
In one of my previous posts, we have looked at deployment controllers which make sure that a certain number of instances of a given pod is running at all times. Failures of pods and nodes are automatically detected and the pod is restarted. This mechanism, however, only works well if the pods are actually interchangeable and stateless. For stateful pods, additional mechanisms are needed which we discuss in this post.
Simple stateful sets
As a reminder, let us first recall some properties of deployments aka stateless sets in Kubernetes. For that purpose, let us create a deployment that brings up three instances of the Apache httpd.
$ kubectl apply -f - << EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: httpd
spec:
selector:
matchLabels:
app: httpd
replicas: 3
template:
metadata:
labels:
app: httpd
spec:
containers:
- name: httpd-ctr
image: httpd:alpine
EOF
deployment.apps/httpd created
$ $ kubectl get pods
NAME READY STATUS RESTARTS AGE
httpd-76ff88c864-nrs8q 1/1 Running 0 12s
httpd-76ff88c864-rrxw8 1/1 Running 0 12s
httpd-76ff88c864-z9fjq 1/1 Running 0 12s
We see that – as expected – Kubernetes has created three pods and assigned random names to them, composed of the name of the deployment and a random string. We can run hostname inside one of the containers to verify that these are also the hostnames of the pods. Let us pick the first pod.
$ kubectl exec -it httpd-76ff88c864-nrs8q hostname httpd-76ff88c864-nrs8q
Let us now kill the first pod.
$ kubectl delete pod httpd-76ff88c864-nrs8q
After a few seconds, a new pod is created. Note, however, that this pod receives a new pod name and also a new host name. And, of course, the new pod will receive a new IP address. So its entire identity – hostname, IP address etc. – has changed. Kubernetes did not actually magically revive the pod, but it realized that one pod was missing in the set and simply created a new pod according to the same pod specification template.
This behavior allows us to recover from a simple pod failure very quickly. It does, however, pose a problem if you want to deploy a set of pods that each take a certain role and rely on stable identities. Suppose, for instance, that you have an application that comes in pairs. Each instance needs to connect to a second instance, and to do this, it needs to know the name of that instance name and needs to rely on the stability of that name. How would you handle this with Kubernetes?
Of course, we could simply define two pods (not deployments) and use different names for both deployments. In addition, we could set up a service for each pod, which will create DNS entries in the Kubernetes internal DNS network. This would allow each pod to locate the second pod in the pair. But of course this is cumbersome and requires some additional monitoring to detect failures and restart pods. Fortunately, Kubernetes did introduce an alternative known as Stateful sets.
In some sense, a stateful set is similar to a deployment. You define a pod template and a desired number of replicas. A controller will then bring up these replicas, monitor them and replace them in case of a failure. The difference between a stateful set and a deployment is that each instance in a stateful set receives a unique identity which is stable across restarts. In addition, the instances of a stateful set are brought up and terminated in a defined order.
This is best explained using an example. So let us define a stateful set that contains three instances of a HTTPD (which, of course, is a toy example and not a typical application for which you would use stateful sets).
$ kubectl apply -f - << EOF
apiVersion: v1
kind: Service
metadata:
name: httpd-svc
spec:
clusterIP: None
selector:
app: httpd
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: stateful-test
spec:
selector:
matchLabels:
app: httpd
replicas: 3
serviceName: httpd-svc
template:
metadata:
labels:
app: httpd
spec:
containers:
- name: httpd-ctr
image: httpd:alpine
EOF
service/httpd-svc created
statefulset.apps/stateful-test created
That is a long manifest file, so let us go through it one by one. The first part of the file is simply a service called httpd-svc. The only thing that might seem strange is that this service has no cluster IP. This type of service is called a headless service. Its primary purpose is not to serve as a load balancer for pods (which would not make sense anyway in a typical stateful scenario, as the pods are not interchangeable), but to provide a domain in the cluster internal DNS system. We will get back to this point in a few seconds.
The second part of the manifest file is the specification of the actual stateful set. The overall structure is very similar to a deployment – there is the usual metadata section, a selector that selects the pods belonging to the set, a replica count and a pod template. However, there is also a reference serviceName to the headless service that we have just created.
Let us now inspect our cluster to see that this manifest file has created. First, of course, there is the service that the first part of our manifest file describes.
