
Over the last couple of months, a usage pattern for large language models that leverages the model for decision making has become popular in the LLM community. Today, we will take a closer look at how this approach is implemented in two frameworks – Langchain and AutoGPT.
One of the most common traditional use cases in the field of artificial intelligence is to implement an agent that operates autonomously in an environment to achieve a goal. Suppose, for instance, that you want to implement an autonomous agent for banking that is integrated into an online banking platform. This agent would communicate with an environment, consisting of the end user, but maybe also backend systems of the bank that would allow it to gather information, for instance on account balances, and to trigger transactions. The goal of the agent would be to complete a customer request.
In a more abstract setting, an agent operates in discrete time steps. At each time step, it receives an observation – which, in the example above, could be a user input or the result of a call into the backend system – and can decide to take one out of a list of available actions, like making a new request to a backend system or completing the conversation with the end user – a formalism that you will have seen before if you have ever studied reinforcement learning. So the task of the agent is to select the next action, depending on the current and potentially on previous observations.
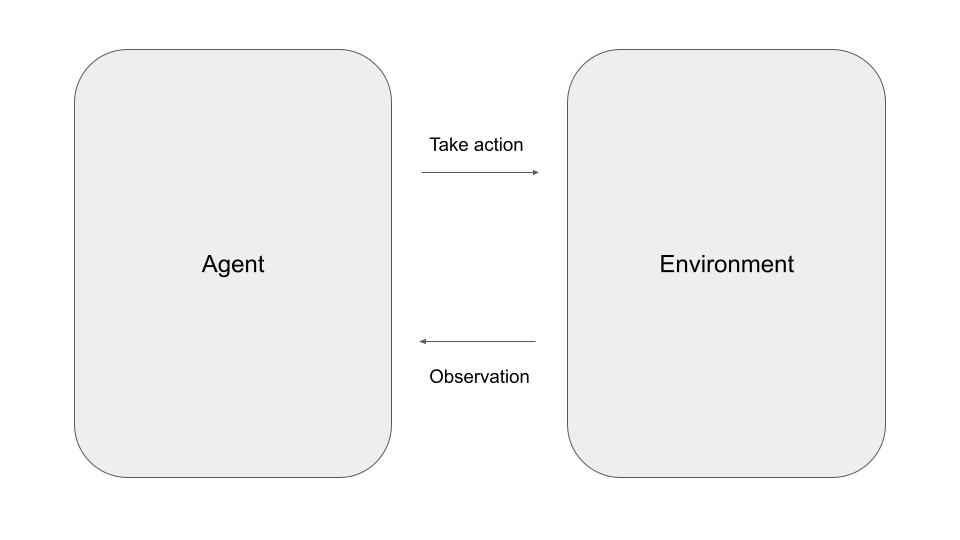
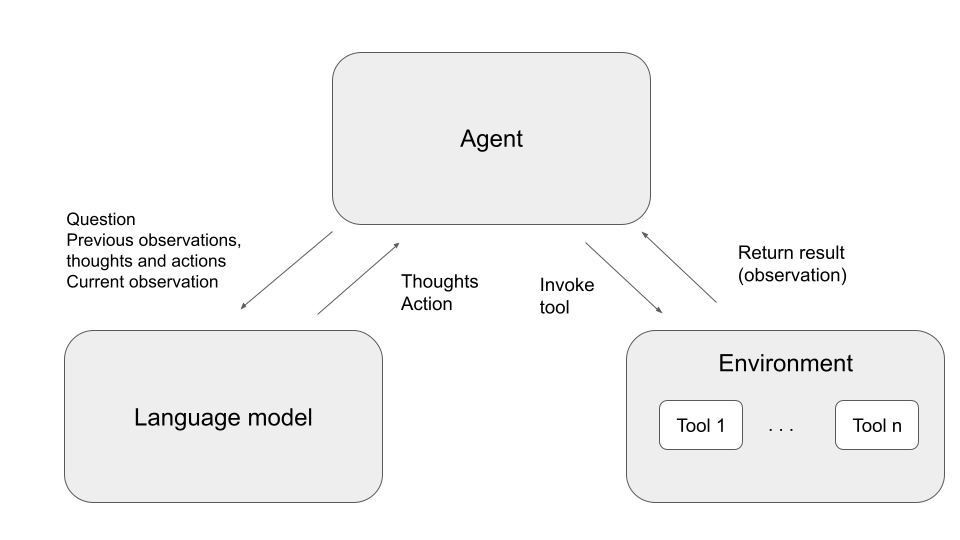
Obviously, there are many different possibilities to implement an agent – and, maybe not surprisingly, one approach that has been applied successfully in the recent past is to use a large language model as the brain of our agent. The idea behind this approach is to feed the observations, encoded as plain text, into the model at each step and to ask the model for the next action to take.
In practice, this can be done using few-shot learning, i.e. we generate a prompt for our model that consists of a few examples that inform the model about the format that we expect and the possible actions, and then add the last actual observation as a final prompt. To allow our model to take all previous observations into account, we would always include the full trajectory of observations and actions into the model.
