorithm. The color indicates the result of the algorithm, the shape of the marker indicates the original cluster to which the point belongs. The bottom row displays the results of the EM algorithm, using the same pattern.
We see that while the first sample (diagrams on the left) can be clustered equally well by both algorithms, the k-means algorithm is not able to properly cluster the second sample (diagrams on the right), while the EM algorithm is still able to assign most of the points to the correct cluster.
If you want to run this yourself, you can – as always – find the source code on GitHub. When playing with the code and the parameters, you will notice that the results can differ substantially between two consecutive runs, this is due to the random choice of the initial parameters that have a huge impact on convergence (and sometimes the code will even fail because the covariance matrix can become singular, I have not yet fixed this). Using the switch --data=Iris, you can also apply the EM algorithm to the Iris data set (you need to have a copy of the Iris data file in the current working directory) and find again that the results vary significantly with different starting points.
The EM algorithm has the advantage of being very general, and can therefore be applied to a wide range of problems and not just Gaussian mixture models. A nice example is the Baum Welch algorithm for training Hidden Markov models which is actually an instance of the EM algorithm. The EM algorithm can even be applied to classical multi-layer feed forward networks, treating the hidden units as latent variables, see [3] for an overview and some results. So clearly this algorithm should be part of every Data Scientists toolbox.
References
1. C.M. Bishop, Pattern recognition and machine learning, Springer, New York 2006
2. A.P. Dempster, N.M. Laird, D.B. Rubin, Maximum likelihood from incomplete data via the EM-algorithm, Journ. Royal Stat. Soc. Series B. Vol. 39 No. 1 (1977), pp. 1-38
3. Shu-Kay Ng, G.J. McLachlan, Using the EM Algorithm to Train Neural Networks: Misconceptions and a New Algorithm for Multiclass Classification, IEEE Transaction on Neural Networks, Vol. 15, No. 3, May 2004