$ kubectl get svc httpd-svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE httpd-svc ClusterIP None 13s
As expected, there is no cluster IP address for this service and no port. In addition, we have created a stateful set that we can inspect using kubectl.
$ $ kubectl get statefulset stateful-test NAME READY AGE stateful-test 3/3 88s
The output looks similar to a deployment – we see that our stateful set has three replicas out of three in total in status READY. Let us inspect those pods. We know that, by definition, our stateful set consists of all pods that have an app label with value equal to httpd, so we can use a label selector to list all these pods.
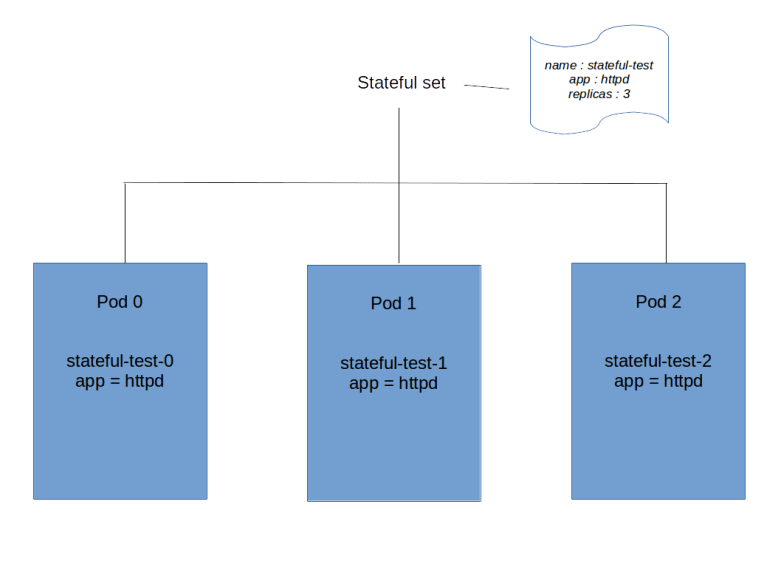
$ kubectl get pods -l app=httpd NAME READY STATUS RESTARTS AGE stateful-test-0 1/1 Running 0 4m28s stateful-test-1 1/1 Running 0 4m13s stateful-test-2 1/1 Running 0 4m11s
So there are three pods that belong to our set, all in status running. However, note that the names of the pods follow a different pattern than for a deployment. The name is composed of the name of the stateful set plus an ordinal, starting at zero. Thus the names are predictable. In addition, the AGE field tells you that Kubernetes will also bring up the pods in this order, i.e. it will start pod stateful-test-0, wait until this pod is ready, then bring up the second pod and so on. If you delete the set again, it will bring them down in the reverse order.
Let us check whether the pod names are not only predictable, but also stable. To do this, let us bring down one pod.
$ kubectl delete pod stateful-test-1 pod "stateful-test-1" deleted $ kubectl get pods -l app=httpd NAME READY STATUS RESTARTS AGE stateful-test-0 1/1 Running 0 8m41s stateful-test-1 0/1 ContainerCreating 0 2s stateful-test-2 1/1 Running 0 8m24s
So Kubernetes will bring up a new pod with the same name again – our names are stable. The IP addresses, however, are not guaranteed to remain stable and typically change if a pod dies and a substitute is created. So how would the pods in the set communicate with each other, and how would another pod communicate with one of them?
To solve this, Kubernetes will add DNS records for each pod. Recall that as part of a Kubernetes cluster, a DNS server is running (with recent versions of Kubernetes, this is typically CoreDNS). Kubernetes will mount the DNS configuration file /etc/resolv.conf into each of the pods so that the pods use this DNS server. For each pod in a stateful set, Kubernetes will add a DNS record. Let us use the busybox image to show this record.
$ kubectl run -i --tty --image busybox:1.28 busybox --restart=Never --rm If you don't see a command prompt, try pressing enter. / # cat /etc/resolv.conf nameserver 10.245.0.10 search default.svc.cluster.local svc.cluster.local cluster.local options ndots:5 / # nslookup stateful-test-0.httpd-svc Server: 10.245.0.10 Address 1: 10.245.0.10 kube-dns.kube-system.svc.cluster.local Name: stateful-test-0.httpd-svc Address 1: 10.244.0.108 stateful-test-0.httpd-svc.default.svc.cluster.local
What happens? Apparently Kubernetes creates one DNS record for each pod in the stateful set. The name of that record is composed of the pod name, the service name, the namespace in which the service is defined (the default namespace in our case), the subdomain svc in which all entries for services are stored and the cluster domain. Kubernetes will also add a record for the service itself.
