
Though not really new, a programming model commonly known as asynchronous I/O has been attracting a lot of attention over the last couple of years and even influenced the development of languages like Java, Go or Kotlin. In this and the next few posts, we will take a closer look at this model and how it can be implemented using Python.
What is asynchronous I/O?
The basic ideas of asynchronous I/O are maybe explained best using an example from the world of networking, which is at the same time the area where the approach excels. Suppose you are building a REST gateway that accepts incoming connections and forwards them to a couple of microservices. When a new client connects, you will have to make a connection to a service, send a request, wait for the response and finally deliver the response back to the client.
Doing this, you will most likely have to wait at some points. If, for instance, you build a TCP connection to the target service, this involves a handshake during which you have to wait for network messages from the downstream server. Similarly, when you have established the connection and send the request, it might take some time for the response to arrive. While this entire process is n progress, you will have to maintain some state, for instance the connection to the client which you need at the end to send the reply back.
If you do all this sequentially, your entire gateway will block while a request is being processed – not a good idea. The traditional way to deal with this problem has been to use threads. Every time a new request comes in, you spawn a thread. While you have to wait for the downstream server, this thread will block, and the scheduler (the OS scheduler if you use OS-level threads or some other mechanism) will suspend the thread, yield the CPU to some other thread and thus allow the gateway to serve other requests in the meantime. When the response from the downstream server arrives, the thread is woken up, and, having saved the state, the processing of the client’s request can be completed.
This approach works, but, depending on the implementation, creating and running threads can create significant overhead. In addition to the state, concurrently managing a large number of threads typically involves a lot of scheduling, locking, handling of concurrent memory access and kernel calls. This is why you might try a different implementation that entirely uses user-space mechanism.
You could, for instance, implement some user-space scheduler mechanism. When a connection is being made, you would read the incoming request, send a connection request (a TCP SYN) to the downstream server and then voluntarily return control to the scheduler. The scheduler would then monitor (maybe in a tight polling loop) all currently open network connections to downstream servers. Once the connection is made, it would execute a callback function which triggers the next steps of the processing and send a request to the downstream server. Then, control would be returned to the scheduler which would invoke another callback when the response arrives and so forth.
With this approach, you would still have to store some state, for instance the involved connections, but otherwise the processing would be based on a sequence of individual functions or methods tied together by a central scheduler and a series of callbacks. This is likely to be very efficient, as switching between “threads” only involves an ordinary function call which is much cheaper than a switch between two different threads. In addition, each “thread” would only return control to the scheduler voluntarily, implementing a form of cooperative multitasking, and can not be preempted at unexpected points. This of course makes synchronization much easier and avoids most if not all locking, which again removes some overhead. Thus such a model is likely to be fast and efficient.
On the downside, without support from the used programming language for such a model, you will easily end up with a complex set of small functions and callbacks, sometimes turning into a phenomenon known as callback hell. To avoid this, more and more programming languages offer a programming model which supports this approach with libraries and language primitives, and so does Python.
Coroutines and futures
The model which we have described is not exactly new and has been described many years ago. In this model, processing takes place in a set of coroutines. Coroutines are subroutines or functions which have the ability to deliberately suspend their own execution – a process known as yielding. This will save the current state of the coroutine and return control to some central scheduler. The scheduler can later resume the execution of the coroutine which will pick up the state and continue to run until it either completes or yields again (yes, this is cooperative multitasking, and this is where the name – cooperative routines – comes from).
Coroutines can also wait for the result of a computation which is not yet available. Such a result is encapsulated in an object called a future. If, for instance, a coroutine sends a query to a downstream server, it would send the HTTP request over the network, create a future representing the reply and then yield and wait for the completion of this future. Thus the scheduler would gain back control and could run other coroutines. At the same time, the scheduler would have to monitor open network connections, and, when the response arrives, complete the future, i.e. provide a value, and reschedule the corresponding coroutine.
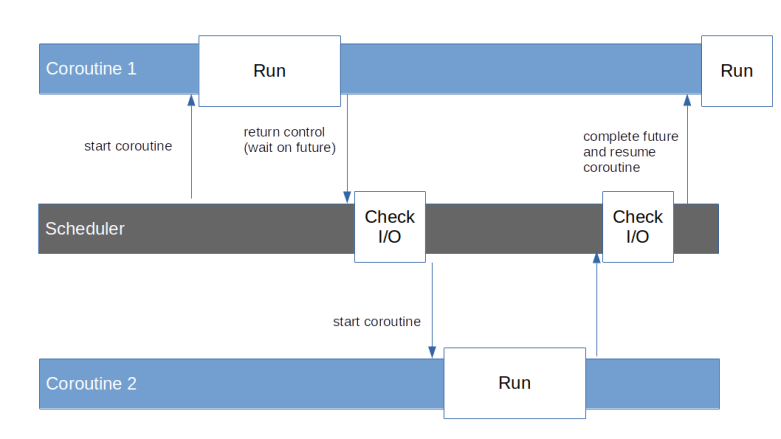
Finally, some additional features would be desirable. To support modularization, it would be nice if coroutines could somehow call each other, i.e. if a coroutine could delegate a part of its work to another coroutine and wait for its completion. We would probably also want to see some model of exception handling. If, for instance, a coroutine has made a request and the response signals an error, we would like to see a way how the coroutine learns about this error by being woken up with an exception. And finally, being able to pass data into an already running coroutines could be beneficial. We will later see that the programming model that Python implements for coroutines supports all of these features.
Organisation of this series
Coroutines in Python have a long history – they started as support for iterators, involved into what is today known as generator-based coroutines and finally turned into the native coroutines that Python supports today. In addition, the asyncio library provides a framework to schedule coroutines and integrate them with asynchronous I/O operations.
Even today, the implementation of coroutines in Python is still internally based on iterators and generators, and therefore it is still helpful to understands these concepts, even if we are mainly interested in the “modern” native coroutines. To reflect this, the remaining posts in this series will cover the following topics.
- Iterators and generator-based coroutines
- Native coroutines
- The main building blocks of the low-level asyncio API – tasks, futures and the event loop
- Asynchronous I/O and servers
- Building an asynchronous HTTP server from scratch
To follow the programming examples, you will need a comparatively new version of Python, specifically you will need Python 3.7 or above. In case you have an older version, either get the latest version from the Python download page and build it from source, or (easier) try to get a more recent package for your OS (for Ubuntu, for instance, there is the deadsnake PPA that you can use for that purpose).
