In this post, we will look in more detail into an important class of Markov chains – Markov chains on finite state spaces. Many of the subtleties that are present when studying Markov chains in general state spaces do not appear in the finite case, while most of the key ideas and features of Markov chains are still visible, so this is a good starting point if you want to grasp the key points.
So let us assume that our state space X is finite. For simplicity, we label our states as 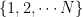
Now consider a sequence of random variables X0, X1, …. How can we formalize the idea that Xt+1 depends on Xt in a randomized way?
As so often in probability theory, let us model the dependency as a conditional probability. The conditional probability for Xt+1 to take on a value i given Xt
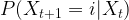
considered as a function of Xt will assign a conditional probability to each of the states i and for each value of Xt. Therefore we can write this as a matrix
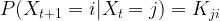
To obtain a time homogeneous Markov chain, we also assume that the matrix K does not depend on the time t. Therefore we define a Markov chain on X to be a sequence 
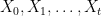

We also require that this conditional probability is independent of t and is therefore given by a matrix K as in the formula above.
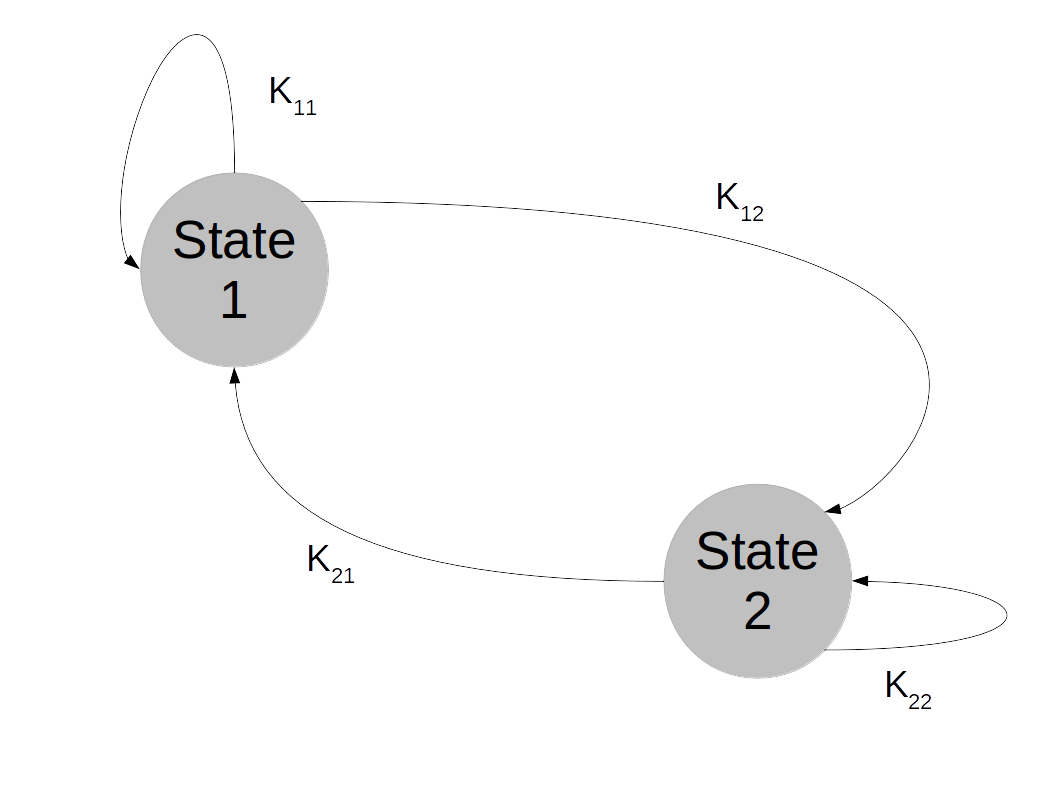
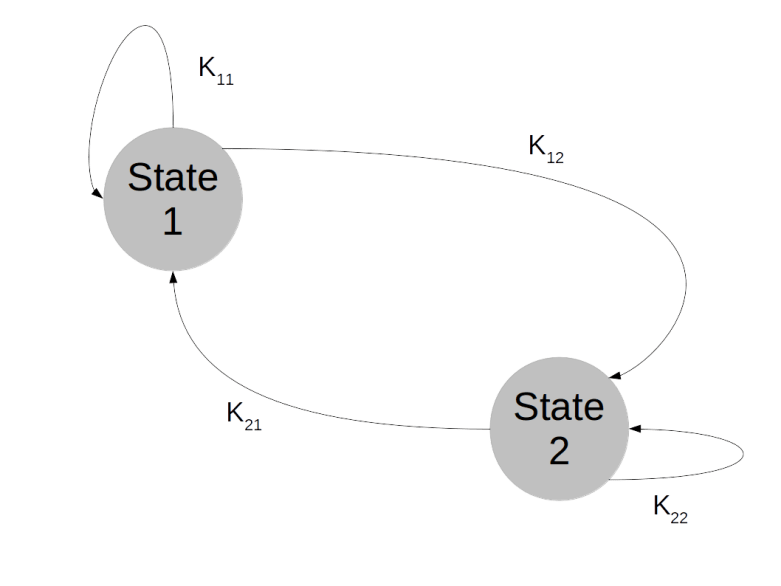
Markov chains on finite state spaces are often visualized as a graph. Suppose, for instance, that our state space contains only two elements: 

