Modern operating systems are mostly event driven – network cards receive packets, users hit keys or a mouse buttons, built-in timer create events or data arrives from a hard drive. To be able to process these events, a CPU needs a mechanism to stop whatever it is currently doing and run some code designed to deal with the event – and this is what is called an interrupt.
How do interrupts work?
Formally speaking, we could define an interrupt as an event that instructs the CPU to stop the current flow of processing, jump to a defined location in memory, execute the instructions there and later, when that stream of instructions is complete, resume processing at the point where it left of.
To understand how this works, let us briefly recall some basic concepts in CPU design. First, remember that a CPU has – apart from other units – a certain set of registers, i.e. a set of easily accessible, but small pieces of memory that the CPU uses to store intermediate results of a calculation. To be a bit more specific, let us assume that we talk about an x86 CPU in protected mode. Then there are registers called EAX, EBC, ECD and EDX (and many others) that can hold 4 bytes, i.e. 32 bits, each. Instructions like the ADD command can refer to these register and, for instance, add the content of two registers and store the result in a third register.
In addition to these general purpose registers, there are a few other special registers. One of them is the register called EIP which is the instruction pointer – it points to the memory location where the instruction just executed is stored. And there is the stack pointer ESP, which points to the bottom of the stack, i.e. to an area of memory which a program can use to temporarily store data. When a program pushes data on the stack, the stack pointer is decremented, i.e. the stack grows downwards, and the data it is written to the memory location to which the stack pointer then refers. If a program pops data from the stack, the data is taken from the memory location to which the stack pointer currently refers, and the stack pointer is incremented again.
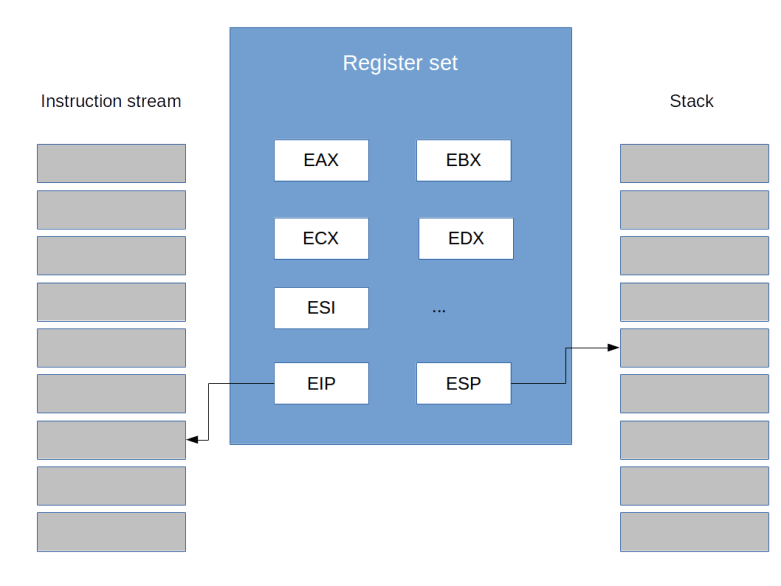
When instructions are executed one by one, the instruction pointer is simply increased after the processing of one instruction has been completed to point to the next instruction. However, when a program uses the CALL instruction to call a subroutine, the CPU will have to continue execution not at the next instruction, but at the start of the subroutine. When the subroutine completes, however, it needs to resume processing at the next instruction after the CALL instruction. So it has to save this address – called the return address – somewhere.
As there is only a small set of registers available and we might want to do nested calls, the CPU cannot use a register for this purpose, so it uses the stack. Thus, if we call a subroutine, the return address is pushed onto the stack. When the subroutine has completed, a special instruction called RET is placed in the code. This instruction tells the CPU to get the return address from the stack and resume execution at this point.
By now, you might be asking yourself why I am telling you all this. The answer is simple – interrupts work in a very similar way. In fact, when an interrupt is raised (we will see further below what this actually means), the CPU places the current value of the EIP register on the stack. It then jumps to a predefined point in memory and processes the instructions there, called the interrupt service handler (ISR). Once the ISR completes, it needs to execute a command called IRET. This command will instruct the CPU to take the stored value of EIP from the stack and reload it. Thus, the CPU will resume execution of the current program after the instruction during which the interrupt was generated.