In this paper, an approach termed ReACT (Reasoning and acting) has been proposed to orchestrate a large language model for decision making. In this framework, the environment is modelled as a set of tools that the agent can utilize. In the original paper, there are actually three tools corresponding to three different actions that the agent can take. First, it can retrieve a summary from Wikipedia. Second, it can lookup details on the Wikipedia page to which it has navigated with the first action, and finally it can complete the task and return the final result.
In each step, the agent now asks the model what action it should take next. It then runs one of the available tools to execute the action and adds the result as new observation to the next prompt that it sends to the model. To improve the quality of the results, a prompt engineering technique known as chain-of-thought prompting (CoT) is used, which basically means that the prompt contains an instruction for the model to spell out its thoughts, i.e. the rationale for the proposed action. Thus each prompt consists of the original question to be answered and the full history of thoughts, actions and observations.
Here is an example generated by the Langchain implementation of an agent following the ReACT pattern. For a better understanding, I have marked the output of the model in italic.
Question: Out of the following three countries, only two are direct neighbors of France: Germany, Spain, Poland. Please name the country in the list which is not a neighbor of France
Thought: I need to search France, find its neighbors, then find the country in the list which is not a neighbor of France
Observation: France, officially the French republic, is a country located primarily … (long summary of the Wikipedia artice on France)
Thought: France has neighbors such as Germany, Spain, Belgium, Luxemburg, Switzerland, Italy, Monaco, Andorra and the United Kingdom. So the country in the list which is not a neighbor of France is Poland.
Action: Finish[Poland]
To encourage the model to follow this pattern and to use only the allowed actions, the Langchain implementation uses few-shot learning, i.e. the prompt contains a few examples that follows this scheme (you can find these examples here, these are actually the examples cited in the original paper). So the full prompt consists of the few-shot examples, followed by the question at hand and the full sequence of observations, thoughts and actions generated so far.
Let us take a short look at the implementation in Langchain. These notes have been compiled using version 0.202. As the toolset seems to be evolving quickly, some of this might be outdated when you read this post, but I am confident that the basic ideas will remain.
First, Langchain distinguishes between an agent which is the entity talking to the language model, and the agent executor which talks to the agent and runs the tools.
The AgentExecutor class implements the main loop indicated in the diagram above. In each iteration, the method _take_next_step first invokes the agent, which will in turn assemble a prompt as explained above and generate a response from the language model. The output is then parsed and returned as an AgentAction which also contains the thought that the model has emitted. Then, the tool which corresponds to the action is executed and its output is returned along with the selected action.
Back in the main loop, we first test whether the action is an instance of the special type AgentFinish which indicates that the task is completed and we should exit the main loop. If not, we append the new tuple consisting of thought, action and observation to the history and run the next iteration of the loop. The code is actually quite readable, and I highly recommend to clone the repository and spend a few minutes reading through it.
Let us now compare this to what AutoGPT is doing. In its essence, AutoGPT uses the same pattern, but there are a few notable differences (again, AutoGPT seems to be under heavy development, at the time of writing, version 0.4.0 is the stable version and this is the version that I have used).
Similar to the ReACT agent in Langchain, AutoGPT implements an agent that interacts with an LLM and a set of tools – called commands in AutoGPT – inside a main loop. In each iteration, the agent communicates with the AI by invoking the function chat_with_ai. This function assembles a prompt and generates a reply, using the OpenAI API in the background to talk to the selected model. Then, the next action is determined based on the output of the model and executed (in the default settings, the user is asked to confirm this action before running it). Finally the results are added to the history and the next iteration starts.
The first difference compared to the ReACT agent in Langchain is how the prompt is structured. The prompt used by AutoGPT consists of three sections. First, there is a system prompt which defines a persona, i.e. it instructs the model to embody an agent aiming to achieve a certain set of goals (which are actually generated via a separate invocation of the model initially and saved in a file for later runs) and contains further instructions on the model. In particular, the system prompt instructs the model to produce output in JSON format as indicated below.
{
"thoughts": {
"text": "thought",
"reasoning": "reasoning",
"plan": "- short bulleted- list that conveys- long-term plan",
"criticism": "constructive self-criticism",
"speak": "thoughts summary to say to user"
},
"command": {
"name": "command name",
"args": {
"arg name": "value"
}
}
}
This is not only much more structured than the simple scheme used in the ReACT agent, but also asks the model to express its thoughts in a specific way. The model is asked to provide additional reasoning, to maintain a long-term plan as opposed to simply deciding on the next action to take and to perform self-criticism. Note that in contrast to ReACT, this is pure zero-shot learning, i.e. no examples are provided.
After the system prompt, the AutoGPT prompt contains the conversation history and finally there is a trigger prompt which is simply hardcoded to be “Determine exactly one command to use, and respond using the JSON schema specified previously:“.
