
In the previous post, we have installed Cinder and described its high level architecture. Today, we will look at a few uses cases (creating and attaching volumes) in detail, go through the code and see how Cinder interacts with external technologies like iSCSI and LVM.
Creating a volume
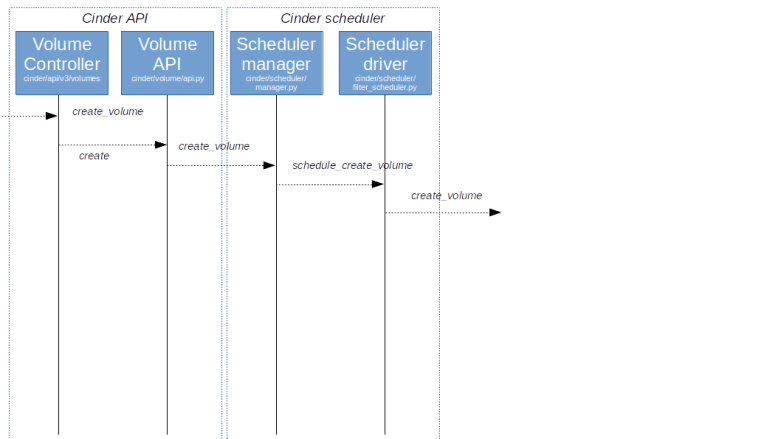
Let us first try to understand what happens when a volume is created, for instance because a user submit the corresponding API request via the OpenStack CLI, using v3 of the API.
In the architecture overview, we have mentioned that the Cinder API server is run by Apache. To understand how this request is processed, it therefore makes sense to start at the Apache2 configuration in /etc/apache2/conf-available/cinder-wsgi.conf. Here, we find a reference to the script cinder-wsgi which in turn shows up in the setup.cfg file distributed with Cinder. Following the link in this file, we find that the WSGI server is initialized by initialize_application which in turn uses the Oslo service library to create an application from a PasteDeploy configuration.
Browsing the PasteDeploy config that is distributed with Cinder, we find that, as we have seen it before, it defines several authorization strategies. We use the Keystone strategy, and in this pipeline, the last element points to the factory method cinder.api.v3.router.APIRouter.factory, implemented here. This class implements a routing mechanism, which translates our PUT request into a call to VolumeController.create.
So far, this flow looks familiar and we have seen this before – there is a WSGI application acting as an API endpoint, which routes requests to various controller. Now the Cinder specific processing starts, and the Controller, after performing some transformations and validations, invokes cinder.volumes.API().create()
This method now uses a device which we can find at several points in OpenStack when it comes to managing processes consisting of several steps – the OpenStack Taskflow library. This library provides flows that can be built from tasks, can be run using a flow engine and can be stopped and reverted in a controlled manner. In Cinder, various processes are modeled as flows. In our case, the flow is built by this method and consists of several tasks, which will deduct the volume size from the quota, create a database object for the volume and commit the changed quota. If everything succeeds, we now delegate to the scheduler for further processing by triggering a RPC call via RabbitMQ.

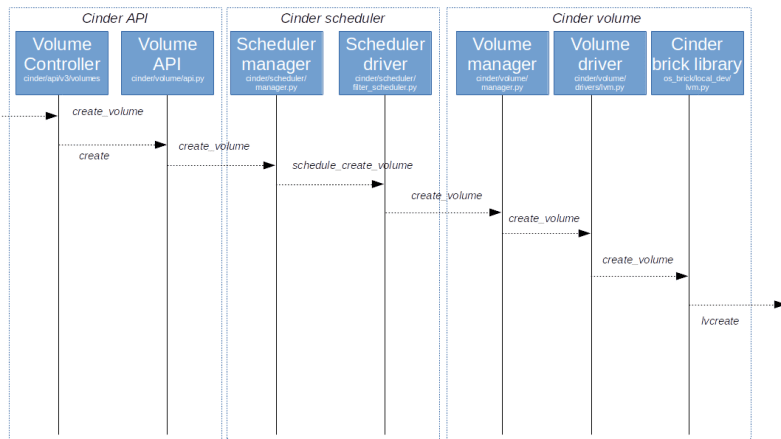
The entry point into the scheduler, which is running as an independent process, is the method create_volume of the corresponding manager object cinder.scheduler.SchedulerManager. Here, we create another flow and run it. This flow does again do some validation and then calls a scheduler driver, which, as so often in OpenStack, is a pluggable module that carries out the actual scheduling. In our case, this is the filter scheduler. After the actual scheduling is complete, the driver now sends an RPC call to the selected node which is received by the volume manager, more precisely by its method create_volume.
This again creates a flow, which will include a task that does the actual volume creation (CreateVolumeFromSpecTask). Here, the actual work is delegated to a volume driver. In our setup, our driver is the LVM driver (cinder.volume.drivers.LVMVolumeDriver). We first look at its _init_ method. Here we determine the target_helper from the configuration and create the corresponding target driver. During initialization, the manager will also call the method check_for_setup_error which, among other things, creates an object which represents the volume group that Cinder manages and which is an instance of cinder.brick.local_dev.LVM. When the method create_volume of the volume driver is called, it will essentially delegate the call to this class. In its create_volume method, we now finally see that the LVM command lvcreate is called which creates the actual logical volume.
Let us try to find the traces of all this in our setup. For that purpose, re-start the setup from the previous setup, and, if you have not yet done so, create a volume of size 1 (GB).
git clone https://github.com/christianb93/openstack-labs cd openstack-labs/Lab13 vagrant up ansible-playbook -i hosts.ini site.yaml ansible-playbook -i hosts.ini demo.yaml vagrant ssh network source demo-openrc openstack volume create \ --size 1 \ demo-volume
Now log out of the network node, log into the storage node and run sudo lvs. You should see two volumes, both on top of the volume group cinder-volumes, as in the sample output below.
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert cinder-volumes-pool cinder-volumes twi-aotz-- 4.75g 0.00 10.64 volume-5eae9e4b-6a28-41a2-a983-e435ec23ce46 cinder-volumes Vwi-a-tz-- 1.00g cinder-volumes-pool 0.00
We see that there is a new logical volume, whose name is the prefix volume-, followed by the UUID of the volume that we have just created. This is a so-called thin volume, meaning that LVM does not allocate extends when the logical volume is created, but maintains a pool of available extends and allocates extends from this pool only when data is actually written. This is a sort of over-commitment of storage, as it allows us to create volumes which have a size much larger than the actually physically available size.
Attaching a volume
At this point, we have created a virtual storage volume which is living on the storage node. In order to be usable for an instance, we now have to attach the volume to an instance. Before trying this out, let us again see how this request will flow through the source code.
Typically, attaching a volume is done by a call to the Nova API. Nova will then in turn call the Cinder API where the calls will be processed by the Cinder attachment controller. Actually, during the process of attaching a volume to an instance, Nova will invoke the Cinder API three times (not counting read-only requests). First, it will use a POST request to ask the controller to create the attachment, then it will use a PUT request to update the attachment by providing so-called connector information and finally, it will use another POST request to call the complete method to signal that the process of attaching the volume is complete.
Let us start to understand the first request. Here, Nova only provides the UUID of the volume and the UUID of the instance to be connected. This request will be served by the create method of the attachment controller. After some preparations, the controller will then invoke the method attachment_create of the volume manager API. At this point, no connector information is available yet, so all this method does is to create a reservation by storing the attachment in the database.