This simple description glossed over a few details. First, interrupts are numbered, i.e. there is not only one interrupt, but in fact there are 256 so-called interrupt vectors. When an interrupt is raised, the CPU uses the interrupt vector to look up the address of the interrupt service handler in a table called the interrupt descriptor table (IDT). Thus an operating system needs to set up interrupt service handlers for all these 256 possible vectors and populate the IDT accordingly.
Second, the CPU does not only store the value of EIP on the stack, but some additional information like an error code. If you are interested in the details, you can find a description of the precise stack layout in the ctOS documentation.
And finally, an interrupt might in addition cause a change of privileges – we will learn more about this when we discuss the protected mode in one of the future posts.
Note that the CPU does not automatically place all other registers like EAX on the stack, so the interrupt service handler needs to make sure that these registers are restored to their original state before the ISR returns, otherwise the running program will continue execution with a corrupted register set (but an operating system can use this to on purpose change the values of the registers of a running program).
Sources of interrupts and interrupt routing
Now where do interrupts really come from? Basically, there are three sources of interrupts.
First, there are hardware interrupts. These are interrupts that are caused by hardware external to the CPU. An example could be a keyboard that uses an interrupt to signal that the user has pressed a key, or a timer that is programmed to generate specific interrupts periodically. We will see below how these interrupts are used in an operating system kernel.
Second, there are software interrupts. These can be exceptions or faults, i.e. interrupts that are raised by the CPU to signal some sort of error condition, like the attempt to divide by zero or a general protection fault. But software interrupts can also be raised by a program on purpose using the INT instruction.
The exact mechanism how a hardware interrupt travels from a peripheral device to the CPU is one of the most complicated and bloated areas of the PC architecture. In most cases, there is an additional piece of hardware sitting between a device and the CPU that is responsible for handling this communication and is called the interrupt controller. The first IBM compatible PCs had an interrupt controller called the PIC that was able to handle eight different hardware interrupts. However, with an increasing number of devices, this soon turned out to be not sufficient, so a second interrupt controller was cascaded with the first one to be able to manage sixteen interrupts. This itself was made a bit more complicated than it sounds by the fact that at this time, two bus systems were around – the new PCI bus and the old ISA bus – and that the interrupt routing could be programmed by the BIOS using the so-called programmable interrupt router (PIR). So we already had a bit of a complex setup, as indicated in the diagram below.
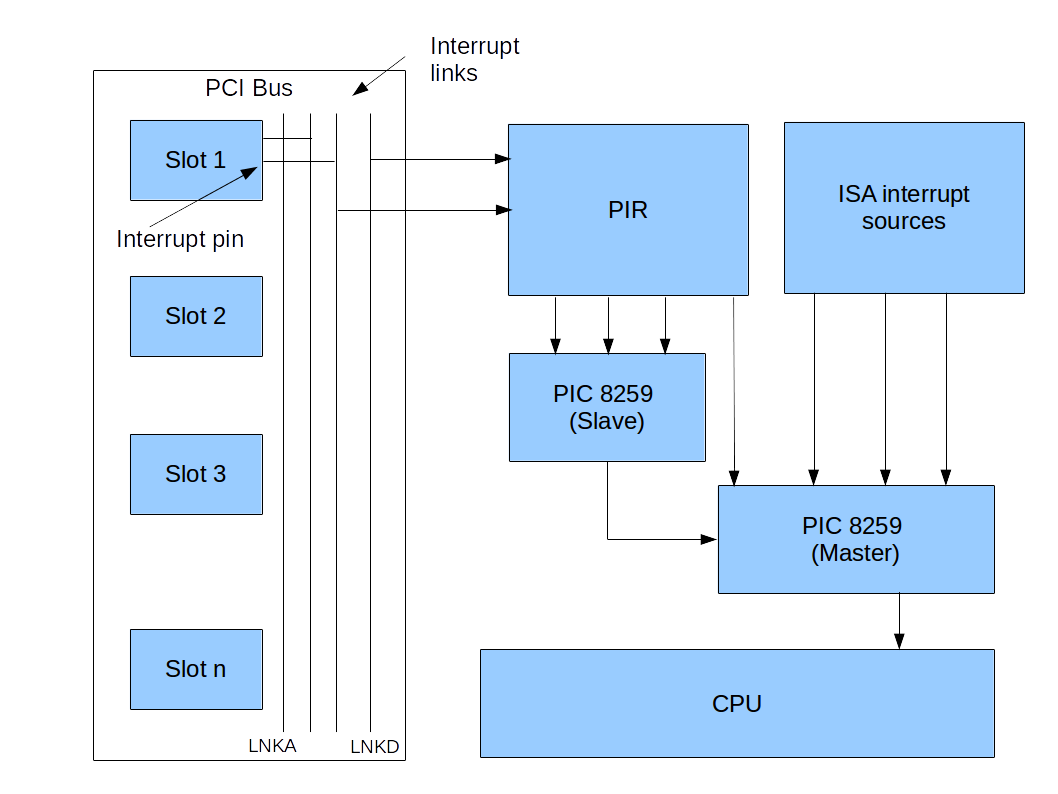
Then the first PCs started to have more than one CPU, and a more flexible mechanism was invented – the APIC. Unfortunately, the old interrupt controller was still around and could be used, making for a very complex configuration mechanism. And finally, newer devices use a mechanism called MSI that avoids an interrupt controller almost completely. If you want to read up the full story, again the ctOS documentation has all the nitty-gritty details.