Apart from the much more complex prompt using personas and a more sophisticated chain-of-thought prompting, a second difference is the implementation of an additional memory. The idea behind this is that for longer conversations, we will soon reach a point where the full history does not fit into the context any more (or it does, but we do not want to do this as the cost charged for the OpenAI API depends on the number of token). To solve this, AutoGPT adds a memory implemented by some external data store (at the time of writing, the memory system of AutoGPT is undergoing a major rewrite, so what follows is based on an analysis of earlier versions and a few assumptions).
The memory is used in two different places. First, when an iteration has been completed, an embedding vector is calculated for the results of the step, i.e. the reply of the model and the result of the executed command. The result is then stored in an external datastore, which can be as simple as a file on the local file system, but can also be a cache like Redis, and indexed using the embedding.
When an iteration is started, the agent uses an embedding calculated from the last few messages in the conversation to look up the most relevant data in memory, i.e. the results of previous iterations that have the most similar embeddings. These results are then added to the prompt, which gives the model the ability to remember previous outcomes and reuse them in a way not limited by the length of the prompt. This approach of enriching the prompt with relevant information obtained via a semantic search is sometimes called retrieval augmentation – note however that in this case, the information in the data store has been generated by model and agent, while retrieval augmentation usually leverages pre-collected data.

Finally, the AutoGPT agent can choose from a much larger variety of tools (i.e. commands in the AutoGPT terminology) than the simple ReACT agent which only had access to Wikipedia. On the master branch, there are currently commands to run arbitrary Python code, to read and write files, to clone GitHub repository, to invoke other AIs like DALL-E to generate images, to search Google or to even browse the web using Selenium. AutoGPT can also use Elevenlabs API to convert model output to speech.
AutoGPT and ReACT are not the only shows in town – there is for instance BabyAGI that lets several agents work on a list of tasks which are constantly processed, re-prioritized and amended. Similarly, HuggingGPT [7] initially creates a task list that is then processed, instead of deciding on the next action step by step (AutoGPT is an interesting mix between these approaches, as it has a concrete action for the next step, but maintains a global plan as part of its thoughts). It is more than likely that we will see a rapid development of similar approaches over the next couple of months. However, when you spend some time with these tools, you might have realized that this approach comes with a few challenges (see also the HuggingGPT paper [7] for a discussion).
First, there is the matter of cost. Currently, OpenAI charges 6 cent per 1K token for its largest GPT-4 model (and this is only the input token). If you consume the full 32K context size, this will already be 2$ per turn, so if you let AutoGPT run fully autonomously, it could easily spend an amount that hurts in a comparatively short time.
Second, if the model starts to hallucinate or to repeat itself, we can easily follow a trajectory of actions that takes us nowhere or end up in a loop. This has already been observed in the original ReACT paper, and I had a similar experience with AutoGPT – asking for a list of places in France to visit, the agent started to gather more and more detailed information and completely missed the point where I would have been happy to get an answer compiled out of the information that it already had.
Last but not least the use of autonomous agents that execute Python code, access files on your local system, browse the web using your browser and your IP address or even send mails and trigger transactions on your behalf can soon turn into a nightmare in terms of security, especially given that the output of commands ends up in the next prompt (yes, there is something like a prompt injection, see [8] and [9]). Clearly, a set of precautions is needed to make sure that the model does not perform harmful or dangerous actions ([6] provides an example where AutoGPT was starting to install updated SSL certificates to solve a task that a straight-forward web scraping could have solved as well).
Still, despite of all this, autonomous agents built on top of large language models are clearly a very promising approach and I expect to see more powerful, but also more stable and reliable solutions being pushed into the community very soon. Unitl then, you might want to read some of the references that I have assembled that discuss advanced prompting techniques and autonomous agents in more details.
References:
[1] S. Yao et al., ReAct: Synergizing Reasoning and Acting in Language Models, arXiv:2210.03629
[2] Prompt Engineering guide at https://www.promptingguide.ai/
[3] N. Shinn et al., Reflexion: Language Agents with Verbal Reinforcement Learning, arXiv:2303.11366
[4] L. Wang et al., Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models, arXiv:2305.04091
[5] Ask Marvin – integrate AI into your codebase
[6] https://www.linkedin.com/pulse/auto-gpt-promise-versus-reality-rick-molony – an interesting experience with AutoGPT
[7] Y. Shen, HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face, arXiv:2303.17580 – also known as JARVIS
[8] C. Anderson, https://www.linkedin.com/pulse/newly-discovered-prompt-injection-tactic-threatens-large-anderson/
[9] OWASP Top 10 for LLM Security

Great insights into the implementation of large language models for decision making! It’s fascinating to see how frameworks like Langchain and AutoGPT are utilizing these models to drive autonomous agents. Exciting developments in the field! This article provides a detailed overview of the implementation process, highlighting the different approaches and discussing potential challenges.
Please support our blog https://balancethylife.com
LikeLike