Very often, either the source or the target of a Kafka based message queue is a classical relational database. Consuming data and using it to update a database table sounds straightforward, but poses a few challenges around reliability and delivery semantics. In this post, we look into two options to realize such an architecture.
The challenge
To illustrate the problem we are aiming to solve, let us suppose that we want to build an application that maintains an account balance. There is a front-end which acts as a Kafka producer and which a customer can use to either deposit money in the account or withdraw money. These transactions are then written into a Kafka topic, and a consumer reads from this topic and updates the balance kept in a relational datastore.

Thus the messages stored in the Kafka topic contains transactions, i.e. changes in the account balance, while the database table we need to maintain contains the actual balance. This is an example of what is called stream / table duality in the world of streaming – the event stream is the source of truth and reflects changes, the database contains the resulting state of the world after all changes have been applied and can at any time be reconstructed from the stream.
When we want to implement his pattern, the crucial part of our design will be to make sure that every message in the queue leads to only one update of the balance, so that no transaction is missed and no transaction is processed twice.
Pattern 1: using a message ID and de-duplication
The first pattern we could use to make this work is to achieve de-duplication based on a unique message ID, which ideally is an integer that is increased with every message. The consumer could then store the sequence number of the last processed message in the database, and could thus detect duplicates.
In a bit more detail, this would work as follows. When the producer processes an action, it first retrieves a unique message ID. This message ID could be created using a database sequence, or – if the used database does not allow for this – it could read a sequence number from a table, increment it by one and update the table accordingly. It would then add this sequence number as a key to the Kafka message.
The consumer would store the latest processed sequence number in the database. When it reads a mesage from Kafka, it uses this number to check whether the message has already been processed before. If not, it updates balance and sequence number in one transaction and then commits the new offset to Kafka.

Let us see how duplicates are handled in this pattern. If, for some reason, the topic contains two messages with the same ID, the consumer will process the first message, increase the latest processed sequence number in the database and commit the new balance. It will then read the duplicate, compare its sequence number against the latest value, detect the duplicate and simply ignore it. Thus the consumer is able to do a de-duplication based on the sequence number.
Unfortunately, this simple pattern has one major disadvantage – it does not work. The problem is that the order of messages is not guaranteed across partitions. Suppose, for instance, that the producer creates the following messages:
- Message 1, partition 0
- Message 2, partition 1
- Message 3, partition 0
Now it might happen that the consumer processes the messages in the order 1,3,2. Thus the consumer would, after having processed message 3, set the highest consumed sequence number to “3” in the database. When now processing message two, our simple duplicate detection algorithm would then classify this message as a duplicate. Thus, to make this work, it is vital that we store the highest processed sequence number by partition and not across all partitions. We could even create the sequence number per partition, which would also remove a possible bottleneck as creating the sequence number would otherwise effectively serialize the producers.
Also note that, as we need to maintain a “last processed” sequence number per partition in a database, we also need to maintain this table if we add new partitions to our topic or remove partitions.
Alternatively, if there is a message ID which is not ordered and increasing with each message, the consumer could store all processed message IDs in a separate database table to keep track of the messages that have already been processed (which, depending on the throughput, might require some sort of periodic cleanup to avoid that the table grows too big).
If the consumer fails after committing the changed balance to the database, but before committing the offset to Kafka, the same mechanism will kick in, as long as we commit the new balance and the updated value of the last processed message in one database transaction. Thus, duplicates can be detected, and we can therefore rely on the standard mechanisms Kafka offers to manage the offset – we could even read entire batches from the topic and use auto-commit to let Kafka manage the offset.
Let us now try out this pattern with the code samples from my repository. To be able to run this, you will have to clone my GitHub repository and follow the instructions in my initial post in this series to bring up your local Kafka cluster. Then, make sure that your current working directory is the root directory of the repository and run the following commands which will install the Python package to access a MySQL database and bring up a Docker based installation of MySQL with a prepared database.
pip3 install mysql-connector-python ./db/createDB.sh
This script will start a Docker container kafka-mysql running MySQL, add a user kafka with a default password to it and create a database kafka for which this user has all privileges. Next, let us run a second script which will (re)-create a Kafka topic transactions with two partitions and initialize the database.