Where are interrupts used?
I started this post with the bold claim that interrupts are the heartbeat of a modern operating system kernel – so let me try to justify this statement.
First, let us think about how a CPU would typically communicate with the hardware. Take a very simple example – user input. Of course, in a dialogue driven programming style, things are simple. You would print something to the screen and then wait for user input. More specifically, you would periodically, maybe within every few microseconds, ask the keyboard controller for any new data that has arrived.
Such a design is simple, but has a major disadvantage: while you are actively waiting (polling in the language of computer scientists) for input, you consume CPU time and the CPU cannot do anything else. This is not a major problem for a home computer operating system of the early eighties, but turns into a problem when you want to support multi-tasking or even multi-user capabilities.
Interrupts offer a way out. Instead of sitting in a loop and polling for new data every few thousand iterations, the CPU can hand over control to another task which is currently not expecting user input and can let the keyboard controller fire an interrupt if the user presses (or releases) a key. The interrupt service handler can then inspect the input and either put it into a buffer for later processing or initiate a task switch back to the program waiting for the input (we will look in more detail into the exact mechanics of a task switch in a later post).
A similar mechanism can be used for other input/output related processing. If, for instance, we want to read data from the hard disk, we can apply a procedure called direct memory access (DMA). With DMA, the CPU would ask the hard disk controller to load one or more sectors from the disk and then continue to work on other tasks. The controller would – in the background – read the data from the disk and transfer it into a designated area of the systems main memory. Once the transfer is complete, it would inform the CPU by raising an interrupt. The CPU could then, again in an interrupt service handler, get the data and process it further. Similar mechanism apply for networking – incoming packets can trigger interrupts, or an interrupt could signal to the CPU that the network controller is ready to send out data.
But interrupts are not only useful for I/O related tasks – they are also a major ingredient for the implementation of multi-tasking. In fact, the very first multi-tasking systems used for home PCs where based on a design called cooperative multi-tasking. With that design, a task would actively return control to the operating system after executing some time to allow other processes to run. You might want to compare this to a group of people on a hot summer day sharing a bottle of water. When everybody cooperates and passes on the bottle after a few sips, this works fine. But things go wrong if someone – for whatever reasons – just keeps on drinking until the bottle is empty. Translated back to the world of operating systems, this design allows a single process to consume the entire CPU time, so that no other process can execute any more, for instance because it is stuck in an infinite loop due to a programming error – the machine will appear to hang. Those of you who have still seens Windows 3.11 that uses this design know what I am talking about.