/ # nslookup httpd-svc Server: 10.245.0.10 Address 1: 10.245.0.10 kube-dns.kube-system.svc.cluster.local Name: httpd-svc Address 1: 10.244.0.108 stateful-test-0.httpd-svc.default.svc.cluster.local Address 2: 10.244.0.17 stateful-test-1.httpd-svc.default.svc.cluster.local Address 3: 10.244.1.49 stateful-test-2.httpd-svc.default.svc.cluster.local
So we find that Kubernetes has added additional A records for the service, corresponding to the three pods that are part of the stateful set. Thus an application could either look up one of the services directly, or use round-robin and a lookup of the service name to talk to the pods.
As a sidenote, you have really have to use version 1.28 of the busybox image to make this work – later versions seem to have a broken nslookup implementation, see this issue for details.
Stateful sets and storage
Stateful sets are meant to be used for applications that store a state, and of course they typically do this using persistent storage. When you create a stateful set with three replicas, you would of course want to attach storage to each of them, but of course you want to use different volumes. In case a pod is lost and restarted, you would also want to automatically attach the pod to the same volume to which the pod it replaces was attached. All this is done using PVC templates.
Essentially, a PVC template has the same role for storage that a pod specification template has for pods. When Kubernetes creates a stateful set, it will use this template to create a set of persistent volume claims, one for each member of the set. These persistent volume claims are then bound to volumes, either manually created volumes or dynamically provisioned volumes. Here is an extension of our previously used example that includes PVC templates.
apiVersion: v1
kind: Service
metadata:
name: httpd-svc
spec:
clusterIP: None
selector:
app: httpd
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: stateful-test
spec:
selector:
matchLabels:
app: httpd
replicas: 3
serviceName: httpd-svc
template:
metadata:
labels:
app: httpd
spec:
containers:
- name: httpd-ctr
image: httpd:alpine
volumeMounts:
- name: my-pvc
mountPath: /test
volumeClaimTemplates:
- metadata:
name: my-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
The code is the same as above, with two differences. First, we have an additional array called volumeClaimTemplates. If you consult the API reference, you will find that the elements of this array are of type PersistentVolumeClaim and therefore follow the same syntax rules as the PVCs discussed in my previous posts.
The second change is that in the container specification, there is a mount point. This mount point refers directly to the PVC name, not using a volume on Pod level as a level of indirection as for ordinary deployments.
When we apply this manifest file and display the existing PVCs, we will find that for each instance of the stateful set, Kubernetes has created a PVC.
$ kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE my-pvc-stateful-test-0 Bound pvc-78bde820-53e0-11e9-b859-0afa21a383ce 1Gi RWO gp2 1m my-pvc-stateful-test-1 Bound pvc-8790edc9-53e0-11e9-b859-0afa21a383ce 1Gi RWO gp2 38s my-pvc-stateful-test-2 Bound pvc-974cc9fa-53e0-11e9-b859-0afa21a383ce 1Gi RWO gp2 12s
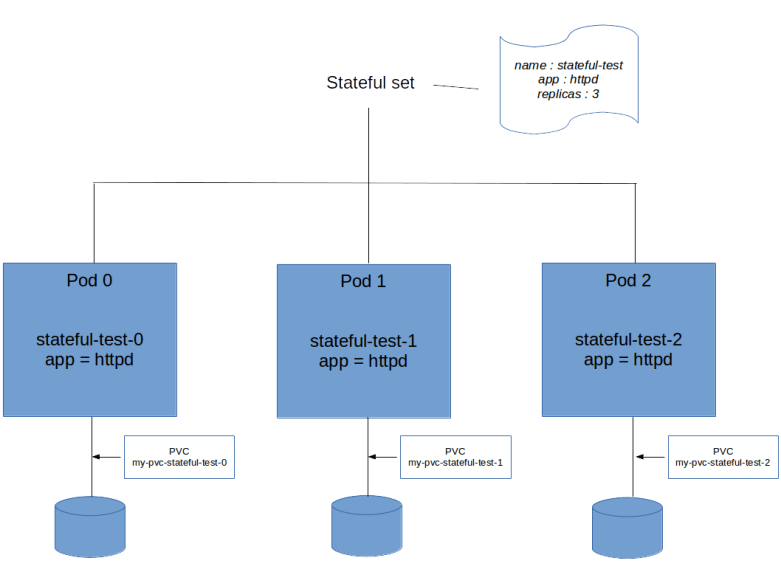
We see that again, the naming of the PVCs follows a predictable patterns and is composed of the PVC template name and the name of the corresponding pod in the stateful set. Let us now look at one of the pods in greater detail.