./db/reset.sh
Now we run three Python scripts. The first script is the producer that we have already described, which will simply create ten records, each of which describing a transaction. The second script is our consumer. It will
- subscribe to the transactions topic
- Read batches of records from the topic
- for each record, it will (in one transaction!) update the account balance and the last processed sequence number
- commit offsets in Kafka after processing a batch
- apply the duplicate detection mechanism outlined above while processing each record
Finally, the third script is a little helper that will (without committing any offsets, so that we can run it over and over again) scan the topic, calculate the expected account balances, retrieve actual account balances from the database and check whether they coincide.
python3 db/producer1.py python3 db/consumer1.py python3 db/dump1.py --check
Let us now try to understand how our scripts work if an error occurs. For that purpose, the consumer has a built-in mechanism to simulate random errors between committing to the database and committing offsets to Kafka which is activated using the parameter –error_probability. Let us repeat our test run, but this time we simulate an error with a probability of 20%.
./db/reset.sh && python3 db/producer1.py python3 db/consumer1.py --error_probability=0.2 --verbose python3 db/dump1.py --check
You should now see that the consumer processes a couple of messages before our simulated error kicks in, which will make the consumer stop. The check script should detect the difference resulting from the fact that not all messages have been processed. However, when we now restart the script without simulating any errors, we should see that even though there are duplicate records, these records are properly detected and eventually, all records will be processed and the balances will again be correct.
python3 db/consumer1.py --verbose python3 db/dump1.py --check
Pattern 2: store the consumer offset in the target database
Let us now take a look at an alternative implementation (which is in fact the pattern which you will hit upon first when consulting the Kafka documentation or other sources) – maintaining the offsets in the database altogether. This implementation does not require a sequence number generated by the producer, but is therefore also not able to detect any duplicate messages in case the duplicates originate already in the producer.
The idea behind this pattern is simple. Instead of asking Kafka to maintain offsets for us, the consumer application handles offsets independently and maintains a database table containing offsets and partitions. When a record is processed, the consumer opens a database transaction, updates the account balance and updates the offset in the same transaction. This guarantees that offsets and balances are always in sync.
This sound simple enough, but there are a few subtleties that need to be kept in mind when this is combined with consumer groups, i.e. if Kafka handles partition assignments dynamically. Whenever a partition is assigned to our consumer, we need to make sure that we position the consumer at the latest committed offset before processing any records. Conversely, when an assignment is revoked, we need to commit the current offsets to make sure that they are not lost. This can be implemented using a rebalance listener which is registered when we subscribe to the topic.
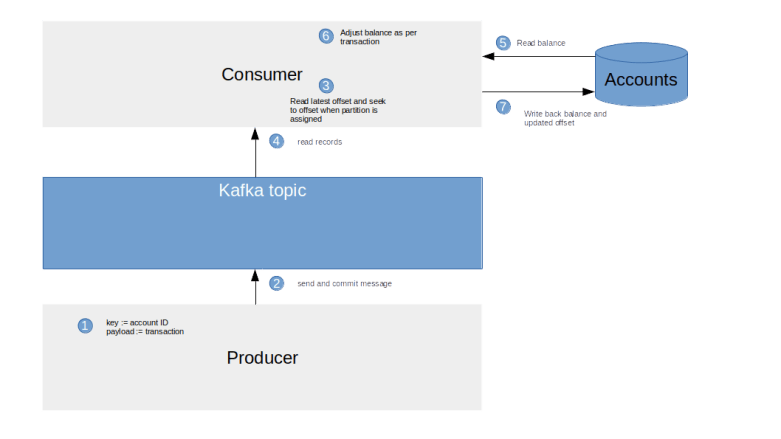
To try this out, run the following commands which will first reset the database and the involved topic, run the producer to create a few messages (this time without the additional sequence number) and then run our new consumer to read the messages and update the database.
./db/reset.sh && python3 db/producer2.py python3 db/consumer2.py python3 db/dump2.py --check
The last command, which again checks the updated database table against the expected values, should again show you that expected and actual values in the database match.
It is instructive to try a few more advanced scenarios. You could, for instance, run the producer and then start a consumer which reads the first set of messages produced by the consumer (use the switch –runtime=3600 to make this consumer run for one hour). Then, start a second consumer in a separate terminal window and observe the rebalancing that occurs. Finally, run the producer again and verify that the partition assignment worked and both consumers are processing the messages in their respective partition. And again, you can simulate errors along the way and see how the consumer behaves.