In our state space with two elements only, the Markov chain is then described by four transition probabilities: the probability to stay in state 1 when the chain is in state 1, the probability to move to state 2 when being in state 1, the probability to stay in state 2 and the probability to move to state 1 after being in state 2. This can be visualized as follows.
Let us now calculate a few probabilities to get an idea for the relevant quantities in such a model. First, suppose that at time 0, the model is in state j with probability 

Now, according to the rules of conditional probabilities, we can express the joint probability as follows.

Plugging this into our previous expression and using the definitions of K and 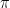

Thus if we think of 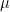
Now let us calculate a slightly different quantity. Assume that we know that a chain starts at j. What is the probability to be at i after two steps? Using once more the rules of conditional probability and the Markov property, we can write

Intuitively, this is very appealing. To get from j to i in two steps, we can take the way via any intermediate state k. To get the total probability, we simply sum up all these different probabilities! If you have ever seen path integrals in quantum mechanics, this idea will look familiar.
Again, we can write this in matrix notation. Each of the conditional probabilities on the right hand side of the expression above is a matrix element, and we find that

so that the probability to get in two steps from j to i is simply given by the elements of the matrix K2. Similarly, the n-step transition probabilities are the entries of the matrix Kn.
Let us look at an example to understand what is going on here, which is known as a finite random walk on a circle. Our state space consists of N distinct points which we place arbitrarily on a circle. We then define a Markov chain as follows. We start at some arbitrary point x. In each step, we move along the circle to a neighbored point – one point to the left with probability 1/2 and one point to the right with probability 1/2. By the very definition, the transition probabilities do not change over time and depend only on the current state, so is a finite Markov chain. If we label the points on the circle by 

More generally, we can also allow the process to stay where it is with probability 1 – p, where p is then the probability to move, which leads us to the matrix

Let us try to figure out whether the target distribution, given by the matrix Kn for large n, somehow converges.
To see this, we do two numerical experiments. First, we can easily simulate a random walk. Suppose that we have a function draw which accepts a distribution (given by a vector p whose elements add up to one) and draws a random value according to that distribution, i.e. it returns 1 with probability p0, 2 with probability p1 and so on. We can then simulate a random walk on the circle as follows.
def simulate_chain(N, p, steps=100, start=5):
chain = []
x = start % N
chain.append(x)
for i in range(steps):
x = (x + draw([p/2.0, 1.0 - p, p / 2.0]) - 2) % N
chain.append(x)
return chain
Here N is the number of points on the circle, steps is the number of simulation steps that we run and start is the starting point. The function draw then returns 1 with probability p/2, 3 with probability p/2 and 2 with probability 1 – p. Thus we move with probability p/2 to the right, with probability p/2 to the left and stay were we are with probability 1 – p. If we set p = 0.8, this results in the following transition matrix.