Now the second call from Nova comes in. At this point, Nova will have collected the connector information, which is the IP address of the compute node, the iSCSI initiator name, the mount point and some additional information. Just in case you want to link this back into the Nova code: the connector data is assembled here (where we can also see that the IP address used is taken from the configuration item my_block_storage_ip in the Nova configuration), and the update call to the Cinder API which we are currently discussing is made here.
A typical connector information could look as follows.
{'connector':
{'platform': 'x86_64',
'os_type': 'linux',
'ip': '192.168.1.21',
'host': 'compute1',
'multipath': False,
'initiator': 'iqn.1993-08.org.debian:01:a41db8382266',
'do_local_attach': False,
'system uuid': '54F9944F-66C9-411E-9989-84AB5CEE6B18',
'mountpoint': '/dev/vdc'}
}
The update call will again reach the volume manager API which will look up the volume and forward the request via RPC to the volume manager on the storage node where the storage is located. The result – the connection information – is then returned to the callee, i.e. in our case the Nova driver, which then connects to the device using a volume driver and eventually submits the third call to Cinder to signal completion.
But let us continue to investigate the call chain for the update call first. The volume manager on the storage node now performs several steps. First, it calls the responsible Cinder volume driver (which, in our case, is the LVM driver) to create the export, i.e. to activate the logical volume and to use a target driver to initiate the actual export. In our case, the target driver is the iSCSI driver, and export here simply means that an iSCSI target is created on the storage driver (and a CHAP secret is returned).
Back in the volume manager, the manager next calls the method initialize_connection of the driver which is simply passed through to the target driver and assembles the connection information, i.e. the target and portal information. Finally, the manager makes a call to the method attach_volume of the volume driver, but this method is empty for the LVM driver. At this point, the database record is updated and the connection info is returned.
Nova is now able to finalize the attachment by using the Open-iSCSI helper to establish the connection to the target using iscsiadmin from the Open-iSCSI package. When all this succeeds, Nova will eventually call Cinder a third time, this time invoking the complete method of the attachment controller. This method will update the attachment and the volume in the database, and the entire process is complete.

Let us now try to identify some of the objects created during this process in our lab setup. For that purpose, first log into the networking node and attach the volume that we have just created to our instance.
source demo-openrc openstack server \ add volume \ demo-instance-3 \ demo-volume
Now log out off the network node and log into the compute node. Here, we first use iscsiadm to display all open iSCSI sessions.
sudo iscsiadm -m session -P 3
Here you can see that we have an open session connected to the iSCSI target that Cinder has created for this volume, and you can see that this volume is mapped to a block device like /dev/sdc on the compute node. Note that there is actually one target for each volume, so that a dedicated CHAP secret can be used for every logical volume.
Now let us try to locate this block device in the configuration of our KVM/QEMU guest. For this purpose, we first use the OpenStack API to determine the UUID of the instance and then the virsh manager to display this instance.
source demo-openrc uuid=$(openstack server show \ demo-instance-3 \ -c id -f value) sudo virsh domblklist $uuid
We now see that the instance has two devices attached to it. The first device is mapped to /dev/vda inside the instance and is the root device. This device is a flat file that Nova has created and placed on the compute host, i.e. it is an ephemeral device which gets lost if the instance is destroyed, the host goes down or the instance is migrated to a different machine. The second device is our device /dev/sdc which is pointing via iSCSI to the virtual device on the storage node.
There are many other functions of Cinder that we have not yet touched upon. You can, for instance, create volumes from existing images, in which case Glance comes into play, or Cinder can use the snapshot functionality of LVM to create and manage snapshots. It is also possible to configure Cinder such that is uses mirrored LVM devices (with a local mirror, though), and of course there are many other volume drivers apart from LVM. Going through all this would be a separate series, but I hope that I could at least provide some entry points into code and documentation so that you can explore all this if you want.
