
Suppose you are given a long file and wanted to use hashing to verify the integrity of the file. How would you do this in the most efficient way?
Of course, the first thing that might come to your mind is to simply take a hash of the entire file. This is very easy, but has one major disadvantage – if the file is damaged, there is no way to tell which part of the file has been damaged. If you use such a mechanism for instance to verify the integrity of a large download, you will have to go back and download the entire file again, which is very time consuming.
A smarter approach is to split the file into data blocks. You then calculate a hash for each data block to obtain a hash list. Finally, you could concatenate all the hashes into one large string and take the hash of that string. If a recipient of the file has access to only this top level hash, she could already verify the integrity of the file by repeating this procedure and comparing the top level hash with the hash created by the sender.
If that check fails, there is no need to re-transmit the entire file. Instead, the recipient could obtain a copy of the hash list itself and compare the hashes block by block until the faulty block is detected. This block can then be exchanged and the procedure can be repeated to verify that the replacement is valid. The bittorrent protocol uses this mechanism to detect inconsistencies in transferred files.
With a simple hash list like this, you would have to search the entire hash list in order to determine the faulty piece, requiring a time linear in the number of blocks. Searching can be improved greatly by organizing the hashes not into a list, but into a (binary) tree – and this data structure is called a hash tree or Merkle tree.
To illustrate the principle, suppose you wanted to build a hash tree for a file consisting of eight blocks, labeled 1 – 8.
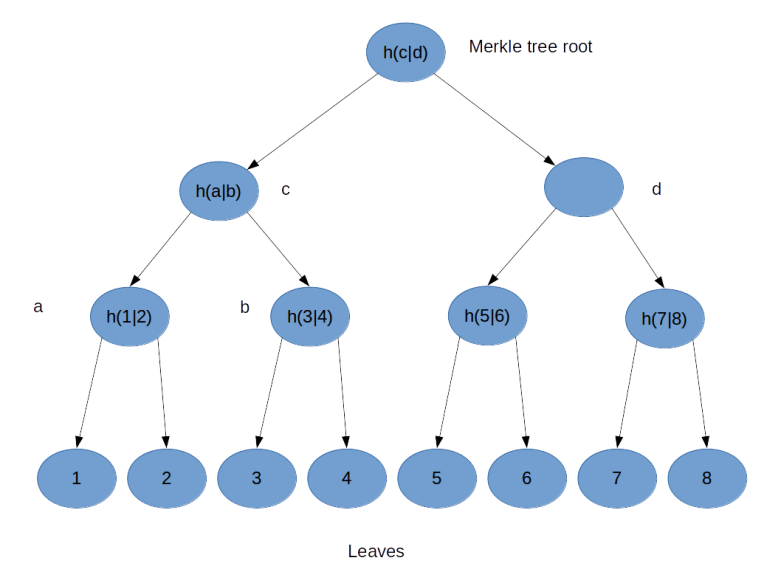
You would then proceed as follows, as indicated in the image above. First, you compute the hash value for all blocks and assign them as values to the eight leaves of the tree. Then, you concatenate the values of leaves 1 and 2 and take the hash value of the result. This gives you the value for the parent node – called a in the picture above – of 1 and 2. You repeat the same procedure for the leaves 3 and 4, this gives you the value for the node b. Then you concatenate the values of a and b and take the hash value of the result, this gives you the value of the node c. Repeat this procedure for the right part of the tree and assign the result to node d. Finally, concatenate the values of node c and d and take the hash – this will be the value of the root node called the Merkle root. Thus, in a binary Merkle tree, the value of each node is defined to be the hash of the concatenation of the values of its two child nodes.
How is a Merkle tree realised in the bitcoin reference implementation? The currently relevant code is in consensus/merkle.cpp. This implementation is already optimized, the original implementation used to be in primitives/block.cpp and is still available on GitHub.
As the comments in the source code explain, at any level of the tree, the last node is added at the end again if needed to make sure that the number of nodes is even at each level – the algorithm that I have illustrated above only works if the number of leaves is a power of two. The actual implementation first builds a list of the leaves. It then goes through the list and for any two subsequent elements, it adds an element at the end which is the hash of the concatenation of these two elements. The last element is then the Merkle root that we are looking for.
Let us now see how a straightforward implementation looks like in Python.
Most of the code should be self explaining, but a few remarks are in order. First, the hash function that we use could of course by any hash function, but, to be consistent with what bitcoin is doing, we use a double SHA256 hash. Then, byte ordering is again to be observed. The bitcoin reference client uses the method GetHash() on the involved transactions to populate the leaves, and we know that this is providing the transaction ID in little endian byte order. The entire calculation then proceeds in little endian byte order. The JSON output, however, display the transaction IDs in big endian order and the same holds for the Merkle root. Thus we need to reverse the byte order before we build the tree and, when comparing our result with the Merkle root which is part of the block, reverse the byte order again.
The actual calculation of the Merkle root uses a very straightforward approach – instead of maintaining one long list as the original bitcoin reference representation did, we represent the nodes at each level of the tree by a separate list and use recursion. This is probably a bit less efficient, but maybe easier to understand.
In order to test our implementation, we finally use the Python requests library to get a block in JSON format from blockchain.info using their REST API. We then build the leaves of the tree by walking through the list of transaction IDs in the block, build the Merkle root and compare the result to the value which is part of the JSON block structure. Nice to see that they match!
What happens if a client wants to verify that a given transaction is really included in a block without downloading the full block? In this case, it can ask the bitcoin server (either via the RPC call gettxoutproof or as part of the GETDATA network message) to provide a Merkle block, which is a serialized instance of CMerkleBlock. Essentially, a Merkle block consists of a block header plus a branch of the Merkle tree that is required to verify that a specific transaction is part of the block. This eliminates the need to transfer all transactions (which can be several thousand) while still allowing the client to check that a transaction is really included in a block.
This completes our short discussion of Merkle trees. We are now able to calculate the Merkle root for inclusion in a block header given the list of transactions that a block contains. To be able to mine a block, there is one more thing that we need to understand and that we will cover in the next post in this series – mining difficulty and the proof-of-work target.