We can visualize the results if we execute a large number of runs and draw histograms of the resulting positions 100, 200, 300, … steps. The result will look roughly like this (for this image, I have used p = 0.8 and N=10):
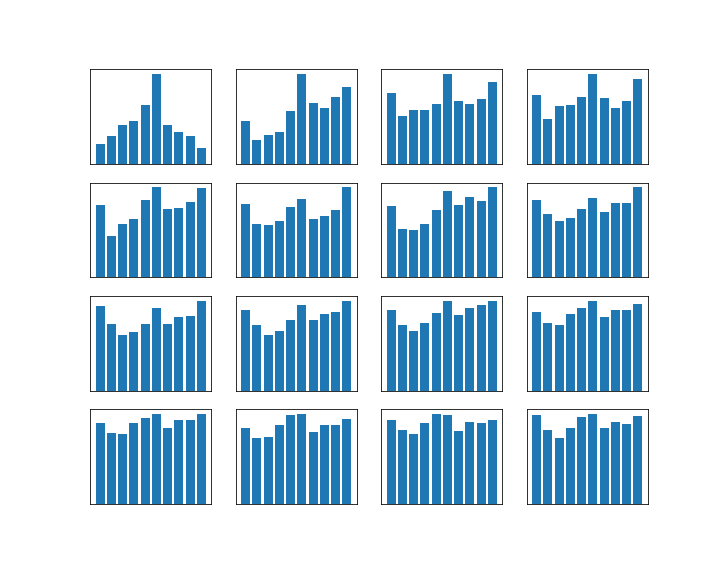
We see that after a few hundred steps, this seems to converge – actually this starts to look very much like a uniform distribution. As we already know that the distribution after n steps is given by the matrix Kn, it makes sense to look at high powers of this matrix as well. To visualize this, I will use a method that I have seen in MacKays excellent book and that works as follows.
Visualizing one row of a matrix is not difficult. We can plot the entries in a two-dimensional diagram, where the x-axis corresponds to the column index and the y-axis corresponds to the value. A flat line is then a row in which all entries have the same value.
To display a full matrix, we use colors – we assign one color to each row index and plot the individual rows as just described. If we do this for the powers of the matrix K with the parameters p = 0.8 and N = 10 (and only chose some rows, for instance 1,4,7, to not run out of colors…) we obtain an image like the one below.
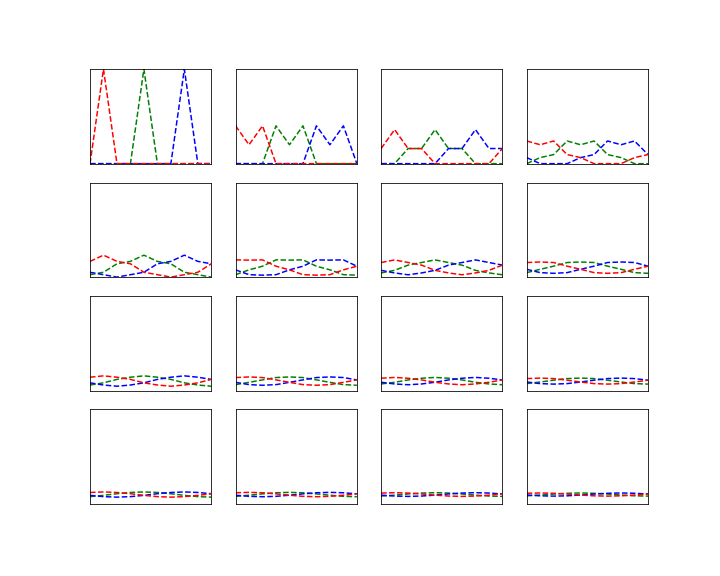
We can clearly see that the powers of the matrix K converge towards a matrix

where all entries in each row seem to have the same value. We have seen that the distribution after n steps assuming an initial distribution described by a row vector 

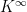
To completes our short introduction into Markov chains. We have seen that Markov chains model stochastic processes in discrete time in which the state at step t+1 depends only on the state at step t and the dependency is given by a function independent of the current time. In finite state spaces, Markov chains are described by a transition matrix K. The i-th row of the matrix Kn is the distribution of chains starting at point i after n steps. Consequently, converge properties of the Markov chains can be related to converge of high powers Kn and the apparatus of linear algebra can be applied.
In the next post, we will learn more about convergence – how it can be made precise, and how we can tell whether a given Markov chain converges. This will then allow us to construct Markov chains that converge towards a given target distribution and use them for sampling.

1 Comment