$ kubectl describe pod stateful-test-0
Name: stateful-test-0
Namespace: default
Priority: 0
[ --- SOME LINES REMOVED --- ]
Containers:
httpd-ctr:
[ --- SOME LINES REMOVED --- ]
Mounts:
/test from my-pvc (rw)
/var/run/secrets/kubernetes.io/serviceaccount from default-token-kfwxf (ro)
[ --- SOME LINES REMOVED --- ]
Volumes:
my-pvc:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: my-pvc-stateful-test-0
ReadOnly: false
default-token-kfwxf:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-kfwxf
Optional: false
[ --- SOME LINES REMOVED --- ]
Thus we find that Kubernetes has automatically created a volume called my-pvc (the name of the PVC template) in each pod. This pod volume then refers to the instance-specific PVC which again refers to the volume, and this pod volume is in turn referenced by the Docker mount point.
What happens if a pod goes down and is recreated? Let us test this by writing an instance specific file onto the volume mounted by pod #0, deleting the pod, waiting for a few seconds to give Kubernetes enough time to recreate the pod and checking the content of the volume.
$ kubectl exec -it stateful-test-0 touch /test/I_am_number_0 $ kubectl exec -it stateful-test-0 ls /test I_am_number_0 lost+found $ kubectl delete pod stateful-test-0 && sleep 30 pod "stateful-test-0" deleted $ kubectl exec -it stateful-test-0 ls /test I_am_number_0 lost+found
So we see that in fact, Kubernetes has bound the same volume to the replacement for pod #0 so that the application can access the same data again. The same happens if we forcefully remove the node – the volume is then automatically attached to the node on which the replacement pod will be scheduled. Note, however, that this only works if the new node is in the same availability zone as the previous node as on most cloud platforms, cross-AZ attachment of volumes to nodes is not possible, in this case, the scheduler will have to wait until a new node in that zone has been brought up (see e.g. this link for more information on running Kubernetes in multiple zones).
Let us continue to investigate the life cycle of our volumes. We have seen that the volumes have been created automatically when the stateful set was created. The converse, however, is not true.
$ kubectl delete statefulset stateful-test statefulset.apps "stateful-test" deleted $ kubectl delete svc httpd-svc service "httpd-svc" deleted $ kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE my-pvc-stateful-test-0 Bound pvc-78bde820-53e0-11e9-b859-0afa21a383ce 1Gi RWO gp2 14m my-pvc-stateful-test-1 Bound pvc-8790edc9-53e0-11e9-b859-0afa21a383ce 1Gi RWO gp2 13m my-pvc-stateful-test-2 Bound pvc-974cc9fa-53e0-11e9-b859-0afa21a383ce 1Gi RWO gp2 13m
So the persistent volume claims (and the volumes) remain existent if the delete the stateful set. This seems to be a deliberate design decision to give the administrator a chance to copy or backup the data on the volumes even after the set has been deleted. To fully clean up the volumes, we therefore need to delete the PVCs manually. Fortunately, this can again be done using a label selector, in our case
kubectl delete pvc -l app=httpd
will do the trick. Note that it is even possible to reuse the PVCs – in fact, if you recreate the stateful set and the PVCs still exists, they will be reused and attached to the new pods.
This completes our overview of stateful sets in Kubernetes. Running stateful applications in a distributed cloud environment is tricky, and there is much more that needs to be considered. To see a few examples, you might want to look at some of the examples which are part of the Kubernetes documentation, for instance the setup of a distributed key-value store like ZooKeeper. You might also want to learn about operators that provide application specific controller logic, for instance promoting a database replica to a master if the current master node goes down. For some additional considerations on running stateful applications on Kubernetes you might want to read this nice post that explains additional mechanisms like leader elections that are common ingredients for a stateful distributed application.