A more advanced design can be realized using interrupts. A modern PC does for instance have a timer that creates interrupts at a defined frequency, say 1000 Hz, i.e. one interrupt every millisecond. If the interrupt service routine triggered by the timer is performing a task switch, it is made sure that even if a process hangs, control will be returned to the operating system and potentially to a different process after at most one millisecond. This design is called preemptive multitasking because the task switch is not actively initiated by the currently running process, but the process is interrupted (preeempted) by the ISR and the operating system.
And there are even more applications that are worth being mentioned – you can use interrupts for debugging, several CPU cores can use special interrupts to communicate with each other and a thermal sensor can use an interrupt to let the CPU know that a certain temperature has been exceeded. In fact, in an operating system kernel, a lot of processing is done in an interrupt service handler, like dealing with hardware interrupts, scheduling a new task and handling signals – see the overview of the interrupt processing in ctOS below to get an idea.
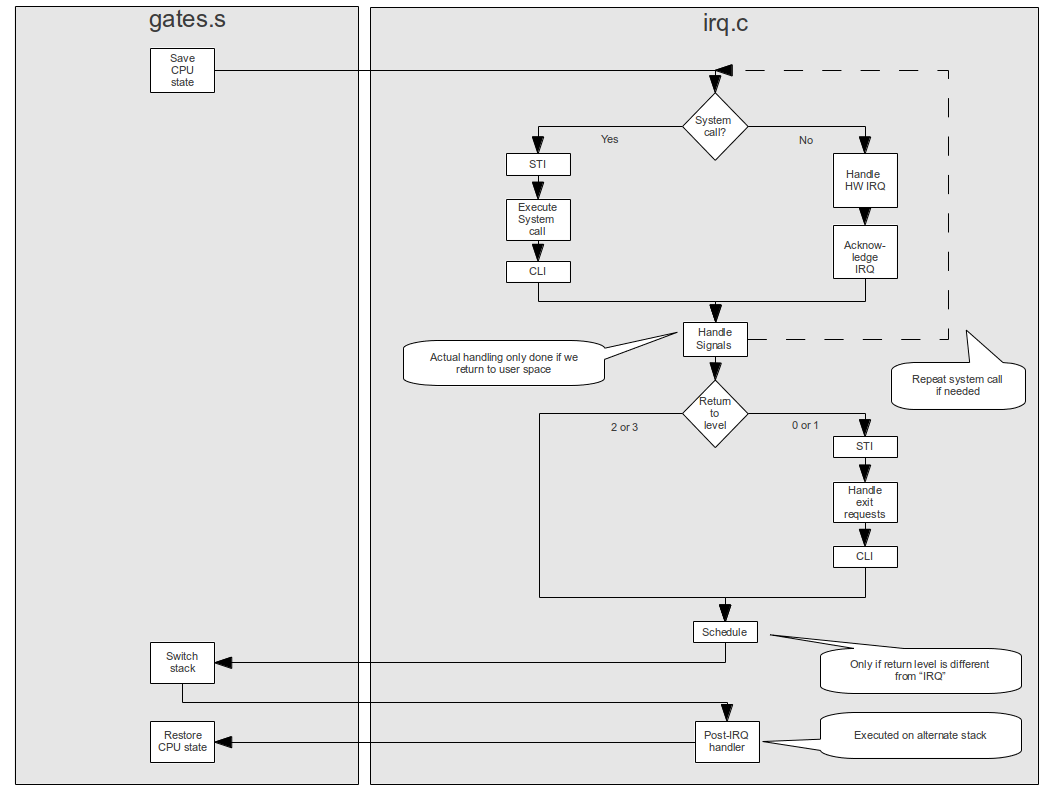
There is one more point that we have ignored so far – interrupts can be used to switch back between kernel space and user space, or between ring 3 and ring 0 of a CPU. However, explaining this requires a basic understanding of the protected mode, so we will leave this for a later post.
