
Today, we will look in more detail into convergence of Markov chains – what does it actually mean and how can we tell, given the transition matrix of a Markov chain on a finite state space, whether it actually converges.
So suppose that we are given a Markov chain on a finite state space, with transition probabilities described by a matrix K as in the previous post on this topic.
We have seen that the distribution of Xn is given by 
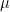
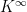

then of course
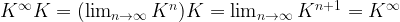
In other words, each row 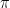
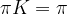

So convergence implies the existence of an invariant distribution. Let us next try to understand whether this invariant distribution is unique. There are obvious examples where this is not the case, the most trivial one being the unit matrix

Obviously 
Intuitively, we say that a Markov chain is irreducible if any state can be reached from any other state in finitely many steps. For a finite state space, this is rather easy to formalize. A finite Markov chain is called irreducible if, given two states i and j, we can find some power n such that 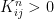
Now let us assume that our chain is in fact irreducible. What else do we have to ask for to make sure that it converges? Again, let us as look at an obvious example.

All even powers of this matrix are the unit matrix and all odd powers are K itself, so the Markov chain described by this transition matrix is clearly irreducible. However, there is still something wrong. If, for instance, we are in state 1 at the time t, then the probability to still be in state 1 at time t+1 is zero. Thus we are actually forced to move to state 2. In a certain sense, there is still an additional constraint on the the behaviour of the chain – the state space can be split in two pieces and we cycle through these pieces with every step. Such a chain is called periodic. If a chain is periodic, it is again obvious that we can think of it as two different chains, one chain given by the random variables X0, X2,… at even times and the other chain given by the random variables X1, X3, … at odd times. Thus again, there is a way to split the chain into parts.
So let us now focus on chains that are irreducible and aperiodic. Can we tell whether the chain converges? The answer is surprisingly simple and one of the most powerful results in the theory or Markov chains: every finite Markov chain which is irreducible and aperiodic converges. Thus once we have verified aperiodicity and irreducibility, we can be sure that the limit
This gives us two different approaches to calculating the invariant distribution and the limit
Let us do this for the example of the random walk on a circle that we have studied earlier. For simplicity, we will use N = 4 this time. The transition matrix with p = 0.8 is

We can then easily implement both approaches in Python using the numpy library.
So we see that the approach to take the eigenvalues and eigenvectors gives us – in this case – the exact result (and a direct computation confirms that this is really an eigenvector), whereas the matrix power with n=20 gives a decent approximation. Both results confirm what we have observed visually in the last post – the distribution converges, and it does in fact converge to the uniform distribution. So roughly speaking, after sufficiently many steps, we end up everyhwere in the state space with equal probability.
So far, we have only discussed the case of a finite state space. In the general case, the situation is more complicated. First, we need a better definition of irreducibility, as on a general state space, the probability measure of a single point tends to be zero. It turns out that the solution is to define irreducibility with respect to a measure on the state space, which is called 
First, it might happen that even though the chain is irreducible, it does not properly cycle through the state space and revisits every point with finite probability, but – intuitively speaking – heads off to infinity. Such a chain is called transient and does not converge.
Second, even if the chain is not transient, we might be able to find an invariant distribution (a measure in this case), but this measure might not be a probability distribution as it is not finite. Chains with this property are called null recurrent.
And finally, the concept of converge needs to be made more precise, and it turns out to have a subtle dependency on the starting point which can be fixed by assuming so called Harris recurrence. But all this can be done and delivers a very similar result – a convergence theorem for a large class of chains (in this case aperiodic Harris recurrent Markov chains). If you would like to get deeper into this and also see proofs for the claims made in this post and references, I invite you to take a look at my short introduction to Markov chains.
We close this post with one remark which, however, is of crucial importance for applications. Suppose we have a convergent Markov chain Xt, and a function f on the state space. If the Xt were independent and identically distributed, we could approximate the expectation value of f as
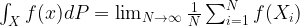
where dP is the (common) distribution of the Xt. For Markov chains, however, we know that the Xt are not independent – the whole point of having a Markov chain is that Xt+1 does actually depend on Xt. However, in our example above, we have seen that the dependency gets trivial for large t as in this example, all entries in the transition matrix become equal in the limit.
Of course this is a special case, but it turns out that even in general, the approximation of the expectation value by averages across the sample is still possible. Intuitively, this is not so surprising at all. If the distributions 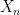

On the other hand, this product is again approximately the product

Thus, intuitively, Xn and Xm are almost independent if n and m are large, which makes us optimistic that the law of large numbers could actually hold.
In fact, if Xt converges (again I refer to my notes for a more precise definition of convergence in this case), it turns out that the law of large numbers remains valid if we integrate f with respect to the invariant distribution
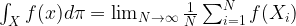
This is extremely useful in applications, where often the primary purpose is not so much to obtain a sample, but to approximate otherwise intractable integrals! Once we have found a Markov chain that converges to the invariant distribution
So given a distribution

1 Comment